




 这篇博客介绍了链表的三种常见操作:如何在链表尾部添加元素(两种方法)、链表传值的影响以及链表中间节点的修改。对于链表传值问题,解释了由于传参是地址,所以会影响实际链表。最后讨论了单向链表和双向链表的中间节点修改,并强调了修改时需注意保持前后关系的正确性。
这篇博客介绍了链表的三种常见操作:如何在链表尾部添加元素(两种方法)、链表传值的影响以及链表中间节点的修改。对于链表传值问题,解释了由于传参是地址,所以会影响实际链表。最后讨论了单向链表和双向链表的中间节点修改,并强调了修改时需注意保持前后关系的正确性。
链表的基本已经在上一篇博文中记录了链表的开辟空间,链表的基本遍历。
链表的尾部添加问题:
第一个:使用函数添加元素节点。
struct node
{
int data;
struct node *next;
}*head;
void add(node *head)
{
for(int i=1;i<=10;i++){
node *code = (struct node *)malloc(sizeof(struct node));
code->data = i;
head->next = code;
head = code;
head->next = NULL;
}
}
第二个:不使用函数尾部添加元素节点。(注意标记起始位置)
head =(struct node *)malloc(sizeof(struct node));
struct node *sign = head;
printf("添加元素,1~10\n");
for(int i=1;i<=10;i++){
node *code = (struct node *)malloc(sizeof(struct node));
code->data = i;
head->next = code;
head = code;
head->next = NULL;
}
printf("添加完成,打印观看实际结果\n");
head = sign->next;
while(head){
printf("%d ",head->data);
head = head->next;
}
printf("\n");
链表的传值问题:
struct node
{
int data;
struct node *next;
};
void add(node *head)
{
head->data = 2;
}
int main()
{
struct node *head = (struct node *)malloc(sizeof(struct node));
head->data = 1;
printf("%d\n",head->data);
add(head);
printf("%d\n",head->data);
return 0;
}
结果查看:
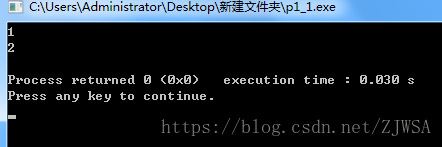
解释:
起始我们指针指向的位置是内存中实际的单元,如果作为传参的话,传的是内存的地址,那么也就实参。在观看一则代码,就明了。
代码二:
struct node
{
int data;
struct node *next;
};
void add(node *head)
{
for(int i=1;i<=10;i++){
node *code = (struct node *)malloc(sizeof(struct node));
code->data = i;
head->next = code;
head = code;
head->next = NULL;
}
}
int main()
{
struct node *head =(struct node *)malloc(sizeof(struct node));
printf("添加元素,1~10\n");
add(head);
printf("添加完成,打印观看实际结果\n");
head = head->next;
while(head){
printf("%d ",head->data);
head = head->next;
}
printf("\n");
return 0;
}
运行结果如下:
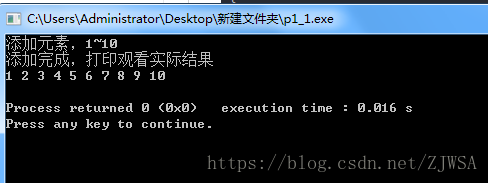
分析:
这则代码是尾部添加的代码,传的也是链表参数,但是结果确实影响了。
结论:
链表的参数会影响到实际的链表,理由同上(传的是地址),但是他传的参数相当于给予了另一个链表指针指向相同的位置,改变的结果他可以遍历,但是他的位置不受传参影响。
链表的中间修改问题:
常用的链表有双向链表,单向链表。
举一个例子:单向节点的中间删除
struct node
{
int data;
struct node *next;
};
void add(node *head)
{
for(int i=1;i<=10;i++){
node *code = (struct node *)malloc(sizeof(struct node));
code->data = i;
head->next = code;
head = code;
head->next = NULL;
}
}
void del(node *head,int data)
{
///记录前面的一个节点
struct node *per = head;
///带头节点,实际值在后面一个
head = head->next;
while(head){
///当前节点就是要删除的节点
if(head->data == data)
{
per->next = head->next;
break;
}
per = head;
head = head->next;
}
}
void print(node *head)
{
head = head->next;
while(head){
printf("%d ",head->data);
head = head->next;
}
printf("\n");
}
int main()
{
struct node *head =(struct node *)malloc(sizeof(struct node));
printf("添加元素,1~10\n");
add(head);
printf("添加完成,打印观看实际结果\n");
print(head);
printf("删除元素:3\n");
del(head,3);
printf("删除完成,打印观看实际结果\n");
print(head);
return 0;
}
运行结果如下:
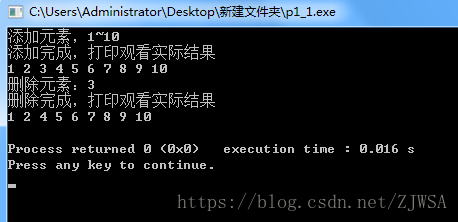
例二:双向链表的中间修改节点值。
void del(node *head,int data)
{
///带头节点,实际值在后面一个
head = head->post;
while(head){
///当前节点就是要删除的节点
if(head->data == data)
{
head->post->per = head->per;
head->per->post = head->post;
break;
}
head = head->post;
}
}
注:关系要从后面开始修改,不能从前面开始修改,那样后面就找不到原来的前面的关系了,找到的是修改后的前面的关系。
运行结果如下:
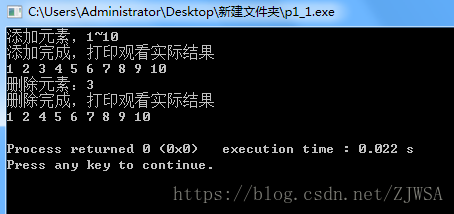
链表的基础操作基本上就是这些了,如果想要知道其他的链表的操作的话,可以评论我会在第一时间更新链表基本操作博文!

















 3213
3213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









