



一、抛出问题
- 环境:
aws EMR s3
hudi-0.10.1
spark-3.1.2
hive-3.1.2
hadoop-3.2.1
- 错误日志
Caused by: org.apache.hudi.exception.HoodieUpsertException: Failed to merge old record into new file for key cat_id:201225781 from old file s3://...parquet to new file s3://...parquet with writerSchema {
"type" : "record",
"name" : "dim_catpath_hudi_test_ex_record",
"namespace" : "hoodie.dim_catpath_hudi_test_ex",
"fields" : [ {
"name" : "_hoodie_commit_time",
"type" : [ "null", "string" ],
"doc" : "",
"default" : null
}, {
"name" : "_hoodie_commit_seqno",
"type" : [ "null", "string" ],
"doc" : "",
"default" : null
}, {
"name" : "_hoodie_record_key",
"type" : [ "null", "string" ],
"doc" : "",
"default" : null
}, {
"name" : "_hoodie_partition_path",
"type" : [ "null", "string" ],
"doc" : "",
"default" : null
}, {
"name" : "_hoodie_file_name",
"type" : [ "null", "string" ],
"doc" : "",
"default" : null
}, {
"name" : "platform",
"type" : [ "null", "string" ],
"default" : null
}, {
"name" : "cat_id",
"type" : [ "null", "int" ],
"default" : null
}, {
"name" : "len",
"type" : "int"
}, {
"name" : "map_to",
"type" : "int"
}, {
"name" : "name_path",
"type" : {
"type" : "array",
"items" : [ "string", "null" ]
}
}, {
"name" : "id_path",
"type" : {
"type" : "array",
"items" : [ "string", "null" ]
}
}, {
"name" : "ts",
"type" : [ "null", "long" ],
"default" : null
} ]
}
at org.apache.hudi.io.HoodieMergeHandle.write(HoodieMergeHandle.java:356)
at org.apache.hudi.table.action.commit.AbstractMergeHelper$UpdateHandler.consumeOneRecord(AbstractMergeHelper.java:122)
at org.apache.hudi.table.action.commit.AbstractMergeHelper$UpdateHandler.consumeOneRecord(AbstractMergeHelper.java:112)
at org.apache.hudi.common.util.queue.BoundedInMemoryQueueConsumer.consume(BoundedInMemoryQueueConsumer.java:37)
at org.apache.hudi.common.util.queue.BoundedInMemoryExecutor.lambda$null$2(BoundedInMemoryExecutor.java:121)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
... 3 more
Caused by: java.lang.RuntimeException: Null-value for required field: map_to
at org.apache.parquet.avro.AvroWriteSupport.writeRecordFields(AvroWriteSupport.java:194)
at org.apache.parquet.avro.AvroWriteSupport.write(AvroWriteSupport.java:165)
at org.apache.parquet.hadoop.InternalParquetRecordWriter.write(InternalParquetRecordWriter.java:128)
at org.apache.parquet.hadoop.ParquetWriter.write(ParquetWriter.java:299)
at org.apache.hudi.io.storage.HoodieParquetWriter.writeAvro(HoodieParquetWriter.java:95)
at org.apache.hudi.io.HoodieMergeHandle.write(HoodieMergeHandle.java:351)
... 8 more
分析问题
- HUDI表的创建方式是使用python/scala的"write...save(...)"的方式处理的
- sql端的table是在spark-sql环境执行的"create table ... using hudi partitioned by (" +partitions +") options ( primaryKey = '"+ pk +"', type = 'cow', preCombineField = 'ts' ) location '...'"
- 对于options的方面,我们尝试并组合过N种方案,无果。
- 对于表类型方面,我们尝试了external表和managed表加载元数据,亦会有相同问题
- 最后繁琐的问题排查过程就不一一赘述了,直接上目前的结论和解决方案
结论&对策
- 结论
在更新处理的时候,我们一贯使用update table set col = ? where 的方法。
此时在where条件以外的数据,col若存在null就会报出以上的错误,除非我将所有为null的行都涵盖在更新范围内也就是where条件内。
- 来个图说明一下上述结论
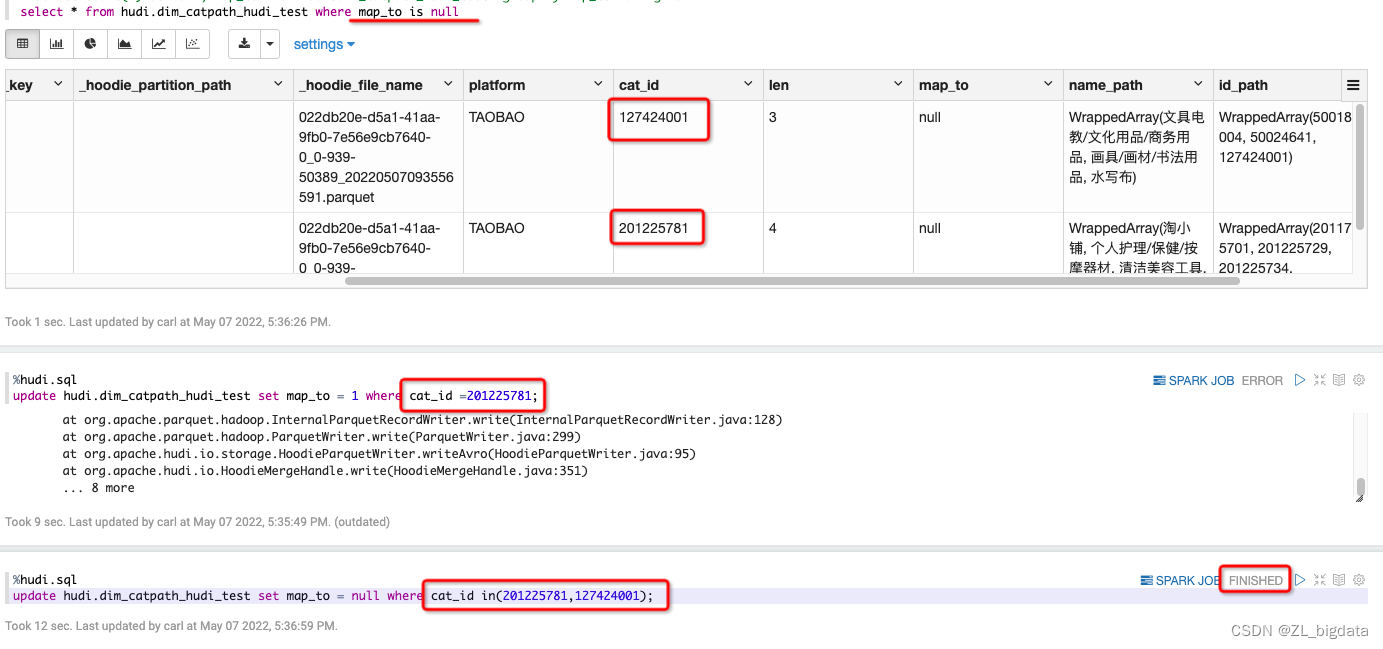
表中有且仅有两条map_to is null的数据,主键分别为127***,201***
若仅对一条进行更新,则会报错(第一次upd),若将所有的一起更新则可以正常执行(第二次upd),正常者即为将所有null的行都涵盖在where条件内的更新
- 临时对策
直接对该列所有为null的值进行更新,更新后则不会存在null的值、亦不会报Null-value异常
update hudi.table_name set col = '' where col is null;
结尾语
该场景并不普遍存在,只在某特定环境下(引发问题的具体环境因素及原因还未找到,所以此问题并未根治,此处仅为临时解决方案,望抛砖引玉,有大神前来指点),比如我的大环境就是aws-EMR-s3。hudi包是我所在团队的优秀同事协力,基于aws环境进行调整后完成编译的hudi-0.10.1。


















 3084
3084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









