




第四章 大语言模型
(这是笔者自己的学习记录,仅供参考,愿 LLM 越来越好❤)由于篇幅较长,本篇会先讲如何做LLM的第一个阶段预训练,下一篇会讲后面的两个阶段
初识LLM
LLM = Large Language Model = 大语言模型
就是训练数据T级别、参数百亿10B+都很大,在多卡分布集群训出来的语言模型,也正因此让模型一下子超神了(涌现能力:语言能力一下子远超传统的PLM)
所以回答标题问题,和PLM的区别就是,LLM更大了,训练范式从预训练+微调,LLM的训练见下文
训一个LLM的步骤
主要有3个阶段:
- Pretrain 预训练
- SFT 监督微调
- RLHF 人类反馈强化学习
接下来看下每个阶段的难点
阶段1:Pretrain
ps:这里就是和之前章节介绍过的PLM差不多,都是训练一个模型出来,因为后面还要继续对这个模型进行调整修改,所以这一阶段的模型叫做预训练模型,阶段叫预训练。很直观了。
预训练阶段,采用的架构是类GPT的decoder-only架构,任务是CLM。
一些模型训练参数对比
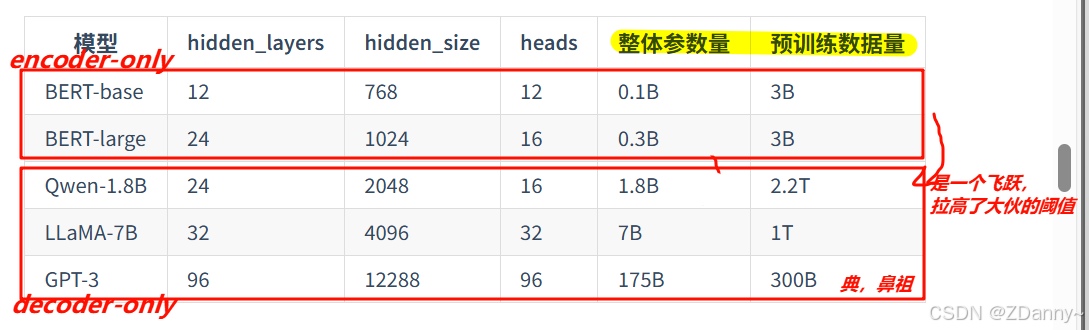
LLM 参数量和训练数据的爱恨情仇
指的是参数量和训练语料量的经验规律
Scaling Law(OpenAI):
C ( 计算量 ) ∼ 6 N ( 参数量 ) D ( t o k e n 数 ) C(计算量) \sim 6N(参数量)D(token数) C(计算量)∼6N(参数量)D(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









