






A. 实现transformer
1. 设计思路和计算方法
最初的设想是作为文本翻译model使用。它的设计思路如下:

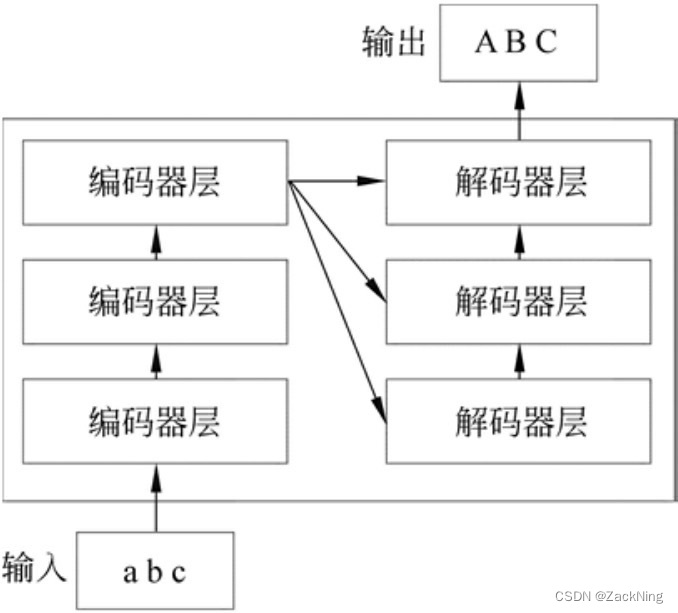
transformer对我们来说是一个黑盒,输入一句话,输出一句话,形成了原文和译文的关系。即广义上的翻译task。将黑盒打开会看到它内部有一个编码器和一个解码器,编码器负责读取原文从原文中抽取特征后交给解码器生成泽文。
从下图可以看出,它们的内部都是多层结构,实际情况远远多于图中的层数。编码器在计算时,多层编码器是前后串行结构,最终一层抽取的文本特征作为最终的文本特征.解码器同样是前后串行的结构,每次的计算输入除了前一层的计算输出,还包括了编码器抽取的文本特征。如果要把上面的计算过程类比成人类思考的过程,则可以设想这样一个场景,一个人看到了一句中文,他的任务是把这句中文翻译成英文,他大体上需要分两步来完成这项任务,首先需要把中文读到大脑中,读的过程往往不是一次完成的,人类在做这件事情时往往依靠潜意识,所以很难意识到读的过程需要很多次,同样一句话,第1次读和第2次读往往有不同的感觉,这就相当于Transformer中的多层编码器。在读取文本后,人类需要组织语言把这句话翻译成英文,翻译的过程同样需要多次“改稿”,最终人类在大脑中完成翻译工作,组织了一句满意的译文,相当于Transformer中的多层解码器。
现在更加深入一点.打开每层编码器和解码器看看它们的内部构造,如下图所示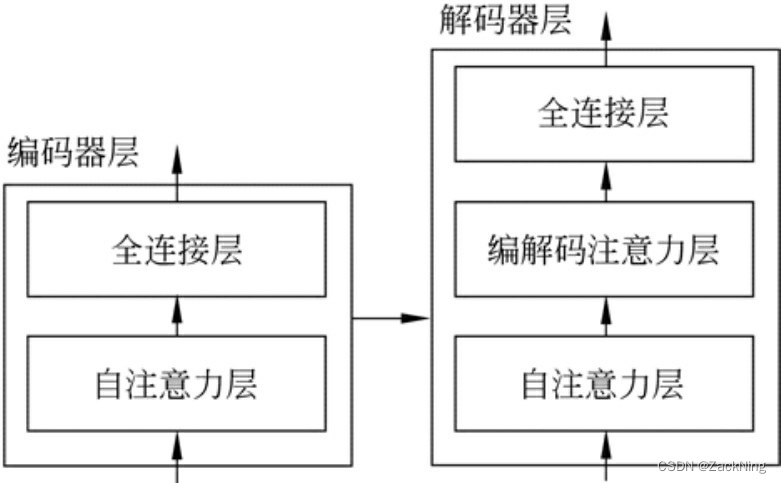
从上图中可以看出,编码器层的计算包括两步,分别是自注意力层计算和全连接层计算,而解码器的计算和编码器层的计算过程很相似,只是多了一层,即编解码注意力层。
小结,在Transformer被提出之前,普遍使用的文本特征抽取层是RNN,它的缺点是能表达的文本复杂度很有限,尤其针对长文本的处理能力更差,虽然在LSTM和GRU模型被提出后RNN的这个缺点在很大程度上被弥补了,但依然没有得到彻底解决。
它还有一个缺点,即它的计算过程是串联的,必须先算第1个词才能算第2个词,在文本长度较长的情况下RNN的计算效率较低。
Transformer使用注意力模型抽取文本特征,很好地解决了RNN的两个缺点,Transformer的注意力模型就是要找出词与词之间的相互对应关系,所以对长文本有较好的处理能力,Transformer计算过程是可并行的,效率比RNN要高很多。
但是Transformer也有缺点,它的缺点就是相比RNN而言太复杂了RNN是个非常简单漂亮的模型,就算是对RNN一无所知的人也能在很短的时间内理解RNN的计算过程和原理,相比之下Transformer就复杂得多,学习的难度也较大。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









