






 本文介绍了一种增强深度网络迁移性的方法,通过最小化训练集上的分类误差和训练集与测试集之间的样本分布差异(MMD最大均值差异),有效避免了fine-tune带来的过拟合,取得了同类任务中最佳效果。
本文介绍了一种增强深度网络迁移性的方法,通过最小化训练集上的分类误差和训练集与测试集之间的样本分布差异(MMD最大均值差异),有效避免了fine-tune带来的过拟合,取得了同类任务中最佳效果。
论文笔记 ——《深度学习神经网络迁移性提升》(《Deep Domain Confusion: Maximizing for Domain Invariance》)
答主因为最近在看迁移学习的论文,时间比较紧张,所以这几篇论文就只抓一下大纲,不考虑具体细节和模拟了,权当是随手笔记了(为了防止BOSS抽查啥也想不起来-> ->),后面有时间会把细节补上的。
关键知识点
- 本文讲了一种新的CNN架构,目的在于找到自适应层尺寸和位置使距离最小,混淆最大(如图)
- MMD是用来刻画source domain和target domain差异的
- 迁移性可通过添加一个自适应层得到提升
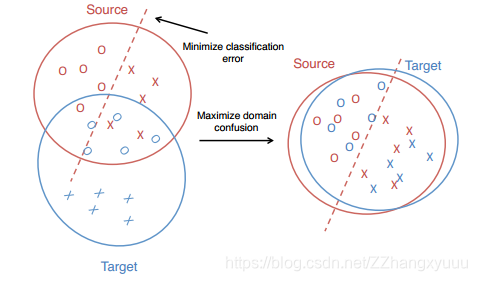
贡献
- 作者提出了一种增强深度网络迁移性的方法,该方法通过在训练模型时,不仅最小化训练集上的分类误差,并且最小化训练集和测试集之间的样本分布差异(通过MMD最大均值差异)。
- 该工作属于一种领域自适应(domain adaptation) 的方法,它能有效地抵御fine-tune所带来了过拟合,它当时在同类任务中取得了最好的效果。
算法
同时减小分类损失和训练集与测试集的分布差异,这可以转化为一个优化损失函数的问题。
损失函数如下:
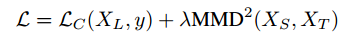
模拟
作者利用MMD方法对自适应层的位置和尺寸进行了选择(但并没有精确给出原因)。

















 502
502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









