







目录
1. 学习内容
1. 逻辑回归本质及其数学推导
2. 逻辑回归代码实现与调用
3. 逻辑回归中的决策边界、多项式以及正则化
2. 用逻辑回归解决分类问题
2.1 为什么不能用线性回归解决分类问题
线性回归的使用是基于很多假设的,其中包括:数据特征与标签之间存在线性关系、数据特征与误差相互独立和误差服从正态分布等。理论上说,任何数据放在任何模型里都会得到相应的参数估计,进而通过得到的参数来建立模型最后对数据进行预测。由于不同模型自身条件的限制,模型的效果未必会得到保证,甚至出现“错且无用”的情况[1]。因此,才需要根据数据自身的特点来选择合适的模型。
显然,分类问题的数据未必会满足线性回归的基本假设。因此,对于分类问题的数据,线性回归模型就是一种“错且无用”的模型。
不过,逻辑回归模型有很多地方是与线性回归模型相似的。因此,可以类比线性回归模型来学习逻辑回归。
2.2 什么是逻辑回归
先回忆一下线性回归的作用:线性回归会返回一个标签的预测值。这个值往往是具有具体意义的,例如房价预测返回的就是预测的房屋价格。而对于分类问题而言,虽然模型最后会返回一个表示类别的数值,但是整个预测的过程却是对概率的预测,即判断数据属于此类别的概率有多大。
最简单的分类问题是二分类问题,我们可以人为规定预测的概率大于某一个阈值时将预测结果确定为某一个类别,反之则确定为另一个类别。逻辑回归,就是实现以上过程的模型。实际上,逻辑回归模型本身就是一种专门用来解决二分类问题的模型,如果要解决多分类问题,要么在逻辑回归的基础上进行进一步的处理,要么去使用其他模型。
3. 逻辑回归的目标函数
下面将介绍两种逻辑回归的推导方式。
3.1 从线性回归到逻辑回归
用逻辑回归解决分类问题时,前面的步骤与线性回归十分类似,也是通过各个特征建立关系得到一个预测值。就像是在线性回归中我们规定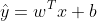 一样。只不过由于逻辑回归需要计算数据输入此样本的概率,既然是概率,那么其取值必然在0与1之间。而类似线性回归中的预测值很难会保证这一点。因此,我们必须通过一些手段将预测值进行变换将其转化为一个在0与1之间的值。
一样。只不过由于逻辑回归需要计算数据输入此样本的概率,既然是概率,那么其取值必然在0与1之间。而类似线性回归中的预测值很难会保证这一点。因此,我们必须通过一些手段将预测值进行变换将其转化为一个在0与1之间的值。
我们可以考虑这样一个连续函数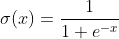 。如果画出它的图像可以发现,它的定义域为全体实数,而值域则是(0, 1)。因此,这个函数
。如果画出它的图像可以发现,它的定义域为全体实数,而值域则是(0, 1)。因此,这个函数 (也叫做sigmoid函数)常常用来完成我们需要的转换工作。
(也叫做sigmoid函数)常常用来完成我们需要的转换工作。
因此,我们需要预测的概率的表达式就是
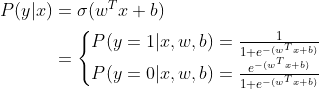
这里我们人为规定y=1时的概率为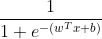 ,y=0时的概率为
,y=0时的概率为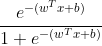 ,反过来定义也可以。
,反过来定义也可以。
接下来我们需要将两个式子合并成一个式子
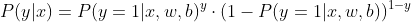
由于这个式子既存在指数又存在乘积,因此需要取对数从而方便后续的优化工作,因此可得
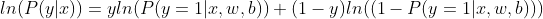
最后,将所有数据的预测概率统一到一起可得
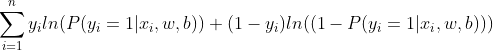
由于目标函数需要越小越好,而这个式子意味着值越大效果越好。为了调和这种矛盾,需要在这个式子之前添加一个负号。最后,目标函数的表达式为
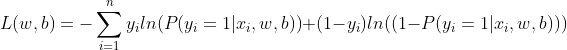
3.2 从极大似然到逻辑回归
逻辑回归的损失函数当然不是凭空出现的,而是根据逻辑回归本身式子中系数的极大似然估计推导而来的。极大似然估计就是通过已知结果去反推最大概率导致该结果的参数。
极大似然估计是概率论在统计学中的应用,它提供了一种给定观察数据来评估模型参数的方法,即 “模型已定,参数未知”。更具体一点,就是通过若干次试验,观察其结果,利用实验结果计算得到的使实验结果出现的概率最大的参数的取值。
逻辑回归是一种监督式学习,是有训练标签的,就是有已知结果的。根据极大似然,从这个已知的结果入手,去推导能获得最大概率的结果参数。只要我们得出了这个参数,那模型就可以很准确的预测未知的数据了[2]。
跟线性回归一样,如果想要利用极大似然推导逻辑回归的目标函数,同样需要数据满足基本假设:样本彼此间相互独立。在这种情况下,可以得出
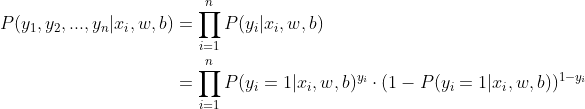
因此,我们现在就是需要找出合适的参数w和b来使得上式的值最大,即
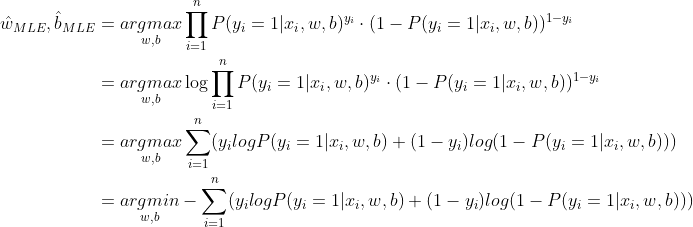
可以发现该结果与上面从线性回归得到的结果是一致的。
4. 利用梯度下降法求解参数
同线性回归,这里我们也可以使用梯度下降法来求得最佳参数(逻辑回归的目标函数一定是凸函数)。具体推导过程可参考[2]。这里直接展示结果,如下所示
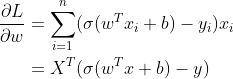
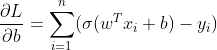
5. 逻辑回归的实现及应用
具体代码如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
# 随机生成二分类的样本数据,每一类5000个样本数据
np.random.seed(12)
num_observations = 5000
x1 = np.random.multivariate_normal([0, 0], \
[[1, .75], [.75, 1]], \
num_observations)
x2 = np.random.multivariate_normal([1, 4], \
[[1, .75], [.75, 1]], \
num_observations)
# 这里采用了不同于之前的数组拼接方法
# np.vstack()会纵向拼接
# np.hstack()会横向拼接,一维数组除外
X = np.vstack([x1, x2]).astype(np.float32)
y = np.hstack([np.zeros(num_observations), \
np.ones(num_observations)])
print(X.shape, y.shape)
# 数据可视化
plt.figure(figsize = (12, 8))
plt.scatter(X[:, 0], X[:, 1], c = y, alpha = .4)
# 实现sigmoid函数
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# 计算log likelihood
def log_likelihood(X, y, w, b):
'''
针对所有样本数据,计算负的log likelihood
也叫做cross-entropy loss,越小越好
X:训练数据(特征向量),大小为N * D
y:训练数据(标签),一维向量,长度为D
w:模型参数,一维向量,长度为D
b:模型偏移量,标量
'''
# 按标签提取样本下标
index_pos, index_neg = np.where(y == 1), np.where(y == 0)
# 对正样本计算loss
pos_sum = np.sum(np.log(sigmoid(np.dot(X[index_pos], w) + b)))
neg_sum = np.sum(np.log(1 - sigmoid(np.dot(X[index_neg], w) + b)))
return -(pos_sum + neg_sum)
# 实现逻辑回归模型
def logistic_regression(X, y, num_steps, learning_rate):
'''
基于梯度下降算法实现逻辑回归模型
X:训练数据(特征向量),大小为N * D
y:训练数据(标签),一维向量,长度为D
num_steps:迭代次数
learning_rate;学习率
'''
# 初始化w和b,注意w是一个向量,维数为N
w, b = np.zeros(X.shape[1]), 0
for step in range(num_steps):
# 预测值与真实值之间的误差
error = sigmoid(np.dot(X, w) + b) - y
# 梯度计算
grad_w = np.matmul(X.T, error)
grad_b = np.sum(error.T)
# 梯度更新
w = w - learning_rate * grad_w
b = b - learning_rate * grad_b
# 每隔一段时间,计算log likelihood的变化情况
# 正常情况下应慢慢变小最后收敛
if step % 10000 == 0:
print(w, b, log_likelihood(X, y, w, b))
return w, b
w, b = logistic_regression(X, y, 100000, 5e-5)
print(w, b)
# 使用sklearn自带的模型
# 截距设置为存在,C是正则化系数的倒数,这里设置这么大意味着不想加入正则
clf = LogisticRegression(fit_intercept = True, C = 1e15, solver = 'liblinear')
clf.fit(X, y)
print(clf.coef_, clf.intercept_)
x = X[:, 0]
y1 = -(b + w[0] * x) / w[1]
y2 = -(clf.intercept_[0] + clf.coef_[0][0] * x) / clf.coef_[0][1]
plt.plot(x, y1, c = 'r')
plt.plot(x, y2, c = 'b')
plt.show()输出结果如下:
(10000, 2) (10000,)
[0.12329042 0.50025684] 0.0 4346.264779152365
[-3.91805809 6.43642177] -10.875436740117019 148.70672276805348
[-4.40511595 7.22269483] -12.241383295773542 142.9649362310784
[-4.64892047 7.61927374] -12.929693005120427 141.54530307157364
[-4.79161626 7.85210758] -13.333633605973615 141.06031965930805
[-4.88097151 7.99814079] -13.586925681052564 140.8703158589161
[-4.93898319 8.09303712] -13.751498400161278 140.7902591275381
[-4.97745835 8.15601123] -13.86070057499041 140.75505002269912
[-5.00331896 8.19835395] -13.934121899487094 140.7391450318095
[-5.02085141 8.22706747] -13.983908547254233 140.73183498915876
[-5.03280465 8.24664683] -14.017856497489424
[[-5.02712572 8.23286799]] [-13.99400797]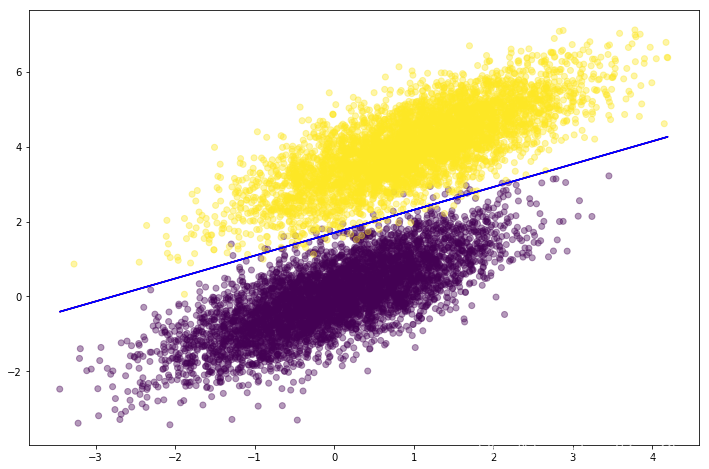
通过结果可以发现由梯度下降法得到的分界线(决策边界)和调用sklearn中的相关类得到的分界线十分接近。
其他的项目可参考[3],基本上与以上代码是一致的。
6. 逻辑回归的决策边界及多项式
我们在规定逻辑回归的目标函数时默认以0.5为分界线,大于0.5的结果记为1,否则记为0。而所有恰好等于0.5的点构成的集合就是逻辑回归的决策边界。决策边界不是逻辑回归专属的概念,很多模型都可以有它的决策边界。
对于一个模型而言,它是否是一个线性模型取决于其决策边界是否是一个线性边界。由于逻辑回归模型的决策边界是一个线性的边界,因此逻辑回归属于线性模型。
既然有了线性决策边界,自然也存在非线性决策边界。下图的数据具有的就是一个典型的非线性决策边界。
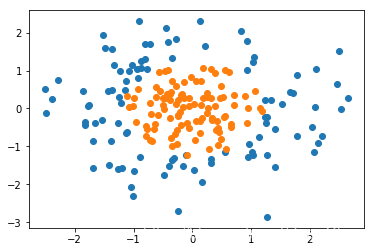
我们假定该数据的决策边界是一个圆,那么边界满足的方程就是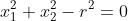 ,此时如果我们将每一项都当作一个一次项或者常数项的话,这个边界的方程就又变成了一个线性的方程。从而,就可以继续使用逻辑回归的方式来进行分类。手动实现的具体代码可参考[4]。这里提供用sklearn中的多项式回归处理的代码。
,此时如果我们将每一项都当作一个一次项或者常数项的话,这个边界的方程就又变成了一个线性的方程。从而,就可以继续使用逻辑回归的方式来进行分类。手动实现的具体代码可参考[4]。这里提供用sklearn中的多项式回归处理的代码。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
np.random.seed(2020)
X = np.random.normal(0, 1, size = (200, 2))
y = np.array((X[:, 0] ** 2 + X[:, 1] ** 2) < 1.5, dtype = 'int')
# 为逻辑回归添加多项式项的管道
def PolynomialLogisticRegression(degree):
return Pipeline([
('poly', PolynomialFeatures(degree = degree)),
('std_scaler', StandardScaler()),
('log_reg', LogisticRegression())
])
# 绘制决策边界的方法
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1, 1),
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0, x1, zz, linewidth = 5, cmap = custom_cmap)
# 使用管道得到对象
poly_log_reg = PolynomialLogisticRegression(degree = 2)
poly_log_reg.fit(X, y)
poly_log_reg.score(X, y)
plot_decision_boundary(poly_log_reg, axis = [-4, 4, -4, 4])
plt.scatter(X[y == 0,0], X[y == 0,1])
plt.scatter(X[y == 1,0], X[y == 1,1])
plt.show()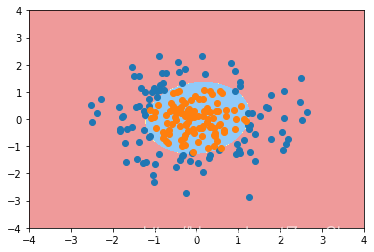
7. 逻辑回归的正则化
参考[5][6]和上面的代码,实际上逻辑回归也是存在欠拟合和过拟合的情况的。例如,还是上面的例子,如果将degree从2调整至20,那么就会得到下面的结果(为了让效果更明显,数据中掺杂了一些噪音)。
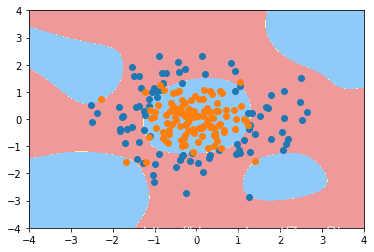
根据[6],在保持degree=20的情况下,通过加入正则可以消除过拟合的情况。具体代码如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
np.random.seed(2020)
X = np.random.normal(0, 1, size = (200, 2))
y = np.array((X[:, 0] ** 2 + X[:, 1] ** 2) < 1.5, dtype = 'int')
for i in range(20):
y[np.random.randint(200)] = 1
# 为逻辑回归添加多项式项的管道
def PolynomialLogisticRegression(degree, penalty = 'l2', C = 0.1):
return Pipeline([
('poly', PolynomialFeatures(degree = degree)),
('std_scaler', StandardScaler()),
('log_reg', LogisticRegression(penalty = penalty, C = C))
])
# 绘制决策边界的方法
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1, 1),
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0, x1, zz, linewidth = 5, cmap = custom_cmap)
# 使用管道得到对象
poly_log_reg = PolynomialLogisticRegression(degree = 20, penalty = 'l2', C = 0.01)
poly_log_reg.fit(X, y)
poly_log_reg.score(X, y)
plot_decision_boundary(poly_log_reg, axis = [-4, 4, -4, 4])
plt.scatter(X[y == 0,0], X[y == 0,1])
plt.scatter(X[y == 1,0], X[y == 1,1])
plt.show()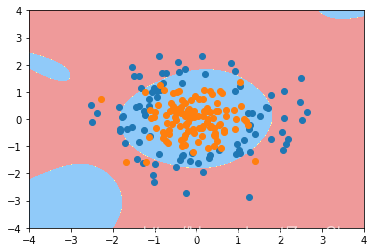
同样,调节相关参数可以得到L1正则化后的结果。

8. 参考文献
1. https://mp.weixin.qq.com/s/xfteESh2bs1PTuO2q39tbQ
2. https://mp.weixin.qq.com/s/nZoDjhqYcS4w2uGDtD1HFQ
3. https://mp.weixin.qq.com/s/ex7PXW9ihr9fLOjlo3ks4w
4. https://mp.weixin.qq.com/s/97CA-3KlOofJGaw9ukVq1A
5. https://mp.weixin.qq.com/s/BUDdj4najgR0QAHhtu8X9A
6. https://blog.youkuaiyun.com/Zee_Chao/article/details/105325392

















 995
995

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









