






今天在打开pyspark的时候,出现了两个错误,如图
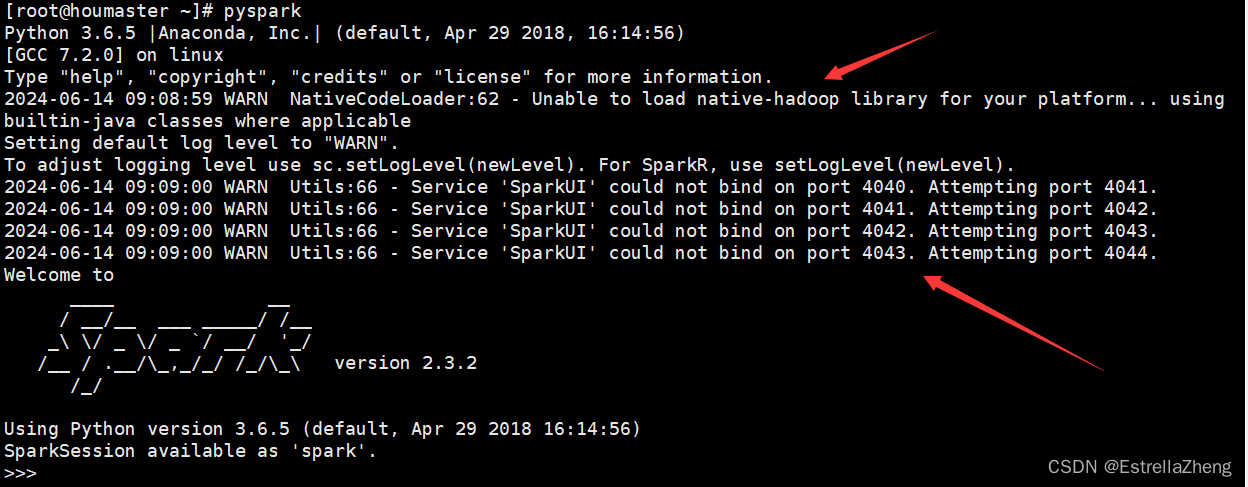
先来看第一个,查看了网上很多文章,说是“hadoop不能加载本地的库”,一个原因是因为Linux和Hadoop安装包不兼容。另一个是在spark中“Hadoop_HOME”缺少设置
首先查看本机的配置,进入spark下的sbin,查看虚拟机是64位
uname -r
然后,查看Hadoop不大配置,进入hadoop下的native,查看Hadoop版本也为64位
file libhadoop.so.1.0.0
再查看所依赖库的版本(注意查看的位置不相同,不在一个目录下)
ldd libhadoop.so.1.0.0
ldd --version
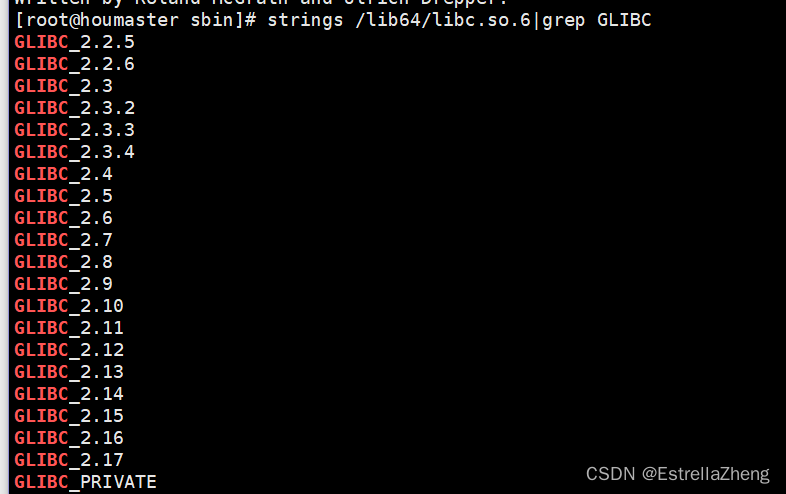
strings /lib64/libc.so.6|grep GLIBC
GLIBC_2.14的版本并未找到,确认下glibc的系统库的版本

查看一下GLIBC所支持的版本,包含我们的版本(若没有包含,可查看Hadoop问题解决:WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable - 柴高八斗 - 博客园 (cnblogs.com)解决)
如此看来,并不是两个不兼容所导致的,接下来查看另一个原因,打开spark的conf目录下,在spark-env.sh文件中加入LD_LIBRARY_PATH环境变量
LD_LIBRARY_PATH=$HADOOP_HOME/lib/native 修改spark-env.sh.template名为spark-env.sh
添加环境变量,保存

再次启动pyspark进行查看,第一个问题已经解决了,只剩下第二个问题了
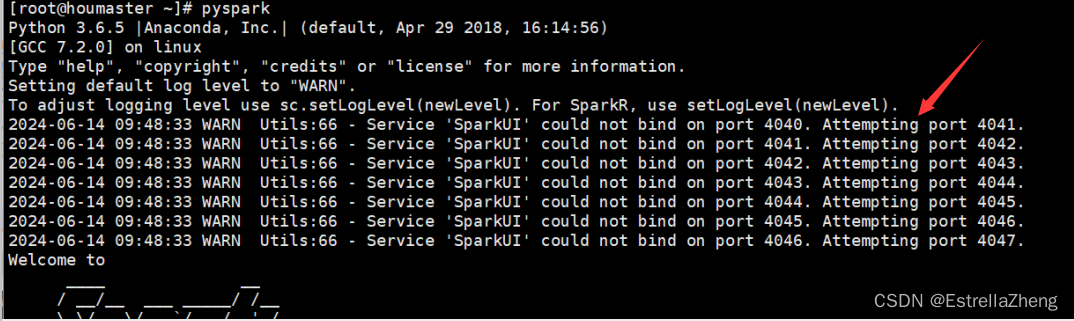
查看之后,发现配置文件出错了,前面有#,没有生效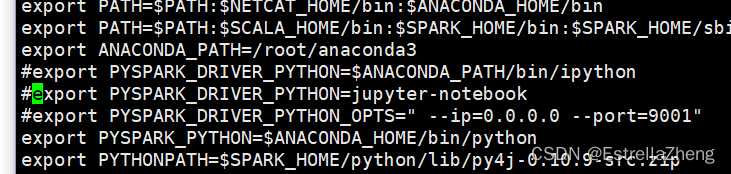
配置文件生效

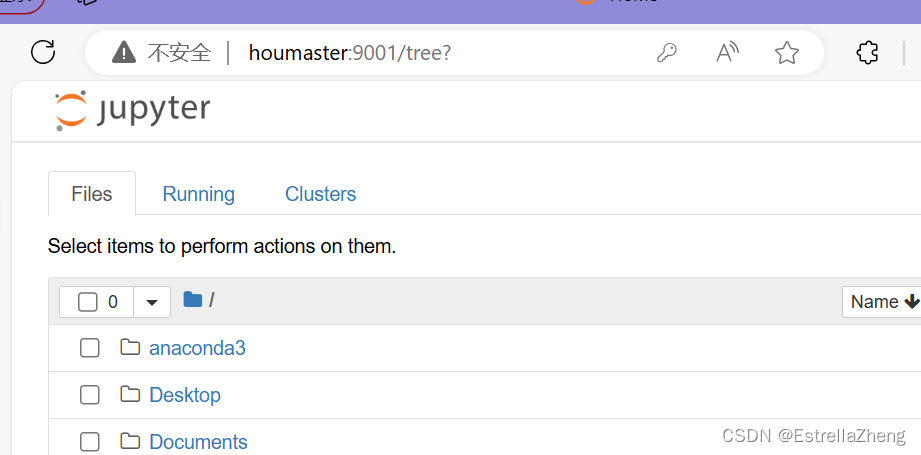
再启动pyspark成功



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









