



摘要:
语音合成主要是指根据文本模拟生成自然语音,可以用来替代人类的语音进行交流,在商务服务、助老助残等领域有较好的应用价值。本文简要阐述语音合成技术的基本流派、神经网络合成语音的基本方法、常见开源项目、商业银行应用案例,以及应用过程中的风险挑战。
名词解释:
(1)TTS:Text-to-Speech,运用建模方法将文本智能地转换为自然语音的一类工程技术。
(2)Text Analysis:在语音合成过程中完成文本到语言学特征的转换,通常包括文本预处理(纠错)、文本归一化(语义合并)、语言分词、音素转换、韵律解析等功能。
(3)MFCC: 基于Mel滤波器组提取的特征数据,反应频率方面的特征。
(4)BFCC:基于Bark 滤波器组提取的特征数据,反应频率方面的特征。
(5)GFCC:基于Gammatone滤波器组提取的特征数据,反应频率方面的特征。
(6)MGC:广义梅尔倒谱特征(mel generalized cepstral features),反映音色方面的特征。
(7)Lf0:反映声音音高方面的语音特征数据。
(8)Bap:反映声音音高方面的语音特征数据。
一、语音合成技术
常见的语音合成技术大致可以分为模拟器官合成、共振峰合成、拼接合成、神经网络合成四种。
1、模拟器官合成
通过模拟构造人类的发声器官进行声音合成,包括唇形、舌头、声门和声带动作。这种方式的缺点是发音行为难以建模、模拟数据不好收集,效果也比较差。
2、共振峰合成
共振峰是声腔的共鸣频率,可以作为声道谐振特性的表征。基于一系列模仿元音/响辅音的包络曲线可以进行声音合成,但由于声音的频率规则难以指定,效果存在偏差。
3、拼接合成
根据场景需要,建立音节、字、词、句子的语音片段数据库。使用时,根据文本提取相应的语音片段进行拼接合成。通常存在语音无力度、无情绪和不自然的缺点。
4、神经网络合成
使用神经网络技术进行建模,通过文本分析模块建立语音的持续时间、词性标注、声学模型,然后用声码器完成声音合成。神经网络的语音合成方式在可理解性、自然性方面都具有较高的语音质量。
以上语音合成技术中,模拟器官合成方法的实现难度最大;拼接合成的实现最为容易;共振峰合成技术定制难度大且只有少数专家掌握;神经网络合成需要借助复杂的数学工具和软件处理过程,但是可定制化和实现效果最好,是目前最受欢迎的语音合成技术。
二、神经网络合成
在微软亚洲研究院谭旭等人的著名论文《A Survey on Neural Speech Synthesis》中,总结了使用神经网络技术进行语音合成的5种基本模式,如图1所示。
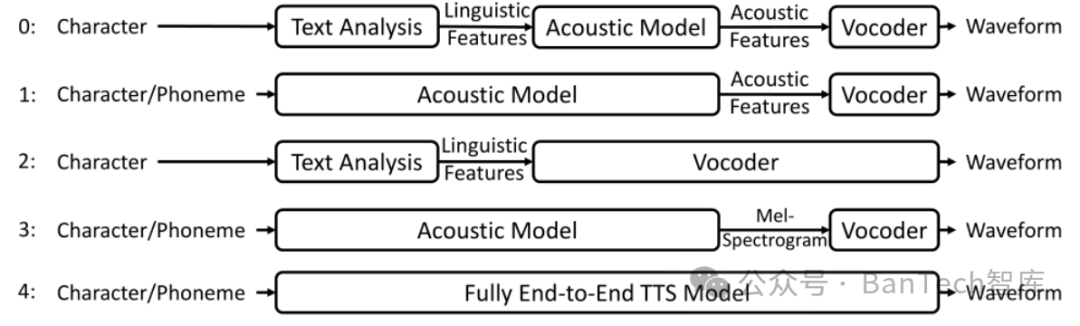
图1 神经网络合成语音的5种基本模式
1、模式一
由文本分析模块、声学处理模块、声码器模块组成。文本分析模块负责将输入的文本转换为语言的基础标记,例如元音、清辅音、浊辅音、音调、音长等。声学处理模块负责将语言基础标记转换为对应的声学特征,如MFCC、BFCC、GFCC、MGC、lf0、bap等。声码器则根据声学特征及时长信息合成对应的语音。
2、模式二
将文本分析模块和声学处理模块合二为一,在单个模型中完成处理。声码器的功能与模式一相同。
3、模式三
文本分析模块与模式一相同。声学处理模块和声码器模块合二为一,在单个模型中完成处理。
4、模式四
与模式二类似,但对接声学处理模块与声码器模块使用的是梅尔倒谱声学特征。
5、模式五
在单一模型中完成语言学分析、声学处理、声码器的功能。
常见的文本分析模块:R2、Sparrowhawk、Festival等。
常见的声学处理模块:HMM-based、DNN-based、LSTM-based、EMPHASIS、ARST、VoiceLoop、Tacotron/Tacotron2、DurIAN、MelNet、VAE-TTS、TalkNet、DeepVoice/DeepVoice2/DeepVoice3、FastSpeech、Flow-TTS、Glow-TTS等。
常见的声码器模块:STRAIGHT、WORLD/WORLD2、Char2Wav、WaveRNN、GAN-based、Flow-based、VAE-based、DDPM等。
三、常见开源语音合成项目
1、eSpeak
eSpeak是共振峰合成方式的开源语音合成系统,利用参数合成方式完成语音生成。其工作原理是将语音合成分为三部分:语言学参数、韵律处理参数、声学处理过程。
语言学参数是能够对输入文本进行规范化、分词、语法分析和语义分析,并在其中加入所需要的发音提示(包括数字、特殊词汇、断句停顿等)的一类语言学信息。
韵律处理参数是能够对输入文本进行音段特征分析的一类语言学信息,包括音高、音长和音强等,其标记系统基于语调、节奏和重音这些韵律特征。
声学处理过程是在语言学参数分析及韵律处理参数分析的基础上,基于统计规则和韵律控制参数,使用语音语料库合成语音。由于eSpeak的基础参数涉及大量参数,一般不适用于需要自定义语音效果的场合。
2、VITS
VITS采用一个并行化的语音合成模型。模型采用基于标准化流模型的变分推理策略和对抗学习策略来提升生成模型的表现力,同时借助随机时长预测模块提升合成语音的韵律多样性,与两阶段模型相比可以生成更加自然的合成语音。
带条件变分自编码器的神经网络语音合成模型如图2所示。
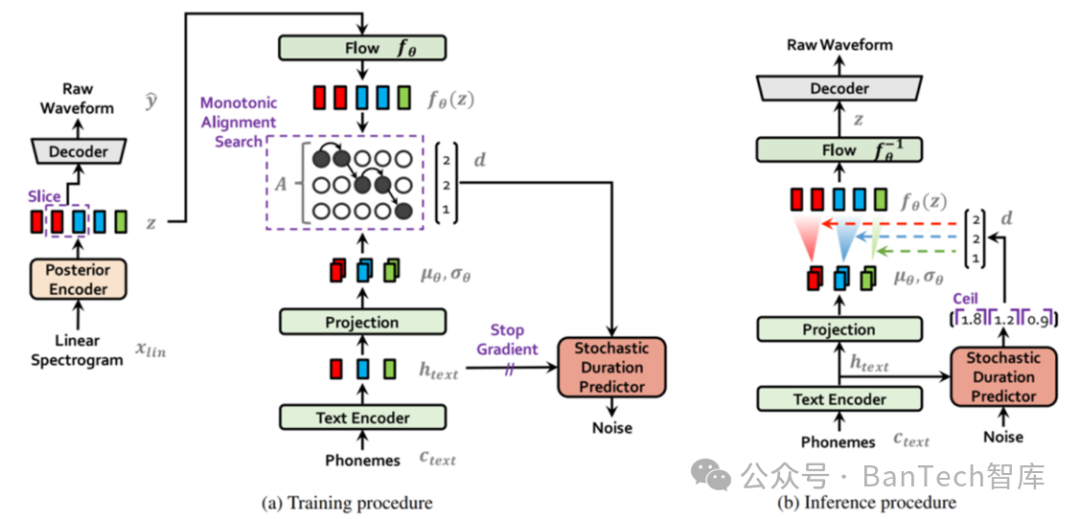
图2 带条件变分自编码器的神经网络语音合成模型
训练阶段,基于由音频数据与打标文本数据组成的训练集进行深度迭代;训练完成后,使用测试集对模型进行评估及调优。评估指标为生成语音的质量、流畅度等。
使用阶段,将待合成的文本输入到模型中,经过编码器生成潜在表示,然后通过解码器将潜在表示转换为语音输出。必要时,可以通过调整模型的参数和超参数,来获得更好的语音合成效果。
VITS的优点是生成的语音质量较高,能够生成流畅的语音。但是,VITS需要大量的训练语料来训练vocoder和语音合成模型,同时需要较复杂的训练流程。
3、Merlin
Merlin是一个采用文本分析模块、声学处理模块、声码器模块的语音合成项目。其中文本分析由Htk、Festvox、Festival构成;声学处理由两个6层的DNN网络构成,一个负责处理语言学特征到声学特征的映射,一个负责语言学特征到语音时长的映射;声码器可以灵活选择Straight、World、Magphase等。Merlin语音合成模型工作原理如图3所示。
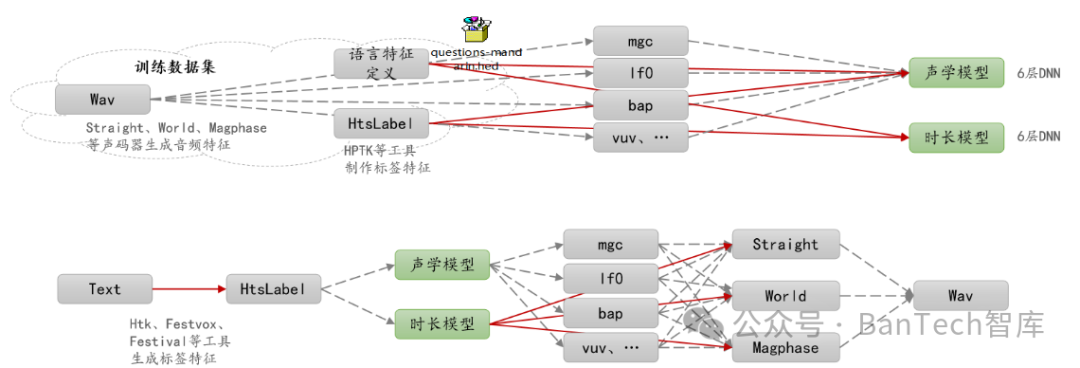
图3 Merlin语音合成模型工作原理
4、ChatWaifu
ChatWaifu是一种一体化的模型。该项目提供了基于特定词库(包含词频和词性)的预训练语音合成模型,可以支持汉语、英语、日语、韩语、以及部分方言。模型整体大小中等,性能优良,适用的应用场合比较多。
5、其他
一些商业机构在自身提供TTS合成技术或服务的同时,也提供了一些开源的TTS模型,例如百度、阿里巴巴、微软、腾讯、谷歌、科大讯飞、商汤科技等。
四、银行业应用案例
1、智能客服
商业银行在电话银行服务中提供了智能的语音导览服务,其中语音播报的技术基础就是语音合成技术。
2、数字员工
近年来,商业银行在数字大堂经理、展会服务、手机银行、VIP客服、业务宣传等领域进行了数字员工的应用尝试,支持语音、文字、手势等多种交互方式。其中语音交互能力需要语音识别和语音合成技术提供支撑。
3、组织文化建设
商业银行在数字党建、线上展馆、业务培训等领域开展了智能化的技术创新,将一些组织文化建设工作从线下搬到线上,语音合成技术在功能导览、内容制作、交流互动等方面提供了必要的支持。
五、机遇与挑战
计算机系统性能的提高以及神经网络语音合成技术的进步,使工程方法合成的机器语音越来越贴近真实的声音。这种情况扩大了语音合成技术的适用范围,同时也对实际应用过程中的业务管理和技术保障工作提出了更加严格的要求。
谷歌、微软、百度等厂商是神经网络底层框架的提供商。在实际业务系统中应用神经网络模型需要考虑到相关厂商的技术实力及服务支撑能力。
神经网络语音合成模型基于特定对象的语音数据进行训练,其合成的最终声音具备特定对象的主要发音特征。这使得个人语音数据更容易成为不法分子窃取和滥用的目标。因此,在使用到用户语音信息的场合,需要明确告知用户具体的使用目的和范围,并取得用户同意;必须通过加密、签名、认证等方式加强用户语音信息的安全保护;业务系统实施过程中严格限制用户语音信息的使用场合,落实用户数据的安全保护措施,确保用户信息使用依法合规。
语音合成技术的进步降低了仿冒用户身份进行对话的技术成本,一定程度上增加了使用语音信息进行用户鉴权的业务安全风险。因此,银行及其他商务服务机构在基本业务上是否采用语音播报或语音录入将不只是单纯的技术问题或客户体验问题,也是重要的安全决策;需要在系统技术架构、业务管控措施方面同时考虑,不断完善技术安全策略和防护措施。
参考资料:
【1】《A Survey on Neural Speech Synthesis》,微软亚洲研究院。
【2】《Neural HMMs are all you need(for high-quality attention-free TTS)》,瑞典皇家理工学院。
【3】《Tacotron: Towards end-to-end Speech Synthesis》,谷歌公司。
【4】《Natural TTS Synthesis by conditioning wavenet on mel spectrogram》,谷歌公司/加利福尼亚大学伯克利分校。
【5】《FastSpeech: Fast, Robust and Controllable Text to Speech》,浙江大学/微软研究院/微软亚洲搜索技术中心。
【6】《FastSpeech2: Fast and High-Quality end-to-end text to speech》,浙江大学/微软研究院/微软云计算公司。
【7】《Glow-TTS: A Generative Flow for Text-to-Speech via Monotonic Alignment Search》,韩国Kakao公司/韩国首尔大学。
【8】《MelGan: Generative Adversarial Networks for Conditional Waveform Synthesis》,加拿大Lyrebird公司。
【9】《Multi-band Melgan: Faster waveform generation for high-quality text-to-speech》,西北工业大学/搜狗公司。
【10】《Deep Voice: Real-time Neural Text-to-Speech》,百度公司。
【11】《WaveNet: A Generative Model for Raw Audio》,谷歌公司。
【12】开源语音合成项目eSpeak-ng,https://github.com/espeak-ng/espeak-ng
【13】开源语音合成项目Merlin,https://github.com/CSTR-Edinburgh/merlin
【14】开源语音合成项目ChatWaifu,https://github.com/cjyaddone/ChatWaifu
【15】开源文本分析模块RE2,https://github.com/google/re2
【16】开源文本分析模块Sparrowhawk,https://github.com/google/sparrowhawk
【17】开源文本分析模块Festival,https://www.cstr.ed.ac.uk/projects/festival
【18】开源文本分析模块MTTS,https://github.com/jqying/MTTS
【19】开源声学处理模块HMM-Base,https://github.com/shivammehta25/Neural-HMM
【20】开源声学处理模块Tacotron,https://github.com/Kyubyong/tacotron
【21】开源声学处理模块FastSpeech,https://github.com/xcmyz/FastSpeech
【22】开源声学处理模块MelGan,https://github.com/seungwonpark/melgan
【23】开源声学处理模块DeepVoice,https://github.com/israelg99/deepvoice
【24】开源声学处理模块Wavenet,https://gitee.com/Q-crisp/wavenet_vocoder
【25】开源声码器STRAIGHT,https://github.com/shuaijiang/STRAIGHT
【26】开源声码器WORLD,https://github.com/mmorise/World
【27】开源声码器PARALLEL WAVEGAN,https://github.com/kan-bayashi/ParallelWaveGAN
【28】开源声码器VITS,https://github.com/jaywalnut310/vits
转载:语音合成模型介绍


















 5934
5934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









