- 博客(17)
- 资源 (2)
- 收藏
- 关注
 RSS订阅
RSS订阅转载 spark 的内存管理机制
1. 堆内和堆外内存规划作为一个 JVM 进程,Executor 的内存管理建立在 JVM 的内存管理之上,Spark 对 JVM 的堆内(On-heap)空间进行了更为详细的分配,以充分利用内存。同时,Spark 引入了堆外(Off-heap)内存,使之可以直接在工作节点...
2019-04-29 14:34:26
 923
923
 1
1
转载 Linux下查看CPU型号,内存大小,硬盘空间的命令(详解)
感谢有奉献精神的人转自:http://www.jb51.net/article/97157.htm1 查看CPU1.1 查看CPU个数cat /proc/cpuinfo | grep “physical id” | uniq | wc -l2 uniq命令:删除重复行;wc –l命令:统计行数1.2 查看CPU核数cat /proc/cpuinfo | grep “cpu cores...
2019-04-19 16:54:37
570
原创 记一次Flink1.8.0编译过程
环境Window10,内存:8G,处理器:i5-8500,64位Maven配置Maven版本:3.3.9Settings.xml文件配置如下,因为有些包阿里云没有,故增加一个http://uk.maven.org/maven2地址的镜像。<mirrors> <mirror> <id>UK</id> <mirrorOf&...
2019-04-13 10:21:20
2906
2
转载 JVM内存结构--新生代及新生代里的两个Survivor区(下一轮S0与S1交换角色,如此循环往复)、常见调优参数
转自http://www.cnblogs.com/duanxz/p/6076662.html一、为什么会有年轻代 我们先来屡屡,为什么需要把堆分代?不分代不能完成他所做的事情么?其实不分代完全可以,分代的唯一理由就是优化GC性能。你先想想,如果没有分代,那我们所有的对象都在一块,GC的时候我们要找到哪些对象没用,这样就会对堆的...
2019-02-18 09:54:40
1101
转载 Flink 原理与实现:Aysnc I/O
背景 Async I/O 是阿里巴巴贡献给社区的一个呼声非常高的特性,于1.2版本引入。主要目的是为了解决与外部系统交互时网络延迟成为了系统瓶颈的问题。 流计算系统中经常需要与外部系统进行交互,比如需要查询外部数据库以关联上用户的额外信息。通常,我们的实现方式是向数据库发送用户a的查询请求,然后等待结果返回,在这之前,我们无法发送用户b的查询请求。这是一种同步访问的模式,如下图左边所示。...
2019-01-14 11:26:23
506
原创 Flink流广播实例分析
前言 继上一篇,我们介绍了广播变量后,本篇将以某报警规则为例进一步说明广播变量的使用。 具体场景如下: 1、数据源有两种消息:Route Msg和Alarm Msg 2、 Route Msg中有两个关键字段:resultType和resultMark,其中resultType需要和每条报警规则对应,resultMark标志该条消息是有效或者无效。 3、 Alarm Msg根据报...
2019-01-13 23:54:06
2065
原创 Flink的流广播(Broadcast State)
上一篇Flink的状态管理中,我们提到了Operator state,本文介绍的广播状态(Broadcast State)是 Apache Flink 中支持的第三种类型的operator state。Broadcast State使得 Flink 用户能够以容错、一致、可扩缩容地将来自广播的低吞吐的事件流数据存储下来,被广播到某个 operator 的所有并发实例中,然后与另一条流数据连接进...
2019-01-13 11:30:04
5537
原创 MySql索引笔记
这篇文档仅仅只是对mySql中索引作日常笔记,不讨论索引的分类/概念等。这篇文档将讨论聚集索引和非聚集索引,聚集索引和非聚集索引不是索引类型,而是针对数据存储引擎而言的,介绍完聚集索引和非聚集索引后,将对索引使用进行总结。聚簇索引和非聚簇索引的区别是: 聚簇索引(innobe)的叶子节点就是数据节点 非聚簇索引(myisam)的叶子节点仍是索引文件,只是该索引文件中包含指向对应数据块...
2019-01-10 15:50:59
257
原创 Flink 状态管理
什么是状态(State) 有些任务的结果不仅仅依赖于当前的输入,也依赖于之前的输入结果信息,因此对中间结果状态等的保存就很有必要。 在Flink中,我们可以这样理解State:某task/operator在某时刻的一个中间结果。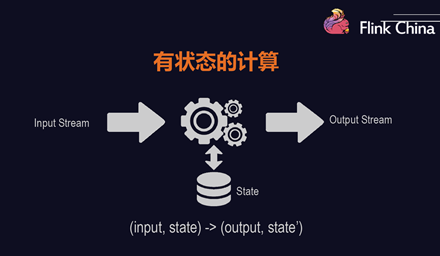的孩子(Child)之间互称为兄弟(Sibling)。祖先:结点的祖先(Ancestor)是从根(Root)到该结点所经分支(Branch)上的所有结点。叶子(终端结点):没有孩子的结点(也就是度为0的结点)称为叶子(Leaf)或终端结点。度:结点所拥有的子树个数称为结点的度(Degree)。边:一个结点和另一个结点之间的...
2019-01-07 17:59:24
1341
转载 追源索骥:透过源码看懂Flink核心框架的执行流程
https://www.cnblogs.com/bethunebtj/p/9168274.html写在最前:因为这篇博客太长,所以我把它转成了带书签的pdf格式,看起来更方便一点。想要的童鞋可以到我的公众号“老白讲互联网”后台留言flink即可获取。追源索骥:透过源码看懂Flink核心框架的执行流程flink...
2018-12-22 19:32:45
866
原创 做EDA分析——python3 使用cx_Oracle运到的坑
继上一篇写了EDA简单分析报告,想想了还是把环境安装写一下,也为后续自己有个记录。先说一下我运到的坑:工作环境win64,数据存在Oracle数据库中,并不清楚instantclient是多少位。想当然的下载了Anaconda win64位,cx_Oracle 64,导致数据库连接不上报错,需要重新下载/安装等。下面简单总结一下我的环境部署。1. 准备安装配置时,必须把握一个点,就是版本一...
2018-12-20 23:28:29
739
原创 EDA简单分析报告
1 概览 1.1 EDA定义 探索性数据分析(Exploratory Data Analysis,简称EDA),是指对已有的数据(特别是调查或观察得来的原始数据)在尽量少的先验假定下进行探索,通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律的一种数据分析方法。特别是当我们面对大数据时代到来的时候,各种杂乱的“脏数据”,往往不知所措,不知道从哪里开始了解目前拿到手上的数...
2018-12-20 23:01:16
4417
原创 浅谈WaterMark
一直在找理由,没有时间空下来总结一下flink相关的知识点,终于下了决心:后续专注了flink的专题总结。想了想还是以watermark开始,本文只是谈谈个人对待watermark的理解,如有哪里说得不恰当,欢迎讨论。起初对Flink的watermark感动一点困惑,经过时间的沉淀,源码断断续续的阅读,稍微清楚一点,下面我将从一些概念说起。1、时间属性Flink官方中有三种时间类型,Eve...
2018-12-10 23:15:26
16005
1
原创 从String,StringBuilder和StringBuffer的使用谈起JVM的内存区域与内存分配(二)
1、概要 上一节中谈了String,StringBuilder和StringBuffer的区别和使用,并简单说明了各变量的内存分配等。做过C++编程的同学总是自己管理内存,一不留神就会造成野指针或者内存泄漏。Java的自动内存管理机制,“不需要”自己管理内存,统一由JVM管理。这一节将简要介绍java的内存区域和内存分配(本篇为了准确,以《java虚拟机》简要总结)。2、运...
2018-12-09 23:01:30
1123
原创 从String,StringBuilder和StringBuffer的使用谈起JVM的内存区域与内存分配(一)
好记性不如烂笔头,抽出闲暇时间总结一下JVM的内存区域,这里我从字符串的StringBuilder的和StringBuffer的的的区别和使用谈起。首先我们先了解一下String's ==和equals的区别:这里先直接给出结论: String定义的对象是引用类型的变量,该变量存储的并不是“值”本身,而是其关联的对象在内存中的地址。==比较的是两个变量是否指向同一个地址.e...
2018-12-02 20:53:19
1301
原创 org.apache.hadoop.ipc.RemoteException(java.io.IOException)异常
最近在调试flink程序时,发现程序起不来,查看错误日志和hadoop相关,我的程序与hadoop相关的只有设置了checkpoint的路径是hdfs的一个目录路径。错误日志最后的错误大致是:org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /后查看机器进程情况发现:集群中datanode没有...
2018-11-20 20:10:59
15449
DB思维导图.pdf
2020-03-09
tidb-ansible.rar
2020-02-12
![]()
空空如也
TA创建的收藏夹 TA关注的收藏夹
TA关注的人