




Task11:第六章 大模型训练流程实践
为啥会有这一篇,希望大家明白前因后果,帮助更好理解现在流行的框架。
接task10,每训一个大模型每个组件都自己写代码,显然不合适。
原因如下:
- 麻烦
- 各个模型之间不一定通用、参数可能没法移植
- 自己写的分布式训练也不好搞
所以,机智的开源社区给出了LLM相关的
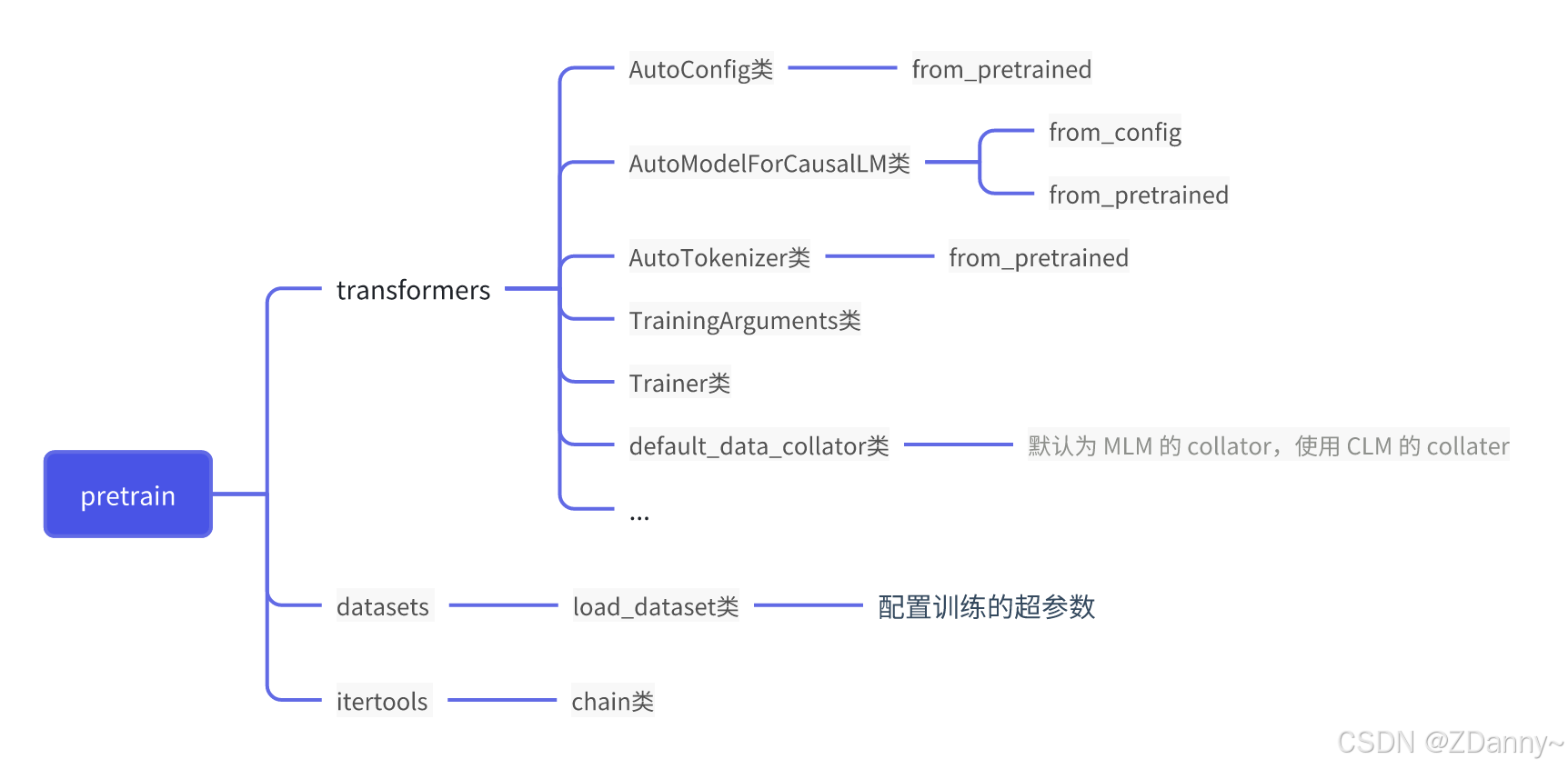
- 主流训练框架Transformers——进行模型的pretrain、sft
- 分布式框架deepseed
- 高效微调框架peft
what Transformers框架?
框架介绍
Transformers框架 ≠ Transformer结构
它是hugging face开发的,
- 模块化组件,就可以支持拼拼凑凑出主流模型架构,如BERT、GPT等,
AutoModel类 - 内置
Trainer类,封装分布式训练(pytorch原生的DDP、DeepSeed、Megatron-LM等训练策略)的核心逻辑 + 简单配置训练参数——数据/模型/流水线并行
ps:8卡A100集群就可以10+B参数训练 - 可实现训练过程
自动化管理,(os:不然训那么久还要一直看着,太可怕了)配合SavingPolicy 和 LoggingCallback 等组件
咱今天来逛三园(拥抱脸)
逛的什么园,hugging face园(os:给大家来段贯口)
三园里面有什么?
- 数亿 pretrain 的
模型参数 - 25w+ 不同类型
数据集 - 搭好的(pretrain模型+data+eval函数)框架
(os:这意味着什么你知道吗?那就是你要换哪个开源LLM、用什么data都可以,“随便放随便训”,也没那么随便其实hh)
目前比较多的LLM工作
要知道
- 训一个pretrain不容易(费时费钱费资源),所以
post-train和SFT就很多,基模然后调一调满足下游业务才是真正的落地 - 就算是大款,LLM的 para 也很大,所以像
deepspeed等分布式训练框架老必备技能了
how Transformers 自定义 LLM(训参数)?
即,通过 Transformers 框架实现 LLM 的 Pretrain 及 SFT
这里讲的是从只有某个模型框架(参数是随机数)到模型参数pretrain填好,再到SFT监督微调的阶段
1.初始化一个 LLM + tokenizer
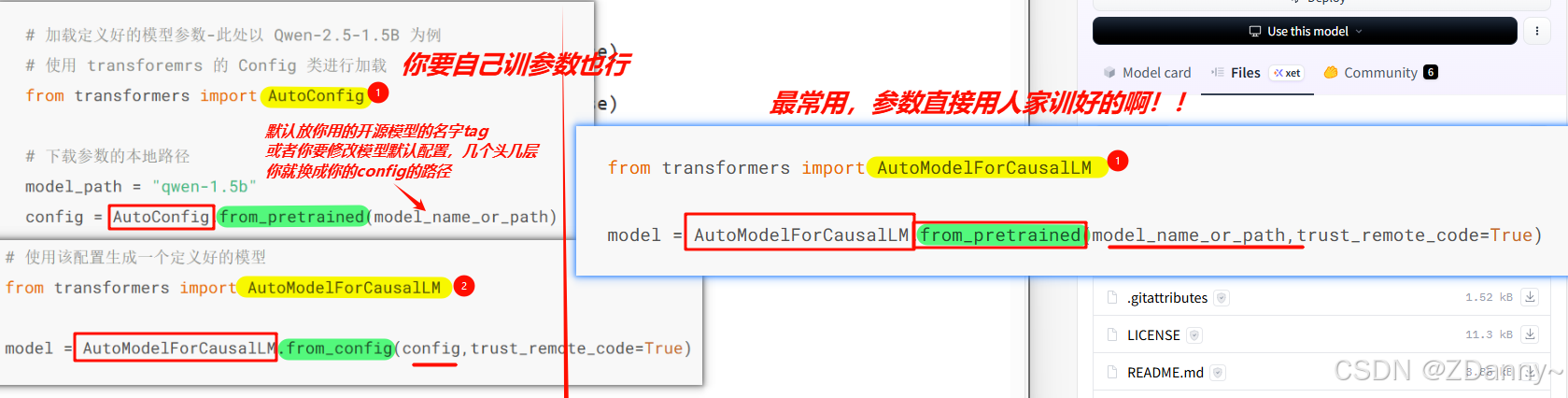
有两种,以CausalLM——Qwen-2.5-1.5B 为例(ps:因果LLM,就是用CLM任务训的LLM,前面预测下一个词)
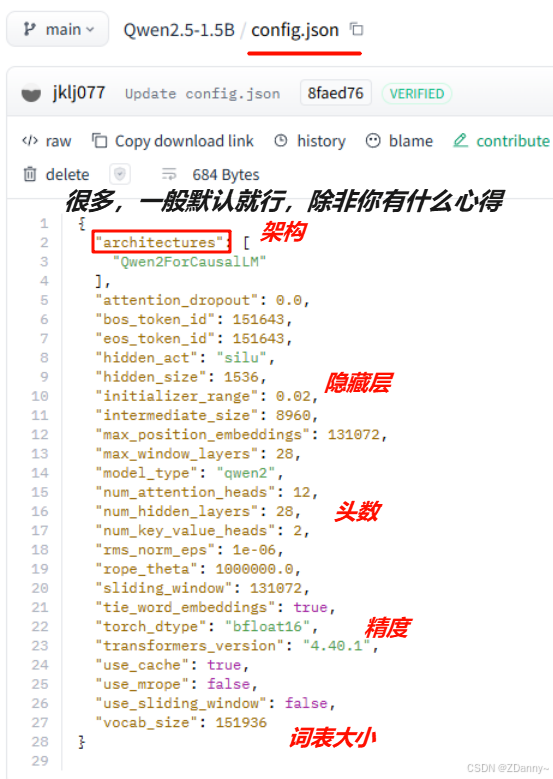
用到的类:AutoModelForCausalLM、AutoConfig
- 直接加载一个
带para的LLM(后面直接在自己的预料上训)【最多】(ps:如果选择这种可以直接跳到下一节高效微调的步骤了) - 加载一个
盲盒零LLM(权重para是随机的,然后用CLM任务去训出para)
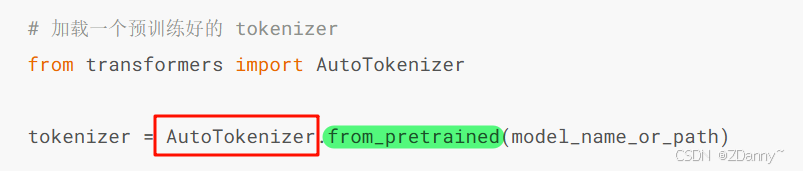
tokenizer也是,一般就加载开源LLM自带的分词器就行
用到的类:AutoTokenizer
2.预训练数据处理
加载完分词器和架构后,自然就是处理下训练数据了。
这里用的是 出门问问序列猴子开源数据集30+GB (os:xdm为伟大的开源事业喝彩!)
【加载(下载解压)-- 分词 – 拼接切分】
① 加载并看看 jsonl数据
用到的库:hf的datasets
用到的类:load_dataset
-
json格式 vs jsonl格式?
- json:整个文件是一个json,用“,”分割每个
- jsonl:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 104
104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









