






解析: 输入输出格式化的类
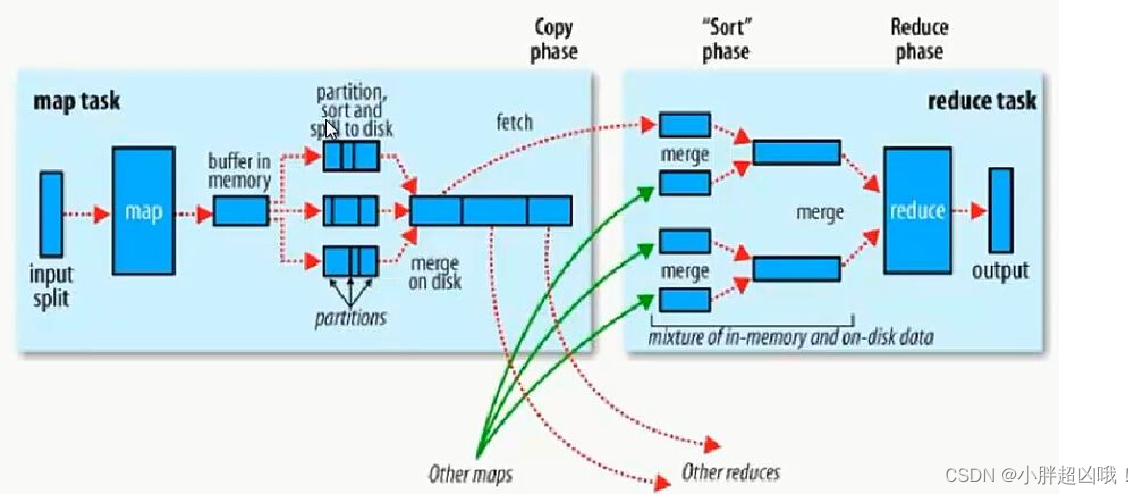
map端处理完会先写到环形缓冲区,100M,80%
溢写磁盘时会分区(哈希分区),排序(快速排序)
合并(归并排序)
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by FernFlower decompiler)
//
package org.apache.hadoop.mapred.lib;
import org.apache.hadoop.classification.InterfaceAudience.Public;
import org.apache.hadoop.classification.InterfaceStability.Stable;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.Partitioner;
@Public
@Stable
public class HashPartitioner<K2, V2> implements Partitioner<K2, V2> {
public HashPartitioner() {
}
public void configure(JobConf job) {
}
public int getPartition(K2 key, V2 value, int numReduceTasks) {
return (key.hashCode() & 2147483647) % numReduceTasks;
}
}
[root@master ~]# rz -E
rz waiting to receive.
[root@master ~]# ls
ac.sh students.txt 文档
anaconda-ks.cfg 公共 下载
dump.rdb 模板 音乐
initial-setup-ks.cfg 视频 桌面
mysql57-community-release-el7-10.noarch.rpm 图片
[root@master ~]# mv students.txt /usr/local/soft/data/
[root@master ~]# cd /usr/local/soft/data/
[root@master data]# ls
new_db.sql student.sql theZenOfPython.txt wordcount
score.sql students.txt theZen.txt words.txt
[root@master data]# hdfs dfs -mkdir -p /data/stu/input
[root@master data]# hdfs dfs -put students.txt /data/stu/input
[root@master data]# cd ..
[root@master soft]# cd jars/
[root@master jars]# ls
hadoop-1.0-SNAPSHOT.jar
[root@master jars]# rm hadoop-1.0-SNAPSHOT.jar
rm:是否删除普通文件 "hadoop-1.0-SNAPSHOT.jar"?y
[root@master jars]# rz -E
rz waiting to receive.
[root@master jars]# ls
hadoop-1.0-SNAPSHOT.jar
[root@master jars]# hadoop jar hadoop-1.0-SNAPSHOT.jar com.shujia.MapReduce.Demo02ClazzCnt
package com.shujia.MapReduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class Demo02ClazzCnt {
//map端
public static class MyMapper extends Mapper<LongWritable,Text, Text,IntWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
//提取数据
// 1500100007,尚孤风,23,女,文科六班
String clazz = value.toString().split(",")[4];
context.write(new Text(clazz),new IntWritable(1));
}
}
//Reduce端
public static class MyReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int cnt = 0;
for (IntWritable value : values) {
cnt+=value.get();
}
context.write(key,new IntWritable(cnt));
}
}
//Driver端
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://master:9000");
//创建一个MapReduce的job
Job job = Job.getInstance(conf);
//配置任务
job.setJobName("Demo02ClazzCnt");
//设置任务运行哪个类
job.setJarByClass(Demo02ClazzCnt.class);
//设置Reduce的数量,默认是1,最终生成文件的数量同Reduce的数量一致
job.setNumReduceTasks(12);
//使用自定义的分区类
job.setPartitionerClass(ClassPartitioner.class);
//配置map端
//指定map运行时哪一个类
job.setMapperClass(MyMapper.class);
//配置Map端输出的key类型
job.setMapOutputKeyClass(Text.class);
//配置Map端输出的value类型
job.setMapOutputValueClass(IntWritable.class);
//配置Reduce端
//指定Reduce运行时哪一个类
job.setReducerClass(MyReducer.class);
//配置Reduce端输出的key类型
job.setOutputKeyClass(Text.class);
//配置Reduce端输出的value类型
job.setOutputValueClass(IntWritable.class);
//配置输入输出路径
/**
* hdfs dfs -mkdir /data/wc/input
* hdfs dfs -put students.txt /data/wc/input
*/
FileInputFormat.addInputPath(job,new Path("/data/stu/input"));
Path path = new Path("/data/stu/output");
FileSystem fs = FileSystem.get(conf);
//判断输出路径是否存在,存在则删除
if (fs.exists(path)){
fs.delete(path,true);
}
//输出路径已存在,会报错
FileOutputFormat.setOutputPath(job,path);
//等待任务完成
job.waitForCompletion(true);
}
/**
* 1.将students.txt上传至虚拟机并使用HDFS命令上传至HDFS
* hdfs dfs -mkdir /data/stu/input
* hdfs dfs -put students.txt /data/stu/input
* 2.将代码通过maven的package打包成jar包,并上传至虚拟机
* 3.使用命令提交任务
* hadoop jar hadoop-1.0-SNAPSHOT.jar com.shujia.MapReduce.Demo02ClazzCnt
* 查看日志:在任务运行时会自动生成一个applicationId
* yarn logs -applicationId application_1647858149677_0004
* 也可以通过historyserver去查看,因为任务真正运行在NodeManager中,日志可能会分散
* historyserver可以负责从Nodemanager中收集日志到Master中方便查看日志
* 启动historyserver:在Master上启动即可
* mr-jobhistory-daemon.sh start historyserver
* http://master:19888
*/
}
class ClassPartitioner extends Partitioner<Text,IntWritable>{
@Override
public int getPartition(Text key, IntWritable value, int numReduces) {
String clazz = key.toString();
switch (clazz) {
case "文科一班":
return 0;
case "文科二班":
return 1;
case "文科三班":
return 2;
case "文科四班":
return 3;
case "文科五班":
return 4;
case "文科六班":
return 5;
case "理科一班":
return 6;
case "理科二班":
return 7;
case "理科三班":
return 8;
case "理科四班":
return 9;
case "理科五班":
return 10;
case "理科六班":
return 11;
}
return 0;
}
}
[root@master jars]# ls
hadoop-1.0-SNAPSHOT.jar
[root@master jars]# rm hadoop-1.0-SNAPSHOT.jar
rm:是否删除普通文件 "hadoop-1.0-SNAPSHOT.jar"?y
[root@master jars]# ls
[root@master jars]# rz -E
rz waiting to receive.
[root@master jars]# hadoop jar hadoop-1.0-SNAPSHOT.jar com.shujia.MapReduce.Demo02ClazzCnt
22/03/25 21:21:05 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.49.110:8032
22/03/25 21:21:05 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
22/03/25 21:21:06 INFO input.FileInputFormat: Total input paths to process : 1
22/03/25 21:21:06 INFO mapreduce.JobSubmitter: number of splits:1
22/03/25 21:21:07 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1647858149677_0007
22/03/25 21:21:07 INFO impl.YarnClientImpl: Submitted application application_1647858149677_0007
22/03/25 21:21:07 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1647858149677_0007/
22/03/25 21:21:07 INFO mapreduce.Job: Running job: job_1647858149677_0007
22/03/25 21:21:14 INFO mapreduce.Job: Job job_1647858149677_0007 running in uber mode : false
22/03/25 21:21:14 INFO mapreduce.Job: map 0% reduce 0%
22/03/25 21:21:19 INFO mapreduce.Job: map 100% reduce 0%
22/03/25 21:21:29 INFO mapreduce.Job: map 100% reduce 8%
22/03/25 21:21:31 INFO mapreduce.Job: map 100% reduce 17%
22/03/25 21:21:36 INFO mapreduce.Job: map 100% reduce 25%
22/03/25 21:21:39 INFO mapreduce.Job: map 100% reduce 33%
22/03/25 21:21:40 INFO mapreduce.Job: map 100% reduce 42%
22/03/25 21:21:41 INFO mapreduce.Job: map 100% reduce 67%
22/03/25 21:21:44 INFO mapreduce.Job: map 100% reduce 92%
22/03/25 21:21:45 INFO mapreduce.Job: map 100% reduce 100%
22/03/25 21:21:45 INFO mapreduce.Job: Job job_1647858149677_0007 completed successfully
22/03/25 21:21:46 INFO mapreduce.Job: Counters: 50
File System Counters
FILE: Number of bytes read=19072
FILE: Number of bytes written=1635424
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=42109
HDFS: Number of bytes written=193
HDFS: Number of read operations=39
HDFS: Number of large read operations=0
HDFS: Number of write operations=24
Job Counters
Killed reduce tasks=1
Launched map tasks=1
Launched reduce tasks=12
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=3009
Total time spent by all reduces in occupied slots (ms)=183989
Total time spent by all map tasks (ms)=3009
Total time spent by all reduce tasks (ms)=183989
Total vcore-milliseconds taken by all map tasks=3009
Total vcore-milliseconds taken by all reduce tasks=183989
Total megabyte-milliseconds taken by all map tasks=3081216
Total megabyte-milliseconds taken by all reduce tasks=188404736
Map-Reduce Framework
Map input records=1000
Map output records=1000
Map output bytes=17000
Map output materialized bytes=19072
Input split bytes=111
Combine input records=0
Combine output records=0
Reduce input groups=12
Reduce shuffle bytes=19072
Reduce input records=1000
Reduce output records=12
Spilled Records=2000
Shuffled Maps =12
Failed Shuffles=0
Merged Map outputs=12
GC time elapsed (ms)=1383
CPU time spent (ms)=8230
Physical memory (bytes) snapshot=1330892800
Virtual memory (bytes) snapshot=27107094528
Total committed heap usage (bytes)=324173824
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=41998
File Output Format Counters
Bytes Written=193
[root@master jars]# hdfs dfs -cat /data/stu/output/part-r-00000
文科一班 72
[root@master jars]# hdfs dfs -cat /data/stu/output/part-r-00001
文科二班 87

















 569
569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









