






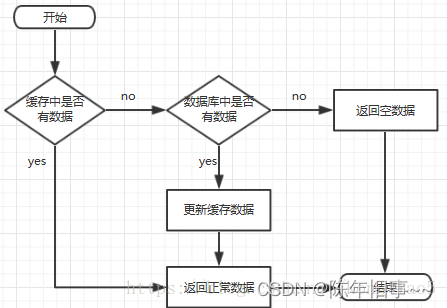
一、缓存处理的流程
当前台请求数据时,后台就会先从缓存中读取数据,如果取到数据就会直接返回结果,而取不到时则会去数据库中读取相应数据,并加载进缓存返回结果,如果数据库也未读取到相应数据,则直接返回空结果。
二、缓存穿透
问题描述:
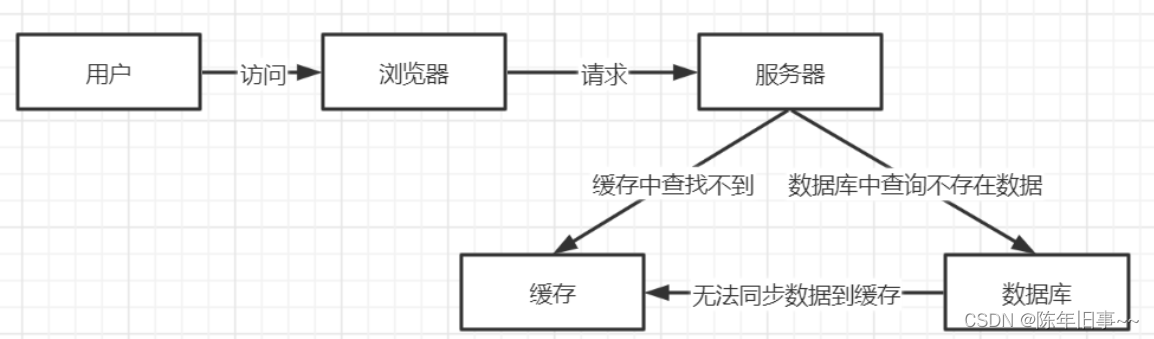
当一个用户查询数据,先到缓存中查发现没有,又到数据库中去查,发现也没有,本次查询失败。如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,此时黑客便可以利用此漏洞不断访问该id,造成数据库崩溃。
解决方案:
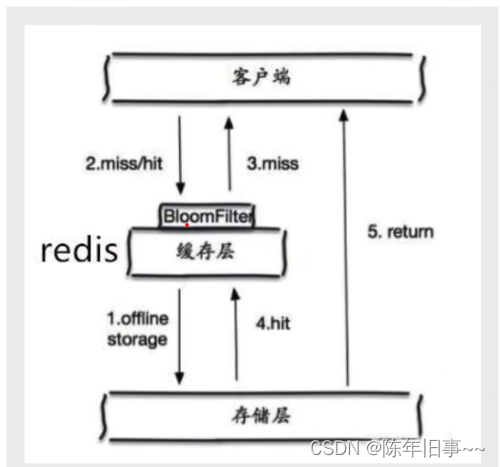
- 布隆过滤器:
布隆过滤器是一种数据结构,对所有可能查询的参数以hash形式存储,在控制层先进行校验,不符合就丢弃,可以避免底层存储系统有过大压力,他的优点是空间效率和查询时间都比一般算法快,缺点是有一定的误识别率和删除困难。
- 缓存空值:
当查询数据的结果为空时,不管其存不存在,都对该空结果进行缓存,并设置一个较短的过期时间,这样可以防止攻击用户反复用同一个id暴力攻击
三、缓存击穿
问题描述:
是指缓存中没有但数据库中有的数据(一般是缓存时间到期),如双十一抢购,这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。
解决方案:
-
加互斥锁:
分布式锁:使用分布式锁,保证对于每个key同时只有一一个线程去查询后端服务,其他线程没有获得分布式锁的权限,因此只需要等待即可。这种方式将高并发的压力转移到了分布式锁,因此对分布式锁的考验很大。 -
设置热点数据永远不过期:
只要热点key永不过期,就不会产生相应问题。 -
预先设置热门数据:
在redis高峰访问时期,提前设置热门数据到缓存中,或适当延长缓存中key过期时间。
四、缓存雪崩
问题描述:
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案:
- 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
- 如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。
- 设置热点数据永远不过期。

















 6871
6871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









