



大家好,我是Zac。不知道各位氪官有木有参加昨天晚上的洛谷入门赛,如果参加了的话,欢迎各位神犇小伙伴们把自己的排名打在评论区~(反正本蒟蒻排名三位数,最后一道题点上提交键了结果21: 00了qwq)
T1 季风
题目描述
已是夏季,S 市刮起了季风。N 大学环境学院对某日的季风进行了监测,监测结果为两个非零整数 a,b。
- a 表示在南北方向上的风速,若 a>0 则表示刮风速为 a 米每秒的北风,若 a<0 则表示刮风速为 −a 米每秒的南风。
- b 表示在东西方向上的风速,若 b>0 则表示刮风速为 b 米每秒的东风,若 b<0 则表示刮风速为 −b 米每秒的西风。
请你判断季风的实际方向,具体地:
- 若在南北方向上刮北风,东西方向上刮东风,则实际方向为东北,输出
NorthEast。 - 若在南北方向上刮北风,东西方向上刮西风,则实际方向为西北,输出
NorthWest。 - 若在南北方向上刮南风,东西方向上刮东风,则实际方向为东南,输出
SouthEast。 - 若在南北方向上刮南风,东西方向上刮西风,则实际方向为西南,输出
SouthWest。
输入格式
输入一行两个用空格分隔的非零整数 a,b。
输出格式
输出一行一个字符串,表示季风的方向。字符串的格式如【题目描述】中所述。
输入输出样例
输入 #1
1 2
输出 #1
NorthEast
输入 #2
-20 20
输出 #2
SouthEast
说明/提示
样例 1 解释
由于 a>0,则在南北方向上刮北风;由于 b>0,则在东西方向上刮东风。
因此实际方向为东北,输出 NorthEast。
数据范围与约定
对于全部数据,满足 1≤∣a∣,∣b∣≤20。
其中,∣x∣ 代表 x 的绝对值,即,将 x 的符号去掉后得到的非负值。如果 x 是正数和 0,∣x∣=x;如果 x 是负数,∣x∣=−x。
思路:
这道题其实是一道水题,只要你找到了方法。
题目要求根据给定的两个非零整数a和b来判断季风的方向。
根据题目描述:
- a表示南北方向:a>0为北风(风速a米/秒),a<0为南风(风速|a|米/秒,但方向是南)。
- b表示东西方向:b>0为东风(风速b米/秒),b<0为西风(风速|b|米/秒,方向是西)。
实际方向由南北和东西方向的组合决定:
北风 + 东风 -> 东北(NorthEast)
北风 + 西风 -> 西北(Northwest)
南风 + 东风 -> 东南(Southeast)
南风 + 西风 -> 西南(Southwest)
注意:题目明确a和b都是非零整数,所以不需要考虑为零的情况。
因此,我们可以根据a和b的正负来组合:
a>0 表示北风,a<0 表示南风。
b>0 表示东风,b<0 表示西风。
具体判断:
如果a为正,b为正,输出"NorthEast"
如果a为正,b为负,输出"Northwest"
如果a为负,b为正,输出"Southeast"
如果a为负,b为负,输出"Southwest"
所以,我们只需要取这四个字符中的一个即可,也就是先判断南北方向,再分别判断东西方向。
AC Code:
#include <iostream>
using namespace std;
int main() {
int a, b;
cin >> a >> b;
if (a > 0) {
if (b > 0) {
cout << "NorthEast";
} else {
cout << "NorthWest";
}
} else {
if (b > 0) {
cout << "SouthEast";
} else {
cout << "SouthWest";
}
}
return 0;
}
T2 购票
题目描述
H 市 W 公园的门票分为单次票和年票,单次票的售价为 a 元,年票的售价为 b 元。若购买年票,则可以在今年无限次进入公园。
今年你想去 n 次 W 公园,你最少要花多少钱购买门票?
输入格式
输入一行三个由空格分隔的非负整数 n,a,b。
输出格式
输出一行一个整数,表示购买门票的最少花费。
输入输出样例
输入 #1
100 1 50
输出 #1
50
输入 #2
2 10 50
输出 #2
20
输入 #3复制
987654321 123456789 999999999999999999
输出 #3复制
121932631112635269
输入 #4复制
0 100 200
输出 #4复制
0
说明/提示
样例 1 解释
如果购买单次门票,则总花费为 100×1=100 元。
如果购买年票,则总花费为 50 元。
因此购买年票可以使总花费最少,最少花费为 50 元。
样例 2 解释
如果购买单次门票,则总花费为 2×10=20 元。
如果购买年票,则总花费为 50 元。
因此购买单次门票可以使总花费最少,最少花费为 20 元。
样例 3 解释
请注意答案可能超过 int 类型所能表示的范围。
样例 4 解释
输入的数据中可能含有 0。
数据范围与约定
对于全部数据,满足 0≤a,b,n≤1018。各测试点的详细数据范围见下表。
| 测试点 | 特殊性质 |
|---|---|
| 1∼12 | 0≤a,b,n≤104 |
| 13∼16 | 0≤a,b,n≤109 |
| 17∼20 | 无 |
思路
这道题其实是一道水题,只要你找到了方法。
题目描述:
小G有一排n台抽奖机,从第1台开始依次游玩。初始积分x。
对于第i台抽奖机,需要a_i积分才能玩,玩完后获得b_i积分(注意:玩之前需要满足当前积分>=a_i,玩之后积分变化:当前积分 = 当前积分 - a_i + b_i)。
游玩规则:
1. 从第1台开始,依次游玩。
2. 在游玩第i台之前,如果当前积分 < a_i,则停止游玩(并且不再游玩后面的)。
3. 在游玩第i台之后,如果当前积分 >= y,则停止游玩(不再游玩后面的)。
给定n, x, y,以及每台抽奖机的a_i和b_i,求小G停止游玩后拥有的积分数量。
输入格式:
第一行:n, x, y 接下来n行:每行两个正整数a_i, b_i 输出格式: 一个整数,表示最终积分。
注意:游玩是依次进行的,可能因为不够钱玩下一台而停止,也可能因为达到y分而提前停止。
示例:
假设n=2, x=10, y=100。
第一台:a1=5, b1=10 -> 游玩前10>=5,可以玩,玩后积分=10-5+10=15
第二台:a2=10, b2=100 -> 游玩前15>=10,可以玩,玩后积分=15-10+100=105,然后105>=y(100),停止。所以输出105。
另一种情况:
n=2, x=10, y=100 。
第一台:a1=5, b1=10 -> 玩后15
第二台:a2=20, b2=100 -> 当前15<20,所以不能玩第二台,停止。最终积分15。
因此,我们需要模拟过程:
当前积分 = x 从第一台到第n台,依次判断:
如果当前积分 < a_i:则停止,输出当前积分。
否则,玩这台抽奖机:当前积分 = 当前积分 - a_i + b_i
然后判断当前积分是否>=y,如果是,则停止,输出当前积分。
如果所有机器都玩完了,则输出最后的积分。
注意:题目要求是依次游玩,并且每台只能玩一次。
由于n最大是10^18,我们可以使用循环模拟。
代码步骤:
1. 读入n, x, y。
2. 用循环读入n组a_i和b_i,可以存储到两个数组,或者直接边读边处理(因为不需要重复使用,而且顺序处理)。
3. 初始化当前积分cur = x。
4. 遍历每一台抽奖机(i从0到n-1):
if cur < a_i: 则break跳出循环。
else: cur = cur - a_i + b_i
if cur >= y: break跳出循环
5. 输出cur。
但是注意:题目中在游玩后如果积分>=y则停止,所以先判断是否满足条件再决定是否继续。
考虑边界:可能一台都不能玩,那么直接输出x。
例如:n=1, x=0, a1=10 -> 不能玩,输出0。 因此,我们按上述模拟。
AC code:
#include <iostream>
using namespace std;
int main() {
long long n, a, b;
cin >> n >> a >> b;
if (a * n > b) {
cout << b << endl;
} else {
cout << a * n << endl;
}
return 0;
}
T3 百万富翁
题目描述
小 G 的梦想是成为百万富翁。
他面前有一排 n 台抽奖机,第 i 台抽奖机需要 ai 积分,游玩这台抽奖机将会获得 bi 积分。每台抽奖机只能游玩一次。
小 G 初始时有 x 积分,他从第 1 台抽奖机开始依次游玩(1,2,3,⋯)。
- 在游玩一台抽奖机后,如果小 G 的积分大于等于 y 分,小 G 就不会再游玩后面的抽奖机。
- 在游玩第 i 台抽奖机前,如果小 G 的积分 <ai,那么小 G 只能停止游玩,也不能再游玩后面的抽奖机。
给定 n,x,y,ai,bi,求小 G 在停止游玩后,他拥有的积分数量。
输入格式
第一行输入以空格分隔的三个正整数 n,x,y。
接下来 n 行,每行输入两个正整数,第 i 行输入的两个正整数分别为 ai,bi。
输出格式
输出一行一个整数表示小 G 在停止游玩后拥有的积分数量。
输入输出样例
输入 #1
5 10 100
1 1
2 1
3 1
4 1
5 1
输出 #1
4
输入 #2
10 50 1000000
1 100000
1 200000
1 300000
1 400000
1000000 1
1000000 1
1000000 1
1000000 1
1 1
1 1
输出 #2
1000046
输入 #3
8 50 50000000
10 20
10 20
10 20
10 20
10 20
10 20
10 20
10 20
输出 #3
130
说明/提示
样例 1 解释
小 G 初始时拥有 10 积分。
- 第 1 台抽奖机:花费 1 积分,获得 1 积分,小 G 现拥有 10 积分。
- 第 2 台抽奖机:花费 2 积分,获得 1 积分,小 G 现拥有 9 积分。
- 第 3 台抽奖机:花费 3 积分,获得 1 积分,小 G 现拥有 7 积分。
- 第 4 台抽奖机:花费 4 积分,获得 1 积分,小 G 现拥有 4 积分。
- 第 5 台抽奖机:需花费 5 积分,但小 G 现在只有 4 积分,小 G 停止游玩。
因此,小 G 最终剩余 4 积分。
样例 2 解释
注意小 G 在积分达到 y 后就会停止游玩。
数据范围与约定
对于全部数据,满足 1≤n≤105,1≤x<y≤109,1≤ai,bi≤109。各测试点的详细数据范围见下表。
| 测试点 | 特殊性质 |
|---|---|
| 1∼3 | n≤103 |
| 4∼9 | x≥∑ai |
| 10∼14 | ai≤bi |
| 15∼20 | 无 |
思路
这道题其实是一道水题,只要你找到了方法。
题目描述:
小G有一排n台抽奖机,从第1台开始依次游玩。初始积分x。
对于第i台抽奖机,需要a_i积分才能玩,玩完后获得b_i积分(注意:玩之前需要满足当前积分>=a_i,玩之后积分变化:当前积分 = 当前积分 - a_i + b_i)。
游玩规则:
1. 从第1台开始,依次游玩。
2. 在游玩第i台之前,如果当前积分 < a_i,则停止游玩(并且不再游玩后面的)。
3. 在游玩第i台之后,如果当前积分 >= y,则停止游玩(不再游玩后面的)。
给定n, x, y,以及每台抽奖机的a_i和b_i,求小G停止游玩后拥有的积分数量。
输入格式:
第一行:n, x, y
接下来n行:每行两个正整数a_i, b_i
输出格式:
一个整数,表示最终积分。
注意:游玩是依次进行的,可能因为不够钱玩下一台而停止,也可能因为达到y分而提前停止。
示例: 假设n=2, x=10, y=100
第一台:a1=5, b1=10 -> 游玩前10>=5,可以玩,玩后积分=10-5+10=15
第二台:a2=10, b2=100 -> 游玩前15>=10,可以玩,玩后积分=15-10+100=105,然后105>=y(100),停止。所以输出105。
另一种情况:n=2, x=10, y=100
第一台:a1=5, b1=10 -> 玩后15
第二台:a2=20, b2=100 -> 当前15<20,所以不能玩第二台,停止。
最终积分15。
因此,我们需要模拟过程:
当前积分 = x 从第一台到第n台,依次判断:
如果当前积分 < a_i:则停止,输出当前积分。
否则,玩这台抽奖机:
当前积分 = 当前积分 - a_i + b_i 然后判断当前积分是否>=y,如果是,则停止,输出当前积分。
如果所有机器都玩完了,则输出最后的积分。
注意:题目要求是依次游玩,并且每台只能玩一次。
我们可以使用循环模拟。
代码步骤:
1. 读入n, x, y。
2. 用循环读入n组a_i和b_i,可以存储到两个数组,或者直接边读边处理(因为不需要重复使用,而且顺序处理)。
3. 初始化当前积分cur = x。
4. 遍历每一台抽奖机(i从0到n-1):
if cur < a_i: 则break跳出循环。
else: cur = cur - a_i + b_i if cur >= y: break跳出循环
5. 输出cur。
但是注意:题目中在游玩后如果积分>=y则停止,所以先判断是否满足条件再决定是否继续。
考虑边界:可能一台都不能玩,那么直接输出x。
例如:n=1, x=0, a1=10 -> 不能玩,输出0。
因此,我们按上述模拟。
AC Code:
#include <iostream>
using namespace std;
int main() {
int n;
long long x, y;
cin >> n >> x >> y;
unsigned long long cnt = x;
int a[n + 10], b[n + 10];
for (int i = 0; i < n; i++) {
long long a, b;
cin >> a >> b;
if (cnt < a) {
break;
}
cnt = cnt - a + b;
if (cnt >= y) {
break;
}
}
cout << cnt << endl;
return 0;
}
T4 卡牌游戏
题目描述
小 G 手里有一副共 n 张卡牌,卡牌编号分别为 1∼n。
小 G 学会了洗牌操作:
- 首先,给出一个参数 k,将这副牌分为两堆:牌堆 A 从顶到底包含第 1 张到第 k 张牌,牌堆 B 从顶到底包含第 k+1 到第 n 张牌。
- 接下来,从牌堆 A 开始,轮流从两个牌堆中取出牌堆顶部的一张牌,放到新牌堆的底部,直到其中一个牌堆被抽完为止。
- 最后,将仍剩余卡牌的牌堆的所有牌按原顺序放到新牌堆的底部。
初始时,这副牌从顶到底第 i 张的编号为 ai,你需要对这副牌进行一次洗牌操作,并输出最终得到的牌堆从顶到底每一张牌的编号。
输入格式
第一行输入两个用空格分隔的正整数 n,k。
第二行输入 n 个用空格分隔的正整数,第 i 个输入的正整数表示当前牌堆中从顶到底第 i 张牌的卡牌编号。
保证输入的卡牌编号都是 1∼n 的正整数,且每个编号出现恰好一次。
输出格式
输出一行 n 个用空格分隔的正整数,表示洗牌后得到的牌堆从顶到底每一张牌的编号。
输入输出样例
输入 #1
6 2
1 2 3 4 5 6
输出 #1
1 3 2 4 5 6
输入 #2
7 1
1 5 2 3 6 7 4
输出 #2
1 5 2 3 6 7 4
输入 #3
12 6
10 7 9 5 11 6 12 8 4 3 2 1
输出 #3
10 12 7 8 9 4 5 3 11 2 6 1
说明/提示
样例 1 解释
首先将牌按 k 分成两堆:{1,2} 和 {3,4,5,6},分别称为牌堆 A 和牌堆 B。
轮流从两个牌堆中取出牌堆顶部的一张牌,放到新牌堆的底部:
- 第一次抽牌:
- 新牌堆:{}→{1}→{1,3}。
- 牌堆 A:{1,2}→{2}。
- 牌堆 B:{3,4,5,6}→{4,5,6}。
- 第二次抽牌:
- 新牌堆:{1,3}→{1,3,2}→{1,3,2,4}。
- 牌堆 A:{2}→{}。
- 牌堆 B:{4,5,6}→{5,6}。
此时牌堆 A 被抽完,将牌堆 B 剩余卡牌放到新牌堆的底部。
此时新牌堆:{1,3,2,4}→{1,3,2,4,5,6}。
样例 2 解释
此样例满足测试点 1∼6 的限制。
样例 3 解释
此样例满足测试点 7∼12 的限制。
数据范围与约定
对于全部数据,满足 1≤n≤2000,1≤k≤n。各测试点的详细数据范围见下表。
| 测试点 | n | 特殊性质 |
|---|---|---|
| 1∼4 | ≤100 | k=1 |
| 5∼8 | ≤100 | k=2n 且 n 为偶数 |
| 9∼12 | ≤2000 | k=2n 且 n 为偶数 |
| 13∼15 | ≤100 | 无 |
| 16∼20 | ≤2000 | 无 |
思路
这道题几乎是一道水题,只要你找到方法。
题目要求模拟洗牌过程:
1. 将牌分为两堆:
A堆(1~k张),B堆(k+1~n张)
2. 轮流取牌:先取A堆顶部一张,再取B堆顶部一张,交替进行,直到某一堆取完。
3. 将剩余的那一堆的牌全部按原顺序放到新牌堆底部。
输入:
第一行:n, k
第二行:n个正整数,表示初始牌堆从顶到底的编号(即第1张是顶,第n张是底)
输出:
洗牌后新牌堆从顶到底的编号(即新牌堆的第一张是顶,最后一张是底)
注意:我们使用两个数组(或队列)来模拟两个牌堆,但是注意题目描述中牌堆A和B的顶部分别是第1张和第k+1张。
具体步骤:
1. 将前k张牌放入A数组(作为A堆,数组的第一个元素是顶部,即index0是顶部)。
2. 将后n-k张牌放入B数组(同样,数组的第一个元素是顶部)。
3. 模拟交替取牌: 初始化一个新数组result。 用两个指针(或两个队列)分别指向A和B的当前位置(从0开始)。
交替取牌:先取A的当前顶部(指针位置)放入result,然后取B的当前顶部放入result,直到其中一个堆取完(即A的指针到达k或者B的指针到达n-k)。
4. 将剩余的那个堆的所有牌按顺序(从当前指针位置到数组末尾)添加到result的后面。 5. 输出result数组。
注意:题目中每个编号都是1~n且不重复。 由于n最大2000,直接模拟即可。
例如:
输入 n=5, k=2, 初始牌堆 [1,2,3,4,5] A = [1,2] (顶是1,底是2) B = [3,4,5] (顶是3,底是5)
交替取牌:
先取A的顶部1 -> result=[1]
再取B的顶部3 -> result=[1,3]
再取A的顶部2 -> result=[1,3,2]
再取B的顶部4 -> result=[1,3,2,4]
此时A堆已经取完,B堆还剩[5],将5放入result的底部 -> result=[1,3,2,4,5]
输出:1 3 2 4 5
另一个例子:n=5, k=3, 初始牌堆 [1,2,3,4,5]
A = [1,2,3] B = [4,5] 交替取牌:
取A:1 -> result=[1]
取B:4 -> result=[1,4]
取A:2 -> result=[1,4,2]
取B:5 -> result=[1,4,2,5]
A堆还剩[3],将3放入result底部 -> result=[1,4,2,5,3]
输出:1 4 2 5 3
因此,我们按照上述步骤编写代码。
AC Code:
#include <iostream>
#include <vector>
using namespace std;
int main() {
int n, k;
cin >> n >> k;
vector<int> card(n);
for (int i = 0; i < n; i++) {
cin >> card[i];
}
vector<int> v1(card.begin(), card.begin() + k);
vector<int> v2(card.begin() + k, card.end());
vector<int> ans;
int i = 0, j = 0;
while (i < v1.size() && j < v2.size()) {
ans.push_back(v1[i++]);
ans.push_back(v2[j++]);
}
while (i < v1.size()) {
ans.push_back(v1[i++]);
}
while (j < v2.size()) {
ans.push_back(v2[j++]);
}
for (int idx = 0; idx < n; idx++) {
cout << ans[idx] << " ";
}
return 0;
}
T5 地铁计费
题目描述
S 市地铁一号线共有 n 个车站,这些车站按由起点站到终点站的顺序分别编号为 1∼n。
S 市地铁的计费规则如下:
- 一个收费区是一段包含若干连续车站的子段,整条线路被不重不漏地划分成了若干收费区,即,所有车站都在恰好一个收费区内。
- 在同一车站进站和出站,收费 1 元。
- 乘车起点和终点是同一收费区内不同车站的,收费 2 元。
- 否则,若乘车起点和终点之间包含了 m 个完整收费区,则收费 2+m 元。具体地,设车程的两个端点车站分别为 a,b (a<b),则满足 a≤lx≤rx≤b 的收费区 x 的数量即为 m,其中 lx,rx 是收费区 x 的左右端点。
收费区如下定义:
- 给出 k+1 个分界点 1=p0<p1<p2<…<pk=n+1,则第 i 个收费区包含所有满足 pi−1≤x<pi 的车站 x。即收费区 i 的左右端点分别为 li=pi−1 和 ri=pi−1。
你需要回答 q 次询问,每次询问从车站 i 到车站 j 的收费。
输入格式
第一行两个由空格分隔的正整数 n,k。
第二行 k+1 个由空格分隔的正整数,表示分界点。第 i 个输入的正整数表示 pi−1。
第三行一行一个整数 q。
接下来 q 行,每行输入两个正整数 i,j,表示一次询问。
输出格式
对于每组询问,输出一行一个整数表示答案。
输入输出样例
输入 #1
10 4
1 3 5 7 11
6
2 2
1 3
1 4
10 1
6 9
3 4
输出 #1
1
3
4
6
2
2
输入 #2
5 5
1 2 3 4 5 6
3
1 1
1 3
2 5
输出 #2
1
5
6
输入 #3
6 2
1 3 7
5
1 3
2 5
5 5
1 6
4 5
输出 #3
3
2
1
4
2
说明/提示
样例 1 解释
按照题目中的定义,我们将线路中的 10 个车站划分为 k=4 个收费区:
- 收费区 1:包含车站 1,2。
- 收费区 2:包含车站 3,4。
- 收费区 3:包含车站 5,6。
- 收费区 4:包含车站 7,8,9,10。
考虑各个询问:
| 询问编号 | 出发站 | 到达站 | 车费 | 解释 |
|---|---|---|---|---|
| 1 | 2 | 2 | 1 元 | 同站进出,收费 1 元 |
| 2 | 1 | 3 | 3 元 | 1,3 两站之间包含收费区 1 中所有车站,收费 2+1=3 元 |
| 3 | 1 | 4 | 4 元 | 1,4 两站之间包含收费区 1,2 中所有车站,收费 2+2=4 元 |
| 4 | 10 | 1 | 6 元 | 1,10 两站之间包含收费区 1,2,3,4 中所有车站,收费 2+4=6 元 |
| 5 | 6 | 9 | 2 元 | 6,9 两站之间没有包含任何一个收费区中所有的车站,收费 2+0=2 元 |
| 6 | 3 | 4 | 2 元 | 3,4 两站均属收费区 2,收费 2 元 |
样例 2 解释
此样例满足 k=n 的限制。
样例 3 解释
此样例满足 k=2 的限制。
数据范围与约定
对于全部数据,满足 1≤k≤1000,1≤n≤109,k≤n,1≤q≤105。各测试点的详细数据范围见下表。
| 测试点 | n | q | 特殊性质 |
|---|---|---|---|
| 1∼2 | ≤1000 | ≤1000 | A |
| 3∼4 | ≤1000 | ≤1000 | B |
| 5∼7 | ≤1000 | ≤1000 | 无 |
| 8∼10 | ≤1000 | ≤105 | 无 |
| 11∼13 | ≤105 | ≤1000 | 无 |
| 14∼15 | ≤109 | ≤105 | C |
| 16∼20 | ≤109 | ≤105 | 无 |
特殊性质 A:保证 k=n。
特殊性质 B:保证 k=2。
特殊性质 C:保证 n 是 k 的倍数且所有收费区大小相等。
思路
这道题差不多是一道水题,只要你找到方法。
问题重述:
S市地铁一号线有n个车站,编号为1到n。线路被划分为k个连续的收费区,每个收费区包含一段连续的车站。收费区的定义由k+1个分界点给出:1 = p0 < p1 < p2 < ... < pk = n+1。第i个收费区包含的车站x满足 p_{i-1} ≤ x ≤ p_i - 1。
收费规则:
-
如果进站和出站是同一个车站,收费1元。
-
如果起点和终点在同一个收费区内(但不是同一个车站),收费2元。
-
否则,收费为2 + m元,其中m是乘车过程中经过的完整收费区的个数。完整收费区是指整个收费区完全包含在起点和终点之间。
需要处理q次询问,每次询问给出起点站i和终点站j,计算乘车费用。
解决思路:
-
收费区存储:首先,根据分界点p0到pk,存储每个收费区的左右端点。收费区i的左右端点为:
-
左端点 L[i] = p[i]
-
右端点 R[i] = p[i+1] - 1
-
-
询问处理:对于每个询问(i, j),设s = min(i, j),t = max(i, j)(因为方向不影响费用)。
-
如果s == t,费用为1元。
-
否则,找到s和t所在的收费区idx_s和idx_t:
-
idx_s是满足 L[i] ≤ s ≤ R[i] 的收费区索引。
-
idx_t是满足 L[i] ≤ t ≤ R[i] 的收费区索引。
-
如果idx_s == idx_t,费用为2元。
-
-
否则,计算完整包含在[s, t]内的收费区数量m:
-
这些收费区满足 L[i] ≥ s 且 R[i] ≤ t。
-
由于收费区是按顺序排列的,可以用二分查找快速计算m。
-
-
费用为2 + m元。
-
-
二分查找优化:
-
使用
upper_bound找到s和t所在的收费区。 -
使用
lower_bound和upper_bound找到满足 L[i] ≥ s 和 R[i] ≤ t 的收费区范围,计算m。
-
AC Code:
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main() {
long long n;
int k;
cin >> n >> k;
vector<long long> p(k + 1);
for (int i = 0; i <= k; i++) {
cin >> p[i];
}
vector<long long> l(k), r(k);
for (int i = 0; i < k; i++) {
l[i] = p[i];
r[i] = p[i + 1] - 1;
}
int q;
cin >> q;
while (q--) {
long long i, j;
cin >> i >> j;
long long s = min(i, j);
long long t = max(i, j);
if (s == t) {
cout << 1 << endl;
continue;
}
auto poss = upper_bound(l.begin(), l.end(), s);
int ids = poss - l.begin() - 1;
auto post = upper_bound(l.begin(), l.end(), t);
int idt = post - l.begin() - 1;
if (ids == idt) {
cout << 2 << endl;
continue;
}
int lidx = lower_bound(l.begin(), l.end(), s) - l.begin();
auto rp = upper_bound(r.begin(), r.end(), t);
int ridx = (rp - r.begin()) - 1;
long long m = 0;
if (lidx <= ridx) {
m = ridx - lidx + 1;
}
cout << 2 + m << endl;
}
return 0;
}
T6 代数瓜子式
题目描述
给定一个 n×n 的数组 A,其第 i 行第 j 列上的元素为 Ai,j。
现选定 k 行 k 列从 A 中删除,其它元素的相对位置不变。设删除后得到的数组为 B,则 B 的大小为 (n−k)×(n−k)。
对于被删除的 k 行和 k 列,将交点处的元素按原相对顺序构成一个新数组 C。
例如,给定 4×4 数组 A,删除第 1,3 行和 3,4 列,具体过程如下:
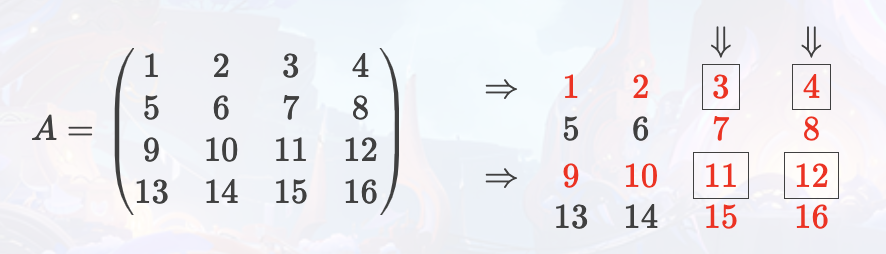
如上,被删除的行、列用双箭头标出。未被标记的元素没有被删除。被标记为红色的元素将被删除。被方框框住的元素即为被删除的行、列交点处的元素。因此,
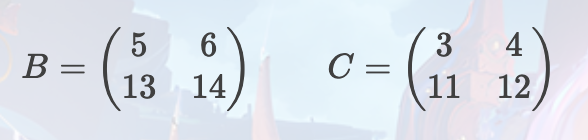
定义一个对于 m×m 数组的运算 f 为数组的正对角线上各元素之积减去反对角线上各元素之积。其中,第 i 行第 i 列上的元素在正对角线上,第 i 行第 m−i+1 列的元素在反对角线上。
例如:

如上,红色表示该元素在正对角线上,绿色表示该元素在反对角线上,蓝色表示该元素既在正对角线上,又在反对角线上。
对于 n×n 数组 A 和删除的 k 行 k 列,定义代数瓜子式为 f(B)×f(C) 的值。其中数组 B,C 和运算 f 的定义如上。
现给定 n×n 数组 A,q 次询问若删除给定的 k 行 k 列,所得代数瓜子式对 (109+7) 取模的值。
这里的“取模”后的值总是为非负数。如果你正在使用 C++ 编写代码,你可以使用以下方法取模:
const int mod = 1000000007;
......
// 在某次运算中,假设要对 ans 变量取模
ans = ((ans % mod) + mod) % mod;
......
输入格式
第一行输入两个以空格分隔的正整数 n,q。
接下来 n 行,每行输入 n 个以空格分隔的整数,表示数组 A。
接下来 q 行,每行一组询问,询问格式如下:
- 首先输入一个正整数 k,表示删除的行、列的数量。
- 接下来按递增顺序输入 k 个互不相同的正整数,表示要删除的行的编号。
- 接下来按递增顺序输入 k 个互不相同的正整数,表示要删除的列的编号。
输出格式
对于每组询问,输出一行一个整数表示答案。
输入输出样例
输入 #1
4 2
1 2 3 4
5 6 7 8
9 10 11 12
13 14 15 16
2 1 3 3 4
2 2 3 1 2
输出 #1
64
48
输入 #2
4 3
1 2 3 4
5 6 7 8
9 10 11 12
13 14 15 16
1 1 1
1 2 4
3 1 2 3 2 3 4
输出 #2
0
0
0
输入 #3
5 7
3 1 4 1 5
9 2 6 5 3
5 3 5 8 9
7 9 3 2 3
8 4 6 2 6
2 1 2 3 4
3 1 2 3 2 3 4
2 1 3 1 3
3 1 3 5 1 3 5
2 1 4 3 5
3 1 3 4 2 4 5
1 1 1
输出 #3
999994715
540
0
4510
198
999997991
0
说明/提示
样例 1 解释
此样例的第一组询问即为题目描述中的例子。
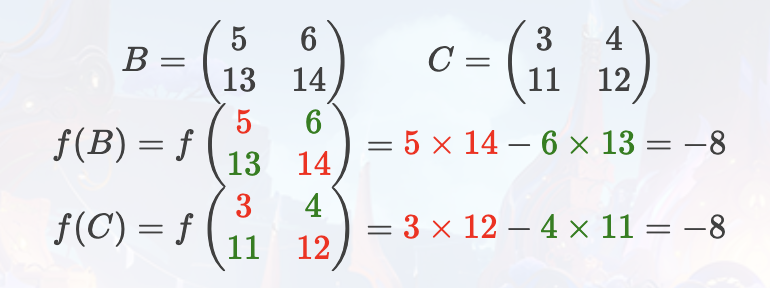
则代数瓜子式的值为 f(B)×f(C)=64。
对于第二组询问,有:
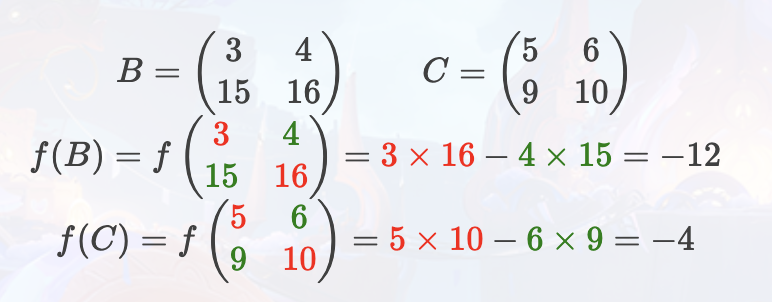
则代数瓜子式的值为 f(B)×f(C)=48。
样例 2 解释
注意对于所有 1×1 数组 A,都有 f(A)=0,因此该样例的每一组输出均为 0。
样例 3 解释
请注意输出答案对 (109+7) 取模的值。
此样例的第 1,2 组询问满足特殊性质 C。
此样例的第 3,4 组询问满足特殊性质 B。
此样例的第 1,3,5 组询问满足特殊性质 A。
数据范围与约定
对于全部数据,满足 1≤k<n≤600,1≤q≤600,0≤Ai,j<105。各测试点的详细数据范围见下表。
| 测试点 | n | q | 特殊性质 |
|---|---|---|---|
| 1∼4 | ≤100 | ≤100 | 无 |
| 5∼8 | ≤600 | ≤600 | A |
| 9∼11 | ≤600 | ≤600 | B |
| 12∼14 | ≤600 | ≤600 | C |
| 15∼20 | ≤600 | ≤600 | 无 |
特殊性质 A:保证 k=2。
特殊性质 B:保证第 i 行和第 i 列要么被同时删除,要么都不删除。
特殊性质 C:保证被删除的行、列的交恰好为原数组的一个子数组。
思路
这道题不是一道水题,除非你找到方法。
为了解决这个问题,我们需要高效地处理多次查询,每次查询涉及删除给定的k行k列后,计算剩余矩阵B和被删除行列交点矩阵C的特定函数值,并求它们的乘积模 10^9+7。由于直接构建矩阵B和C会导致较高的时间复杂度,我们采用了一种更高效的方法,通过预处理和直接计算关键元素来避免显式构建矩阵。
-
问题分析:给定一个 n×n矩阵 A,每次查询指定删除 k 行和 k 列。我们需要计算:
-
剩余矩阵 B(大小为 (n−k)×(n−k))的主对角线和副对角线元素的乘积之差 f(B)。
-
被删除行列交点矩阵 C(大小为 k×k)的主对角线和副对角线元素的乘积之差 f(C)。
-
最终结果为 f(B)×f(C)mod (10^9+7)。
-
-
关键观察:
-
矩阵 B 的主对角线元素在原始矩阵 A 中的位置为剩余行和剩余列相同索引的元素。
-
矩阵 B 的副对角线元素在原始矩阵 A 中的位置为剩余行和剩余列逆序索引的元素。
-
矩阵 C 的主对角线元素为被删除行和被删除列相同索引的元素。
-
矩阵 C 的副对角线元素为被删除行和被删除列逆序索引的元素。
-
-
高效计算:
-
使用布尔数组标记被删除的行和列,然后生成剩余行和剩余列的索引数组。
-
通过遍历索引数组,直接计算 BB 和 CC 的主对角线和副对角线元素的乘积(模 10^9+7)。
-
计算 f(B) 和 f(C)并求它们的乘积模 10^9+7。
-
-
复杂度优化:每次查询的时间复杂度为 O(n),其中 n 是矩阵的维度。总时间复杂度为 O(q×n),对于 n≤600 和 q≤600 是可行的。
AC Code:
#include <iostream>
#include <cstdio>
#include <cstring>
using namespace std;
const int mod = 1000000007;
const int maxn = 605;
int A[maxn][maxn];
bool row[maxn], col[maxn];
int T_arr[maxn], U_arr[maxn];
int row_glo[maxn], col_glo[maxn];
int main() {
int n, q;
scanf("%d %d", &n, &q);
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
scanf("%d", &A[i][j]);
}
}
while (q--) {
memset(row, 0, sizeof(row));
memset(col, 0, sizeof(col));
int k;
scanf("%d", &k);
for (int i = 0; i < k; i++) {
int r;
scanf("%d", &r);
r--;
row_glo[i] = r;
row[r] = true;
}
for (int i = 0; i < k; i++) {
int c;
scanf("%d", &c);
c--;
col_glo[i] = c;
col[c] = true;
}
int cntT = 0;
for (int i = 0; i < n; i++) {
if (!row[i]) {
T_arr[cntT++] = i;
}
}
int cntU = 0;
for (int i = 0; i < n; i++) {
if (!col[i]) {
U_arr[cntU++] = i;
}
}
long long P1 = 1, P2 = 1, P3 = 1, P4 = 1;
int sizeB = n - k;
for (int i = 0; i < sizeB; i++) {
P1 = (P1 * A[T_arr[i]][U_arr[i]]) % mod;
}
for (int i = 0; i < sizeB; i++) {
P2 = (P2 * A[T_arr[i]][U_arr[sizeB - 1 - i]]) % mod;
}
for (int i = 0; i < k; i++) {
P3 = (P3 * A[row_glo[i]][col_glo[i]]) % mod;
}
for (int i = 0; i < k; i++) {
P4 = (P4 * A[row_glo[i]][col_glo[k - 1 - i]]) % mod;
}
long long fB = (P1 - P2 + mod) % mod;
long long fC = (P3 - P4 + mod) % mod;
long long ans = (fB * fC) % mod;
printf("%lld\n", ans);
}
return 0;
}// When I was working on this problem, I got zero points, so I made some changes, but I'm not sure if it's correct qwq...
T7 LZW压缩
题目描述
LZW 压缩是一种非常著名且广泛使用的无损数据压缩算法。
以下是 LZW 压缩算法的流程:
†:在本题中,字典 D 是一个结构体数组。其中,每个结构体内存储了两个变量 S,x,意为正整数编码 x 可以代表字符串 S。
例如,对字符串 ABABABA 进行 LZW 压缩的流程如下:
初始字典 D:{A,1},{B,2}。
| P | c | P+c | P+c 是否在 D 中 | 输出 | 新增字典条目 | P 更新为 |
|---|---|---|---|---|---|---|
| 空串 | A | A | 是 | A | ||
A | B | AB | 否 | 1 | {AB,3} | B |
B | A | BA | 否 | 2 | {BA,4} | A |
A | B | AB | 是 | AB | ||
AB | A | ABA | 否 | 3 | {ABA,5} | A |
A | B | AB | 是 | AB | ||
AB | A | ABA | 是 | ABA | ||
ABA | 结束 | 5 |
则 ABABABA 的 LZW 压缩结果为 1 2 3 5。
现给出字符串 S 和初始字典 D,请对 S 进行 LZW 压缩,并输出执行完 LZW 压缩后的字典。
输入格式
第一行输入两个整数 n,k,s,表示字符串 S 的长度、初始字典 D 的大小,且字符集为前 s 个大写英文字母。
接下来 k 行,每行输入一个字符串,表示字典中的一个条目,输入的第 i 个字符串对应的编号为 i。保证前 s 个大写英文字母一定在字典中出现,且这 s 个条目一定是前 s 个给出的。
接下来一行一个字符串 S
输出格式
第一行输出若干个由空格分隔的正整数,表示 S 经 LZW 压缩后的结果。
第二行输出一行一个正整数 k,表示字典 D 的大小。
接下来 k 行,每一行输出一个字符串,表示字典 D 的各个条目。你应当按编号从小到大的顺序输出,即你输出的第 i 个字符串对应的编号应为 i。
输入输出样例
输入 #1
7 2 2
A
B
ABABABA
输出 #1
1 2 3 5
5
A
B
AB
BA
ABA
输入 #2
25 1 1
A
AAAAAAAAAAAAAAAAAAAAAAAAA
输出 #2
1 2 3 4 5 6 4
7
A
AA
AAA
AAAA
AAAAA
AAAAAA
AAAAAAA
输入 #3
19 6 6
A
B
C
D
E
F
ACBECDFCAACBECDACBE
输出 #3
1 3 2 5 3 4 6 3 1 7 9 11 16 5
19
A
B
C
D
E
F
AC
CB
BE
EC
CD
DF
FC
CA
AA
ACB
BEC
CDA
ACBE
说明/提示
样例 1 解释
此样例即为题目描述中的例子。
注意在输出字典的条目时,需要将输入的字典条目一并输出。
样例 2 解释
此样例满足特殊性质 AB。
数据范围与约定
对于全部数据,满足 1≤n,k≤3000,1≤s≤26。D 中所有字符串的长度总和不超过 n,且 D 中没有重复的字符串。保证前 s 个大写英文字母一定在字典中出现,且这 s 个条目分别使用编码 1∼s。各测试点的详细数据范围见下表。
| 测试点 | n,k | 特殊性质 |
|---|---|---|
| 1∼3 | ≤600 | A |
| 4∼7 | ≤1000 | 无 |
| 8∼9 | ≤2000 | B |
| 10∼13 | ≤2000 | C |
| 14∼17 | ≤2000 | 无 |
| 18∼20 | ≤3000 | 无 |
特殊性质 A:保证 s=1。
特殊性质 B:保证 k=s。
特殊性质 C:保证字符串 s 为随机生成。
思路
这道题不是道水题,除非你找到方法。
本题要求实现LZW压缩算法,对输入字符串进行压缩,并输出压缩后的编码序列和最终的字典。初始字典包含k个条目,字符集为前s个大写字母。压缩过程中需要动态扩展字典。
-
初始化字典:读取初始字典,使用哈希表(或字典结构)存储字符串到编码的映射。
-
压缩过程:
-
初始化当前字符串P为空。
-
遍历输入字符串S的每个字符c:
-
检查P + c是否在字典中:
-
若存在,则更新P = P + c。
-
若不存在,则输出P的编码,将P + c添加到字典(编号为当前字典大小+1),并重置P = c。
-
-
-
-
输出结果:最后输出P的编码,并打印最终的字典内容。
AC Code:
#include <iostream>
#include <string>
#include <vector>
#include <unordered_map>
using namespace std;
int main() {
int n, k, s;
cin >> n >> k >> s;
unordered_map<string, int> dict;
vector<string> a;
for (int i = 0; i < k; ++i) {
string str;
cin >> str;
a.push_back(str);
dict[str] = i + 1;
}
string s1;
cin >> s1;
vector<int> com;
string p;
for (char c : s1) {
string pc = p + c;
if (dict.count(pc)) {
p = pc;
} else {
com.push_back(dict[p]);
dict[pc] = dict.size() + 1;
a.push_back(pc);
p = string(1, c);
}
}
if (!p.empty()) {
com.push_back(dict[p]);
}
for (int code : com) {
cout << code << " ";
}
cout << endl;
cout << dict.size() << endl;
for (int i = 0; i < a.size(); ++i) {
cout << a[i] << endl;
}
return 0;
}
T8 讨论间预约
题目描述
N 大学图书馆中的讨论间采用预约制,你需要实现一个预约系统。
预约规则如下:
- 每人每次只能预约 1 间讨论间,每次预约时长不得超过 2 小时。
- 任何一间讨论间同时只能被 1 人预约。
- 任何人的预约时间段不能和自己的其它有效预约的时间段重合。
若某次预约的预约时长超过 2 小时,或和预约人自己已有的、未被取消的预约重合,则预约人将被记录一次违规。
- 若某人被记录 2 次违规,则取消该人之前的所有预约。
- 若某人被记录 3 次违规,则取消该人之前的所有预约,且该人之后的预约都将被拒绝。
预约按如下格式给出:
reserve <StudentID> <RoomID> <StartTime> <Duration>
<StudentID>是一个整数,保证其在 [100,999] 之间,表示预约者的学号。<RoomID>是一个整数,保证其在 [100,999] 之间,表示预约的讨论间编号。<StartTime>是一个字符串,以HH:MM给出,表示开始时间为HH时MM分,位数不够时前补零。保证这是一个合法时间。<Duration>是一个整数,保证其在 [1,999] 之间,表示预约的使用时长,以分钟计。
在收到预约后,你需要判断预约是否符合上述条件,如果不符合条件,则输出 FAIL,否则输出 SUCCESS <x>,其中 <x> 表示预约编号,该值等于在本次预约之前的曾经成功过的预约数(成功后取消的也计入)。
取消预约按如下格式给出:
cancel <x>
- 其中
<x>表示预约编号。意为取消预约编号为<x>的预约。
在收到取消预约请求后,如果该预约已经被取消过,则输出 FAIL,否则输出 SUCCESS。
输入格式
第一行输入一个整数 n 表示操作个数。
接下来 n 行,每行输入一个操作,操作的输入格式如题目描述中所述。
输出格式
对于每个操作,输出一行表示结果。结果的输出格式如题目描述中所述。
输入输出样例
输入 #1
7
reserve 201 101 07:00 120
reserve 201 102 08:00 120
reserve 202 101 08:00 120
reserve 202 102 09:00 120
reserve 201 102 09:00 60
cancel 2
reserve 201 102 09:00 60
输出 #1
SUCCESS 1
FAIL
FAIL
SUCCESS 2
FAIL
SUCCESS
SUCCESS 3
输入 #2
4
reserve 201 101 09:00 180
reserve 201 101 09:00 120
reserve 201 102 10:00 120
reserve 202 101 09:00 120
输出 #2
FAIL
SUCCESS 1
FAIL
SUCCESS 2
输入 #3
15
reserve 111 222 00:00 120
reserve 111 333 01:00 1
reserve 111 444 02:00 120
reserve 111 555 01:59 1
cancel 1
reserve 222 444 03:00 60
reserve 111 222 00:00 120
cancel 4
reserve 111 444 03:00 120
reserve 111 456 23:59 120
reserve 111 123 23:00 60
reserve 222 456 23:59 120
reserve 111 101 10:00 120
cancel 5
cancel 6
输出 #3
SUCCESS 1
FAIL
SUCCESS 2
FAIL
FAIL
SUCCESS 3
SUCCESS 4
SUCCESS
FAIL
SUCCESS 5
FAIL
SUCCESS 6
FAIL
FAIL
SUCCESS
说明/提示
样例 1 解释
- 第 2 次操作中,学生 201 的预约和自己在第 1 次预约的时段重合,因此预约失败,并记录一次违规。
- 第 3 次操作中,由于学生 201 已经预定在 07:00∼09:00 使用讨论间 101,存在时间重合,因此预约失败。由于学生 202 不是和自己的预约冲突,因此不会被记录违规。
- 第 5 次操作中,由于学生 202 已经预定在 09:00∼11:00 使用讨论间 102,存在时间重合,因此预约失败。本次操作同样不会被记录违规。
- 第 7 次操作中,由于预约 2(第 6 次操作)已被撤销,因此可以顺利预约。请注意虽然本次预约的开始时间(09:00)和预约 1(第 1 次操作)的结束时间在同一时刻,但不认为这两次预约之间存在重合。
样例 2 解释
由于学生 201 在第 1,3 两次操作中违规,因此第 2 次操作中成功的预约被自动撤销。
数据范围与约定
对于全部数据,满足 1≤n≤105。各测试点的详细数据范围见下表。
| 测试点 | n | 特殊性质 |
|---|---|---|
| 1∼3 | ≤500 | AC |
| 4∼5 | ≤500 | 无 |
| 6∼8 | ≤2000 | A |
| 9∼11 | ≤2000 | B |
| 12∼13 | ≤2000 | C |
| 14∼17 | ≤2000 | 无 |
| 18∼19 | ≤105 | C |
| 20∼25 | ≤105 | 无 |
特殊性质 A:每个人最多进行 2 次预约。
特殊性质 B:每个人最多进行 3 次预约。
特殊性质 C:没有取消操作。
思路
这道题不是一道水题,除非你找到方法。
本题需要实现一个图书馆讨论间预约系统,处理预约和取消预约请求,并根据规则判断是否违规。关键点包括:
-
预约规则:
-
每人每次只能预约1个讨论间,时长≤2小时。
-
讨论间同一时间只能被1人预约。
-
个人预约时间段不能重叠。
-
-
违规处理:
-
违规2次:取消所有预约。
-
违规3次:取消所有预约并拒绝后续预约。
-
-
操作类型:
-
reserve <StudentID> <RoomID> <StartTime> <Duration> -
cancel <x>(x为预约编号)
-
解题思路:
-
数据结构设计:
-
使用哈希表存储学生信息和讨论间预约情况。
-
每个学生记录其预约列表和违规次数。
-
每个讨论间记录其被预约的时间段。
-
-
预约处理:
-
检查时长是否超过2小时。
-
检查讨论间是否被占用。
-
检查学生是否有时间冲突的预约。
-
-
取消预约:
-
检查预约是否存在或已被取消。
-
更新讨论间和学生信息。
-
-
违规处理:
-
根据违规次数执行相应操作。
-
AC Code:
#include <iostream>
#include <vector>
#include <unordered_map>
#include <string>
#include <algorithm>
using namespace std;
struct Res {
int id;
int sid;
int rid;
string st;
int dur;
bool cancelled;
};
unordered_map<int, vector<Res>> sMap;
unordered_map<int, vector<Res>> rMap;
unordered_map<int, int> vMap;
vector<Res> allRes;
int cnt = 0;
int toMin(const string& t) {
int h = stoi(t.substr(0, 2));
int m = stoi(t.substr(3, 2));
return h * 60 + m;
}
bool overlap(int s1, int e1, int s2, int e2) {
return !(e1 <= s2 || e2 <= s1);
}
bool check(const Res& r) {
if (r.dur > 120) return false;
int s = toMin(r.st);
int e = s + r.dur;
for (const auto& x : rMap[r.rid]) {
if (x.cancelled) continue;
int xs = toMin(x.st);
int xe = xs + x.dur;
if (overlap(s, e, xs, xe)) return false;
}
for (const auto& x : sMap[r.sid]) {
if (x.cancelled) continue;
int xs = toMin(x.st);
int xe = xs + x.dur;
if (overlap(s, e, xs, xe)) return false;
}
return true;
}
void reserve(const Res& r) {
if (vMap[r.sid] >= 3) {
cout << "FAIL\n";
return;
}
if (!check(r)) {
vMap[r.sid]++;
if (vMap[r.sid] == 2) {
for (auto& x : sMap[r.sid]) x.cancelled = true;
} else if (vMap[r.sid] == 3) {
for (auto& x : sMap[r.sid]) x.cancelled = true;
}
cout << "FAIL\n";
return;
}
allRes.push_back(r);
sMap[r.sid].push_back(r);
rMap[r.rid].push_back(r);
cnt++;
cout << "SUCCESS\n";
}
void cancel(int x) {
if (x < 1 || x > allRes.size()) {
cout << "FAIL\n";
return;
}
Res& r = allRes[x - 1];
if (r.cancelled) {
cout << "FAIL\n";
return;
}
r.cancelled = true;
cout << "SUCCESS\n";
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
int n;
cin >> n;
cin.ignore();
while (n--) {
string cmd, line;
getline(cin, line);
size_t pos = line.find(' ');
if (pos != string::npos) {
cmd = line.substr(0, pos);
line = line.substr(pos + 1);
} else {
cmd = line;
}
if (cmd == "reserve") {
int sid, rid, dur;
string st;
size_t p1 = line.find(' ');
sid = stoi(line.substr(0, p1));
size_t p2 = line.find(' ', p1 + 1);
rid = stoi(line.substr(p1 + 1, p2 - p1 - 1));
size_t p3 = line.find(' ', p2 + 1);
st = line.substr(p2 + 1, p3 - p2 - 1);
dur = stoi(line.substr(p3 + 1));
Res r{cnt + 1, sid, rid, st, dur, false};
reserve(r);
} else if (cmd == "cancel") {
int x = stoi(line);
cancel(x);
}
}
return 0;
}// Since it was already 21:00 when I tried to submit this problem, the submission didn't go through, so I don't know if the code is correct or not.
这就是[LGR-233-Div.4]洛谷入门赛#378道题的全部内容,喜欢的话不忘一键三连哦~
(求求各位大佬了,互联网这一行都是靠你们的三连关煮呀awa)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









