




 SegFormer是2021年NeurIPS会议上提出的一种高效Transformer模型,针对语义分割任务进行优化。它改进了SETR的不足,通过使用重叠patch和多尺度特征融合,提高了运行效率和准确性。SegFormer的Encoder采用分层结构,Decoder则由轻量级的MLP组成,实现了在ADE20K、Cityscapes和COCO-Stuff数据集上的SOTA性能。此外,模型舍弃了位置编码,增强了鲁棒性。
SegFormer是2021年NeurIPS会议上提出的一种高效Transformer模型,针对语义分割任务进行优化。它改进了SETR的不足,通过使用重叠patch和多尺度特征融合,提高了运行效率和准确性。SegFormer的Encoder采用分层结构,Decoder则由轻量级的MLP组成,实现了在ADE20K、Cityscapes和COCO-Stuff数据集上的SOTA性能。此外,模型舍弃了位置编码,增强了鲁棒性。
前言
SegFormer是2021年发表在NeurIPS的论文, 在Transformer做语义分割的开篇之作——SETR的基础上进行创新,针对SETR的不足之处进行改进。在ADE20K、Cityscapes和COCO-Stuff三个公开数据集上进行测试,其运行效率、准确性和鲁棒性都达到了SOTA的水平。
如下图,横坐标是参数量(单位:百万),纵坐标是ADE20K上的mean IoU。可以看到,与FCN、DeeplabV3、SETR等模型相比,SegFormer在提升了mIoU的同时,参数量大大减少,大幅提升了运行效率。
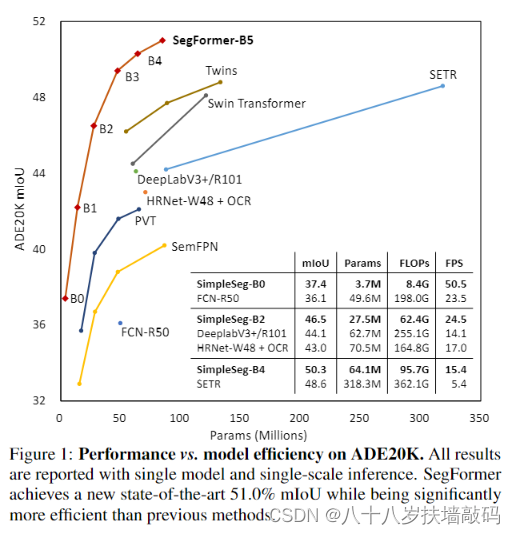
并且在Cityscape-C(对测试图像加各种噪声)上,也大幅度超过了之前的方法(DeeplabV3等),这反映了SegFormer良好的鲁棒性。
1. 模型的特点
SETR使用完全的ViT结构作为backbone,然后使用CNN解码器进行上采样完成分割任务,取得了不错的效果,但是,仍有以下缺点:
- ViT backbone只能输出单尺度低分辨率的特征图,而不是多尺度的
- 计算量大。每个像素都要和其他所有像素做匹配计算。
为了解决第一个问题,PVT模型基于ViT提出了金字塔结构。但是,PVT就像Swin Transformer和Twins这些模型一样,还是采用了Positional Embedding操作,测试时需要插值,不够灵活。
SegFormer主要做了如下几项创新:
- 之前ViT和PVT做patch embedding时,每个patch都是独立的,而SegFormer对patch设计成有重叠的,保证局部连续性。
- 使用了多尺度特征融合。Encoder输出多尺度的特征,Decoder将多尺度的特征融合在一起。好处:模型能够同时捕捉高分辨率的粗略特征和低分辨率的细小特征,优化分割结果。
- 舍弃了ViT和SETR中的position embedding位置编码,取而代之的是Mix FFN。好处:在测试图片大小与训练集图片大小不一致时,不需要再对位置向量做双线性插值。
- 轻量级的Decoder。好处:使得Decoder的计算量和参数量非常小,从而使得整个模型可以高效运行,简单直接。并且,通过聚合不同层的信息,结合了局部和全局注意力
2. 模型结构
如下图所示,SegFormer可以分为两个部分:
- 用于生成多尺度特征的分层Encoder。
- 轻量级的All-MLP Decoder,融合多层特征并上采样,最终解决分割任务。
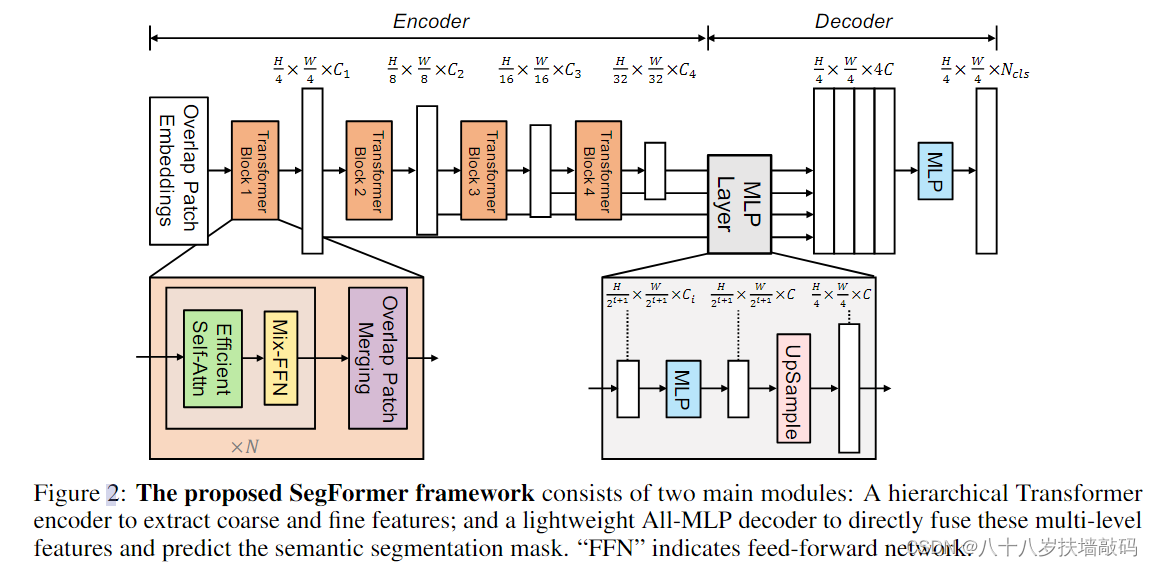
输入一张大小 H × W × 3 H \times W \times 3 H×W×3的图片,首先将其划分为大小 4 × 4 4 \times 4 4×4的patches。对比ViT和SETR中使用的大小 16 × 16 16 \times 16 16×16的patches,使用更小的patches有利于进行分割任务。(由于是预测图像中的每个像素,语义分割又被称为dense prediction密集预测)。
使用这些patches作为Encoder的输入,获取大小为 H 4 × W 4 × C 1 \frac{H}{4} \times \frac{W}{4} \times C_1 4H×4W×C1、 H 8 × W 8 × C 2 \frac{H}{8} \times \frac{W}{8} \times C_2 8H×8W×C2、 H 16 × W 16 × C 3 \frac{H}{16} \times \frac{W}{16} \times C_3 16H×16W×C3、 H 32 × W 32 × C 4 \frac{H}{32} \times \frac{W}{32} \times C_4 32H×32W×C4的多尺度的特征图。
将这些多尺度特征输入到解码器中,经过一系列MLP和上采样操作,最终输入大小 H 4 × W 4 × N c l s \frac{H}{4} \times \frac{W}{4} \times N_{cls} 4H×4W×Ncls的特征图,其中 N c l s N_{cls} Ncls是类别个数。
2.1 Encoder
Encoder是由Transformer Block堆叠起来的,其中包含Efficient Self-Attention、Mix-FFN和Overlap Patch Embedding三个模块。
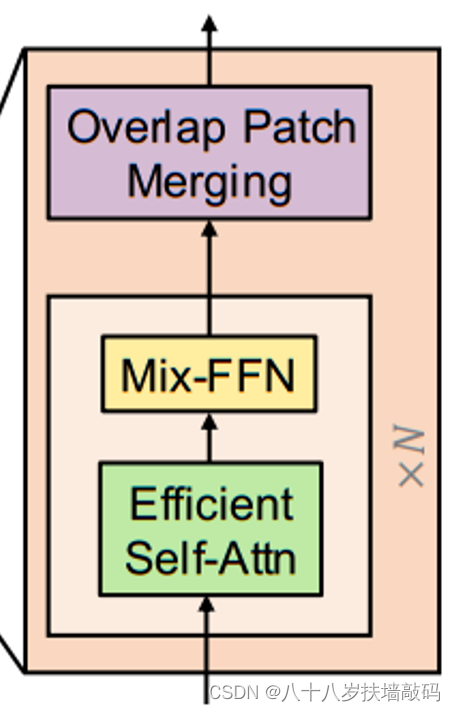
- Overlapped Patch Merging
为了产生类似于CNN backbone的多尺度特征图,SegFormer使用了patch merging的方法,通过 H × W × 3 H \times W \times 3 H×W×3的输入图像,得到大小
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









