




1.DOS窗口相关命令
#连接数据库
mysql -h '服务器主机地址' -u '用户名' -p'用户密码'
#修改密码
update user set password=password('xxxx') where user='root';
#刷新数据库权限
flush privileges;
#显示数据库
show databases;
#打开某个数据库
use dbname;
#显示数据库mysql中所有的表
show tables;
#显示表mysql数据库中user表的列信息
describe user;
#创建数据库
create database xxx;
#选择数据库
use databasename;2. 数据库操作
| 名称 | 解释 | 命令 |
|---|---|---|
| DDL(数据定义语言) | 定义和管理数据对象 | CREATE、DROP、ALTER |
| DML(数据操作语言) | 用于操作数据对象中所包含的数据 | INSERT、UPDATE、DELETE |
| DQL(数据查询语言) | 用于查询数据库数据 | SELECT |
| DCL(数据控制语言) | 用于管理数据库的语言,包括权限管理及数据更改 | GRANT、commit、rollback |
1. 基本增删改操作
1. 创建数据表:
create table [if not exists] `表名`(
'字段名1' 列类型 [属性][索引][注释],
'字段名2' 列类型 [属性][索引][注释],
#...
'字段名n' 列类型 [属性][索引][注释]
)[表类型][表字符集][注释];CREATE TABLE IF NOT EXISTS `student` (
`id` int(4) NOT NULL AUTO_INCREMENT COMMENT '学号',
....
PRIMARY KEY (`id`)
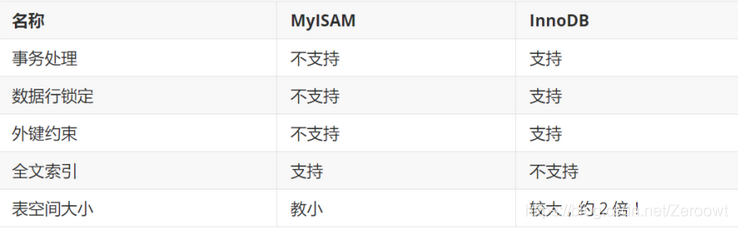
) ENGINE=InnoDB DEFAULT CHARSET=utf8MySQL的数据表的类型 : MyISAM , InnoDB , HEAP , BOB , CSV等…
常见的 MyISAM 与 InnoDB 类型:
2. 修改数据表:
修改表名:
ALTER TABLE 旧表名 RENAME AS 新表名添加字段:
ALTER TABLE 表名 ADD 字段名 列属性[属性]修改字段:
ALTER TABLE 表名 MODIFY 字段名 列类型[属性]
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 列属性[属性]3. 删除数据表:
删除字段:
ALTER TABLE 表名 DROP 字段名删除数据表:
DROP TABLE [IF EXISTS] 表名
4. 查询数据表:
SELECT语法:
注意:[ ] 括号代表可选的 , { }括号代表必选得,且注意前后关系
SELECT [ALL | DISTINCT]
{* | table.* | [table.field1[as alias1][,table.field2[as alias2]][,...]]}
FROM table_name [as table_alias]
[left | right | inner join table_name2] -- 联合查询
[WHERE ...] -- 指定结果需满足的条件
[GROUP BY ...] -- 指定结果按照哪几个字段来分组
[HAVING] -- 过滤分组的记录必须满足的次要条件
[ORDER BY ...] -- 指定查询记录按一个或多个条件排序
[LIMIT {[offset,]row_count | row_countOFFSET offset}];
-- 指定查询的记录从哪条至哪条-
- As子句作为别名
-
- DISTINCT关键字对查询结果去重:SELECT DISTINCT… (大表一般不用distinct去重,建议用GROUP BY)
-
- 使用表达式作为查询列
SELECT @@auto_increment_increment; -- 查询自增步长
SELECT VERSION(); -- 查询版本号
SELECT 100*3-1 AS 计算结果; -- 表达式-
- 模糊查询:IS NULL、IS NOT NULL、BETWEEN、LIKE、IN(a IN (a1,a2,a3…)
-
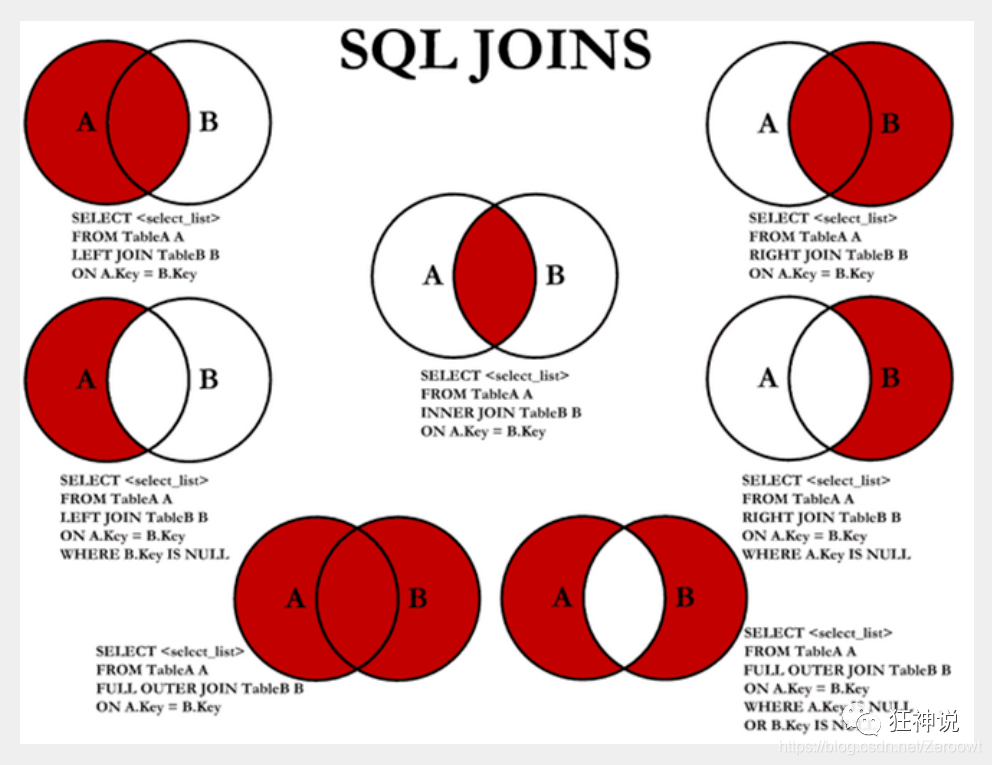
- 连接查询:
| 操作符名称 | 描述 |
|---|---|
| INNER JOIN | 如果表中至少一个匹配,则返回行 |
| LEFT JOIN | 即使右表中没有匹配,也从左表中返回所有的行 |
| RIGHT JOIN | 即使左表中没有匹配,也从中表中返回所有的行 |
-
- 排序和分页: SELECT * FROM table LIMIT [offset,] rows | rows OFFSET offset
| limit x | 按顺序取x条记录 |
|---|---|
| limit x,y | 按索引x取y条数据 |
| limit x offset y | 索引y 取x条数据 |
2. 数据值和列类型
数值类型:
| 类型 | 说明 | 存储需求 |
|---|---|---|
| tinyint | 非常小的数据 | 1字节 |
| smallint | 较小的数据 | 2字节 |
| mediumint | 中等大小的数据 | 3字节 |
| int | 标准整数 | 4字节 |
| bigint | 较大的整数 | 8字节 |
| float | 单精度浮点数 | 4字节 |
| double | 双精度浮点数 | 8字节 |
| decimal | 字符串形式浮点数 |
(float和double容易导致精度丢失,在数字要求准确的情况下必须使用decimal)
字符串类型:
| 类型 | 说明 | 存储需求 |
|---|---|---|
| char[M] | 固定长字符串,检索快但费时间 | M字符 |
| varchar[M] | 可变字符串 ,对应java中的String | 变长度 |
| tinytext | 微型文本串 | 2^8-1字节 |
| text | 文本串 | 2^16-1字节 |
日期和时间型数值类型:
| 类型 | 说明 |
|---|---|
| DATE | YYYY-MM-DD ,日期格式 |
| TIME | Hh:mm:ss,时间格式 |
| DATETIME | YY-MM-DD hh:mm:ss |
| TIMESTAMP | YYYYMMDDhhmmss,时间戳,197010101000000到某个时刻 |
| YEAR | YYYY格式 |
数据字段属性:
- UnSigned:无符号的,声明该数据列不允许为负数
- ZEROFILL:0填充的,不足位数用0来填充,如int(3),4->004
- Auto_InCrement:
- :自动增长的,自动在上一个记录数上加一;
- 通常用于主键,且为整数类型
- 可定义起始值和步长
- NULL 和 NOT NULL
- DEFAULT
3.常用函数
数据函数:
SELECT ABS(-8); /*绝对值*/
SELECT CEILING(9.4); /*向上取整*/
SELECT FLOOR(9.4); /*向下取整*/
SELECT RAND(); /*随机数,返回一个0-1之间的随机数*/
SELECT SIGN(0); /*符号函数: 负数返回-1,正数返回1,0返回0*/字符串函数:
SELECT CHAR_LENGTH('……'); /*返回字符串包含的字符数*/
SELECT CONCAT('a','b','c'); /*合并字符串,参数可以有多个*/
SELECT INSERT('我爱编程helloworld',1,2,'超级热爱'); /*替换字符串,从某个位置开始替换某个长度*/
SELECT LOWER('A'); /*小写*/
SELECT UPPER('a'); /*大写*/
SELECT LEFT('hello,world',5); /*从左边截取*/
SELECT RIGHT('hello,world',5); /*从右边截取*/
SELECT REPLACE('abc','b','d'); /*替换字符串*/
SELECT SUBSTR('abcdfgh',3,3); /*截取字符串,开始和长度*/
SELECT REVERSE('狂神说坚持就能成功'); /*反转
-- 查询姓周的同学,改成邹
SELECT REPLACE(studentname,'周','邹') AS 新名字
FROM student WHERE studentname LIKE '周%';日期和时间函数:
SELECT CURRENT_DATE(); /*获取当前日期*/
SELECT CURDATE(); /*获取当前日期*/
SELECT NOW(); /*获取当前日期和时间*/
SELECT LOCALTIME(); /*获取当前日期和时间*/
SELECT SYSDATE(); /*获取当前日期和时间*/
-- 获取年月日,时分秒
SELECT YEAR(NOW());
SELECT MONTH(NOW());
SELECT DAY(NOW());
SELECT HOUR(NOW());
SELECT MINUTE(NOW());
SELECT SECOND(NOW());聚合函数:
count()
sum();
max();
min();
avg();
group_concat()COUNT(字段)、COUNT(1)、COUNT(*)的区别:
从含义上讲,count(1) 与 count() 都表示对全部数据行的查询。
count(字段) 会统计该字段在表中出现的次数,忽略字段为null 的情况。即不统计字段为null 的记录。
count() 包括了所有的列,相当于行数,在统计结果的时候,包含字段为null 的记录;
count(1) 用1代表代码行,在统计结果的时候,包含字段为null 的记录 。
count(1)和count(*)都会对全表进行扫描,统计所有记录的条数,包括那些为null的记录,因此,它们的效率可以说是相差无几。而count(字段)则与前两者不同,它会统计该字段不为null的记录条数。
- 在表没有主键时,count(1)比count(*)快
- 有主键时,主键作为计算条件,count(主键)效率最高;
- 若表格只有一个字段,则count(*)效率较高。
4. 其他
- 可用反引号(`)为标识符(库名、表名、字段名、索引、别名)包裹,以避免与关键字重名!中文也可以作为标识符!
- 每个库目录存在一个保存当前数据库的选项文件db.opt。
- 注释:
单行注释 # 注释内容
多行注释 /* 注释内容 */
单行注释 -- 注释内容 (标准SQL注释风格,要求双破折号后加一空格符(空格、TAB、换行等))
- 模式通配符:
_ 任意单个字符
% 任意多个字符,甚至包括零字符
单引号需要进行转义 \'
- CMD命令行内的语句结束符可以为 ";", "\G", "\g",仅影响显示结果。其他地方还是用分号结束。delimiter 可修改当前对话的语句结束符。
- SQL对大小写不敏感 (关键字)
- 清除已有语句:\c3.事务
什么是事务:
- 事务就是将一组SQL语句放在同一批次内去执行
- 如果一个SQL语句出错,则该批次内的所有SQL都将被取消执行
- MySQL事务处理只支持InnoDB和BDB数据表类型
ACID:
1. 原子性(Atomic):
整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚(ROLLBACK)到事务开始前的状态,就像这个事务从来没有执行过一样。
2. 一致性(Consist):
一个事务可以封装状态改变(除非它是一个只读的)。事务必须始终保持系统处于一致的状态,不管在任何给定的时间并发事务有多少。也就是说:如果事务是并发多个,系统也必须如同串行事务一样操作。其主要特征是保护性和不变性(Preserving an Invariant),以转账案例为例,假设有五个账户,每个账户余额是100元,那么五个账户总额是500元,如果在这个5个账户之间同时发生多个转账,无论并发多少个,比如在A与B账户之间转账5元,在C与D账户之间转账10元,在B与E之间转账15元,五个账户总额也应该还是500元,这就是保护性和不变性。
3. 隔离性(Isolated):
隔离状态执行事务,使它们好像是系统在给定时间内执行的唯一操作。如果有两个事务,运行在相同的时间内,执行相同的功能,事务的隔离性将确保每一事务在系统中认为只有该事务在使用系统。这种属性有时称为串行化,为了防止事务操作间的混淆,必须串行化或序列化请求,使得在同一时间仅有一个请求用于同一数据。
4. 持久性(Durable):
在事务完成以后,该事务对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。
-- 使用set语句来改变自动提交模式
SET autocommit = 0; /*关闭*/
SET autocommit = 1; /*开启*/
-- 注意:
--- 1.MySQL中默认是自动提交
--- 2.使用事务时应先关闭自动提交
-- 开始一个事务,标记事务的起始点
START TRANSACTION
-- 提交一个事务给数据库
COMMIT
-- 将事务回滚,数据回到本次事务的初始状态
ROLLBACK
-- 还原MySQL数据库的自动提交
SET autocommit =1;
-- 保存点
SAVEPOINT 保存点名称 -- 设置一个事务保存点
ROLLBACK TO SAVEPOINT 保存点名称 -- 回滚到保存点
RELEASE SAVEPOINT 保存点名称 -- 删除保存点
















 1203
1203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









