







 本文深入探讨了梯度下降法的原理与应用,包括梯度的概念、算法推导、代码实现,以及在多元线性回归中的应用。同时,介绍了随机梯度下降法和小批量梯度下降法,讨论了导数计算方法,并提供了实战代码示例。
本文深入探讨了梯度下降法的原理与应用,包括梯度的概念、算法推导、代码实现,以及在多元线性回归中的应用。同时,介绍了随机梯度下降法和小批量梯度下降法,讨论了导数计算方法,并提供了实战代码示例。
目录
1. 学习目标
1. 了解梯度下降法的用途、原理及推导
2. 实现梯度下降并在线性回归当中使用梯度下降法
3. 了解和实现随机梯度下降法和小批量梯度下降法
2. 梯度下降法
2.1 最优化目标函数时遇到的问题与梯度下降算法
如果我们把机器学习算法看做一个函数的集合,那么我们需要根据定义好的某项衡量标准来从中找出最好的那个函数。例如,在第二周我们学习了如何衡量一个模型的好坏即衡量标准;第四周我们通过最小二乘法找到了线性回归模型的目标函数的最优参数从而确定了最好的函数的表达式。
一个机器学习算法的学习器的构建过程:首先需要明确使用哪个模型,然后得到这个模型的目标函数,接着计算出使目标函数最优的参数,最后将参数应用于模型。
那么,是否所有的函数都可以使用类似最小二乘法的方法来求解使目标函数最优的参数从而确定最优的函数呢?理论上是可以的,但是仅限于理论。因为很多目标函数十分复杂,想要计算十分困难。因此,我们必须要用一种适用性更加广泛的方法来计算或者近似计算能令目标函数最优的参数。因此,梯度下降算法被人们拿来使用。
总之,梯度下降算法并不是什么机器学习算法,而是一种帮助人们找到最优化目标函数参数的方法。
2.2 梯度的简单回顾
梯度是一个向量,它的每个元素为函数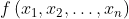 对一元变量
对一元变量 的偏导数。它既有大小(其大小为函数在给定点最大的方向导数),也有方向。对于一个损失函数
的偏导数。它既有大小(其大小为函数在给定点最大的方向导数),也有方向。对于一个损失函数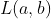 而言,它的梯度是
而言,它的梯度是
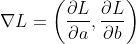
所谓梯度的方向即函数在给定点的上升最快的方向。
2.3 梯度下降算法的理解及推导
假设有如下场景[1]:
一个人被困在山上,需要从山顶到山谷。但此时雾很大,看不清下山的路径。他必须利用自己周围的信息去找到下山的路径。这个时候,他就可以利用梯度下降算法来帮助自己下山。具体来说就是,以他当前的所处的位置为基准,随机选择一个方向,然后每次迈步都选择最陡的方向。然后每走一段距离,都反复采用同一个方法:如果发现脚下的路是下坡,就顺着最陡的方向走一步,如果发现脚下的路是上坡,就逆着方向走一步,最后就能成功的抵达山谷。
从数学的角度出发,针对损失函数,假设选取的初始点为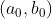 ,现在将这个点稍微移动一点点,得到
,现在将这个点稍微移动一点点,得到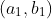 。那么根据泰勒展开式(多元函数的一阶展开式):
。那么根据泰勒展开式(多元函数的一阶展开式):
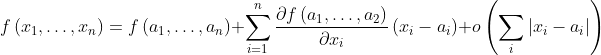
设我们移动的“一点点”为 ,则
,则 。将泰勒展开式代入可得
。将泰勒展开式代入可得

令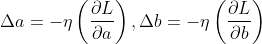 ,其中
,其中 ,则
,则
![\Delta L \approx-\eta\left[\left(\frac{\partial L}{\partial a}\right)^{2}+\left(\frac{\partial L}{\partial b}\right)^{2}\right] \leqslant 0](https://i-blog.csdnimg.cn/blog_migrate/cf705dbe8ad88db4cb623e724073084c.gif%20%5Capprox-%5Ceta%5Cleft%5B%5Cleft%28%5Cfrac%7B%5Cpartial%20L%7D%7B%5Cpartial%20a%7D%5Cright%29%5E%7B2%7D+%5Cleft%28%5Cfrac%7B%5Cpartial%20L%7D%7B%5Cpartial%20b%7D%5Cright%29%5E%7B2%7D%5Cright%5D%20%5Cleqslant%200)
到这里就说明,如果按照规定的移动距离公式移动参数,那么损失函数的函数值始终是下降的。这样就达到了我们要求的“损失变小”的要求了。如果一直重复这种移动,则可以证明损失函数最终能够达到一个最小值。
因此,我们就可以得到损失函数值(也就是下一步的落脚点)的迭代公式:
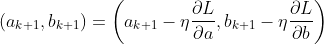
梯度的方向就是损失函数值在此点上升最快的方向,是损失增大的区域。而我们要使损失最小,就要逆着梯度方向走,也就是负的梯度的方向,所以梯度需要加上负号。
另外,参数 叫做“学习率”,它对应的是步伐的长度。学习率是模型训练时的一个很重要的超参数,能直接影响算法的正确性和效率。学习率不能太大也不能太小。学习率太大,有可能会“迈过”最低点,从而发生“摇摆”的现象(不收敛),无法到达最低点。学习率太小,会导致每次迭代时,参数几乎不变化,收敛速度变慢,需要很长时间才能达到最低点,使得算法的效率降低。
叫做“学习率”,它对应的是步伐的长度。学习率是模型训练时的一个很重要的超参数,能直接影响算法的正确性和效率。学习率不能太大也不能太小。学习率太大,有可能会“迈过”最低点,从而发生“摇摆”的现象(不收敛),无法到达最低点。学习率太小,会导致每次迭代时,参数几乎不变化,收敛速度变慢,需要很长时间才能达到最低点,使得算法的效率降低。
2.4 梯度下降法存在的问题
从理论上,梯度下降法只能保证达到局部最低点,而非全局最低点。在很多复杂函数中有很多极小值点,我们使用梯度下降法只能得到局部最优解,而不能得到全局最优解。
要解决这个问题有以下几种方法:
1. 随机选取多个初始点进行梯度下降,从所得的结果中选取最小的;
2. 对目标函数进行凸优化,使其极小值点唯一。这样局部最低点就是全局最低点。
3. 梯度下降的代码实现
3.1 如何实现导数计算
python中有两种常见求导的方法,一种是使用scipy库中的derivative(),另一种就sympy库中的diff()[2]。
3.1.1 scipy.misc.derivative()
该函数的参数如下:
func:需要求导的函数,只写参数名即可,不要写括号,否则会报错
x0:要求导的那个点,float类型
dx(可选):间距,应该是一个很小的数,float类型
n(可选):n阶导数。默认值为1,int类型
args(可选):参数元组
order(可选):使用的点数必须是奇数,int类型
from scipy.misc import derivative
def f(x):
return x ** 3 + x ** 2
result = derivative(func = f, x0 = 1.0, dx = 1e-6, n = 1)
print(result)4.9999999999217343.1.2 sympy
sympy是一个python的科学计算库,用一套强大的符号计算体系完成诸如多项式求值、求极限、解方程、求积分、微分方程、级数展开、矩阵运算等等计算问题[6]。所谓符号化,是指将数学公式以直观符号的形式输出。
我们可以举如下的例子来说明sympy的使用方法。
import sympy as sy
# 定义符号变量
x = sy.Symbol('x')
# 定义函数表达式
func = 1 / (1 + x** 2)
print('x:', type(x))
# 打印函数表达式
print(func)
# 打印二阶导函数表达式
print(sy.diff(func, x, 2))
# 代入数值计算
print(sy.diff(func, x).subs(x, 3))
# 代入数值计算并将结果转化为浮点数
print(sy.diff(func, x).subs(x, 3).evalf())x: <class 'sympy.core.symbol.Symbol'>
1/(x**2 + 1)
-2*x/(x**2 + 1)**2
-3/50
-0.06000000000000003.2 模拟并可视化梯度下降过程
import numpy as np
import matplotlib.pyplot as plt
from scipy.misc import derivative
def lossFunction(x):
return (x - 2.5) ** 2 - 1
# 在-1到6的范围内构建140个点
plot_x = np.linspace(-1, 6, 141)
# plot_y 是对应的损失函数值
plot_y = lossFunction(plot_x)
theta_history = []
def gradient_descent(initial_theta, eta, epsilon = 1e-6):
'''
initial_theta: 参数初始化值
eta: 学习率(移动步长)
epsilon: 判断收敛的阈值
'''
theta = initial_theta
# 记录历次参数的取值
theta_history.append(theta)
while True:
# 每一轮循环后,要求当前这个点的梯度是多少
gradient = derivative(func = lossFunction, x0 = theta, dx = 1e-6, n = 1)
last_theta = theta
# 移动点,沿梯度的反方向移动步长eta
theta = theta - eta * gradient
theta_history.append(theta)
# 判断theta是否达到损失函数最小值的位置
if(abs(lossFunction(theta) - lossFunction(last_theta)) < epsilon):
break
gradient_descent(0, 0.1)
plt.plot(plot_x, plot_y, color = 'blue')
plt.plot(np.array(theta_history), lossFunction(np.array(theta_history)), \
color = 'red', marker = 'o')
plt.show()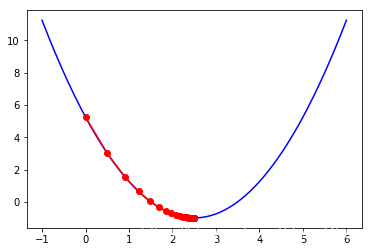
同样的一段代码,我们分别令=0.01, 0.9, 1。可以得到如下结果:
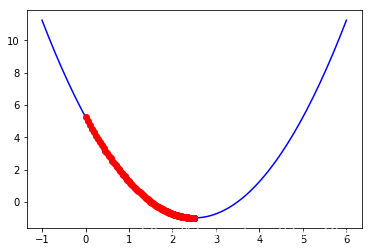
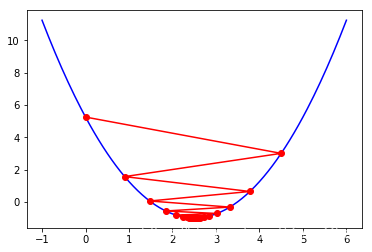
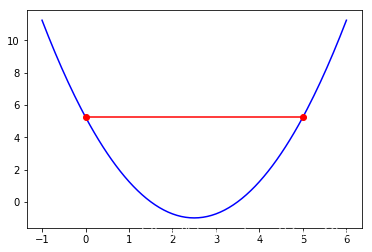
可以发现,这三种取值都没有0.1的效果好。从而印证了2.3中的为什么学习率不可过大或过小。
4. 将梯度下降应用于多元线性回归(以波士顿房价数据为例)
在多元线性回归中,其预测值为: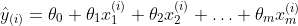 ,目标函数为
,目标函数为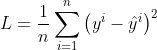 。目标函数对参数向量
。目标函数对参数向量 求导得
求导得
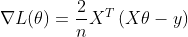
此时,就可以使用类似3.2代码的方式来对多元线性回归的目标函数。
import numpy as np
from sklearn import datasets
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
boston = datasets.load_boston()
X = boston.data
X = np.c_[np.ones(X.shape[0]), X]
y = boston.target
X = X[y < 50.]
y = y[y < 50.]
X = StandardScaler().fit_transform(X)
# 实现逻辑回归模型
def linear_regression(X, y, num_steps, learning_rate):
'''
基于梯度下降算法实现逻辑回归模型
X:训练数据(特征向量),大小为N * D
y:训练数据(标签),一维向量,长度为N
num_steps:迭代次数
learning_rate;学习率
'''
# 初始化w,注意w是一个向量,维数为N
w = np.zeros(X.shape[1])
cur_step = 0
while cur_step < num_steps:
# 梯度计算
grad_w = X.T.dot(X.dot(w) - y) * 2. / len(y)
# 梯度更新
w = w - learning_rate * grad_w
cur_step += 1
return w
w = linear_regression(X, y, 1000000, 0.0001)
print(w)
# 使用sklearn自带的模型
lr = LinearRegression(fit_intercept = False)
lr.fit(X, y)
print(lr.coef_)需要说明的是,这一段代码中的数据X必须要做无量纲化的处理。因为一些特征数据彼此的规模差别很大,如果不做归一化处理,结果会有很大的偏差,甚至会报错。详细的解释和分析可以参考[3]。
5. 随机梯度下降法与小批量梯度下降法
5.1 随机梯度下降法
之前的梯度下降法也叫做批量梯度下降法,因为在计算使目标函数最优的参数时所有的数据全部参与了计算。如果数据规模很庞大,那么批量梯度下降的计算时间就会变长。因此,针对该缺点,诞生了一种更好的方法——随机梯度下降法。随机梯度下降是每次迭代使用一个随机的样本来对参数进行更新。虽然每次迭代后损失函数都未必是向着全局最优方向优化的,但是从全局上看还是向全局最优方向优化的。即使最终未必会到达全局最优解,但也是在全局最优解的附近。相比于批量梯度,这样的方法更快。简单来说,随机梯度下降法是一种用精度换时间的计算方法[4]。
不过需要注意的是,随机梯度下降算法中的学习率的取值是不可以固定的。因为如果学习率一直取一个固定值,可能会导致点已经取到最小值附近了,但是固定的步长导致接下来的取值又跳去了这个点的范围。因此,在随机梯度下降法中,学习率的取值应当逐渐减小。一般,随机梯度下降的学习率 。其中,iter为迭代次数,另外两个值为常数。这样既可以保证学习率随迭代次数逐渐减小,又不会在迭代开始的几次下降过快。
。其中,iter为迭代次数,另外两个值为常数。这样既可以保证学习率随迭代次数逐渐减小,又不会在迭代开始的几次下降过快。
根据其定义,随机梯度下降不再使用全体训练数据进行计算,而是随机抽取一个数据。因此,对于多元线性回归而言,其目标函数变成了
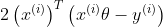
同样的数据用随机梯度下降算法得到的代码如下:
import numpy as np
from sklearn import datasets
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
boston = datasets.load_boston()
X = boston.data
X = np.c_[np.ones(X.shape[0]), X]
y = boston.target
X = X[y < 50.]
y = y[y < 50.]
X = StandardScaler().fit_transform(X)
# 实现逻辑回归模型
def linear_regression(X, y, num_steps):
'''
基于随机梯度下降算法实现逻辑回归模型
X:训练数据(特征向量),大小为N * D
y:训练数据(标签),一维向量,长度为N
num_steps:迭代次数
'''
# 初始化w,注意w是一个向量,维数为N
w = np.zeros(X.shape[1])
# 设置学习率变换的常量t0和t1
t0 = 5
t1 = 50000
cur_step = 0
while cur_step < num_steps:
# 随机抽取一条数据
i = np.random.randint(len(X))
# 梯度计算
grad_w = X[i].T.dot(X[i].dot(w) - y[i]) * 2
# 梯度更新
learning_rate = t0 / (t1 + cur_step)
w = w - learning_rate * grad_w
cur_step += 1
return w
w = linear_regression(X, y, 1000000)
print(w)
# 使用sklearn自带的模型
lr = LinearRegression(fit_intercept = False)
lr.fit(X, y)
print(lr.coef_)5.2 小批量梯度下降法
另外,也可以考虑既不用全体数据参与计算,也不用单一数据参与计算,而是从数据中随机抽取一部分来进行计算。这就是小批量梯度下降法。它可以兼顾二者的优势,是一种折中的方法。
同样的数据用小批量梯度下降算法得到的代码如下:
import numpy as np
from sklearn import datasets
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
boston = datasets.load_boston()
X = boston.data
X = np.c_[np.ones(X.shape[0]), X]
y = boston.target
X = X[y < 50.]
y = y[y < 50.]
X = StandardScaler().fit_transform(X)
# 实现逻辑回归模型
def linear_regression(X, y, num_steps):
'''
基于随机梯度下降算法实现逻辑回归模型
X:训练数据(特征向量),大小为N * D
y:训练数据(标签),一维向量,长度为N
num_steps:迭代次数
'''
# 初始化w,注意w是一个向量,维数为N
w = np.zeros(X.shape[1])
# 设置学习率变换的常量t0和t1
t0 = 5
t1 = 50000
cur_step = 0
# 每次选取10个值进行计算
n = 10
while cur_step < num_steps:
# 随机抽取一条数据
# randint()方法在不指定数据维度时默认为输出一个随机值
i = np.random.randint(0, len(X), n)
# 梯度计算
grad_w = X[i].T.dot(X[i].dot(w) - y[i]) * 2 / n
# 梯度更新
learning_rate = t0 / (t1 + cur_step)
w = w - learning_rate * grad_w
cur_step += 1
return w
w = linear_regression(X, y, 1000000)
print(w)
# 使用sklearn自带的模型
lr = LinearRegression(fit_intercept = False)
lr.fit(X, y)
print(lr.coef_)6. 梯度下降时导函数正确性的检测
简单来说就是利用琴生不等式,具体思路可以参考[5]。
7. 参考文献
1. https://mp.weixin.qq.com/s/44p8anqiiQV6XYGqH5u-Ug
2. https://mp.weixin.qq.com/s/nI9IBa4ccfg0xqyn0tbRPA
3. https://mp.weixin.qq.com/s/8gStYSSBvkXeuaX6Pp9qiQ
4. https://mp.weixin.qq.com/s/OUslRwKGpS29gncsiyAPyg
5. https://mp.weixin.qq.com/s/CL5GZKGHPaUf9MW2d08C2A
6. https://blog.youkuaiyun.com/cj151525/article/details/95756847

















 450
450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









