






目录
1.乒乓操作的原理
乒乓操作常用于数据流的控制,它的特点如下:
- 实现数据的无缝缓冲和处理;
- 节省缓冲区空间;
- 在中间引入预处理模块时,实现低速预处理模块处理高速数据流。
乒乓操作的原理,如下图所示,现有两个数据缓冲模块,分别标号为1和2。那么乒乓操作就是在数据流输入模块1时,读取2中的数据到输出数据单元;数据流输入模块2时,读取1中的数据到输出数据单元。最后送到处理模块中处理。
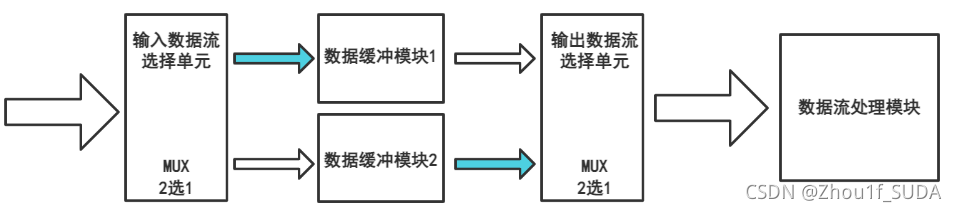
这样的结构就可以实现数据的无缝缓冲和处理,可以想象,数据流是间隔不断地、无缝地进行输出的。
此外,这样的结构也可以在某种程度上节省缓冲区的空间。这个例子我也是从其他博主的文章中学来的,在时分复用中,假设1帧是由15个时隙组成,设每个时隙的时间是10ms。我们如果要实现对这一帧延迟一个时隙时间,一种方法是把这一帧都缓存下来进行延时,而乒乓操作的方法就只需要两个1个时隙大小的缓冲区,因为这样写入每一个时间片数据的时候需要10ms,在读出时就相当于延迟了一个时隙的时间。
对于乒乓操作的第3个特点,我们需要在中间引入低速预处理模块,如下图所示。
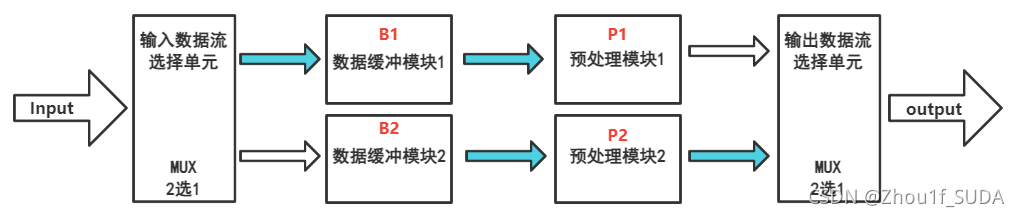
假设输入数据流的速率为 100Mbps,而一个数据预处理模块P1、P2运算速度只有50Mbps,如果不采用乒乓操作结构,很明显数据预处理模块是处理不了数据端口A的数据流的。
当采用上图的乒乓操作方式之后。假设两个数据缓冲模块的内存大小都是1Mb,故每段乒乓缓冲周期为10ms。但是此时留给每个数据预处理模块的运算时间不再是10ms,而是20ms了,20ms内数据预处理模块是可以处理掉1Mb数据的。为什么留给数据预处理模块的时间有20ms呢?这20ms等于往自己写入数据的10ms加上往另外一个缓冲模块写入数据的10ms。因为这20ms内数据预处理模块都可以从自己本级的缓冲模块读取数据做运算。
这就做到了采用低速的数据预处理模块处理高速的数据流。上图是2级乒乓操作结构(因为数据流速率是预处理模块速率的2倍),如果数据流速率是预处理模块速率的n倍,就可以采用n级乒乓操作结构。这也是面积换速度的方法。
0.5s后,B1存入50Mbit,同时P1处理了25Mbit。
1s后,P1处理完了,并开始输出50Mbit。B2存入50Mbit,同时P2处理了25Mbit。
1.5s后,P1的50Mbit输出完了,此时B1又存入50Mbit,同时P1处理了25Mbit。P2处理完了,并开始输出50Mbit。
2s后,P1处理完了,并开始输出50Mbit,P2的50Mbit输出完了,B2又存入了50Mbit同时处理了25Mbit。
以上关于实现低速预处理模块的文字我是参考的一位博主的文章,博主分析的很透彻。
原文链接:https://blog.youkuaiyun.com/qq_41858135/article/details/121136652
这样确实能够实现把预处理模块的速度降为数据率的1/2,我自己画了一张示意图如下:
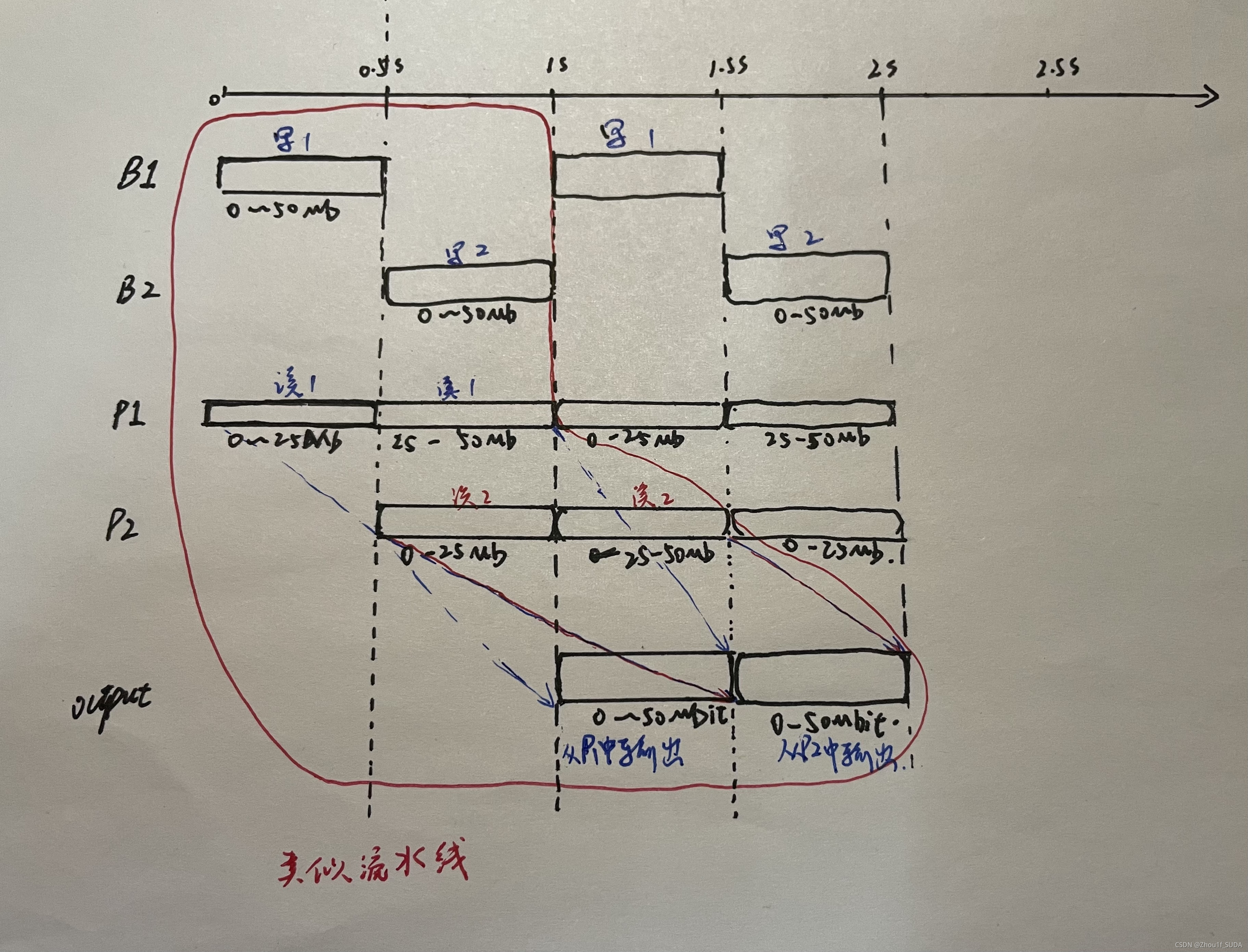
虽然笔者还没开始正式学习这部分的内容,其实这张图里我们就可以看到流水线操作的影子了。这张图就可以解释上述文字描述的情况。可以看到P1或者P2在处理50Mb数据的时用了1s,所以速度就降了一半。
2.Vivado中BRAM IP核的调用
本次实验,我只写了体现前2种特点的一个乒乓缓存。第3种我仅做了如上分析,代码还没写出来。
我们本次采用2块BRAM来实现,调用IP核。
BRAM(block ram)是FPGA中定制的RAM资源,固定分布在FPGA中的某些位置中,输入输出需要时钟的控制,存储量较大。另外一种是DRAM(Distributed RAM)分布式ram,是用逻辑单元拼出来的。
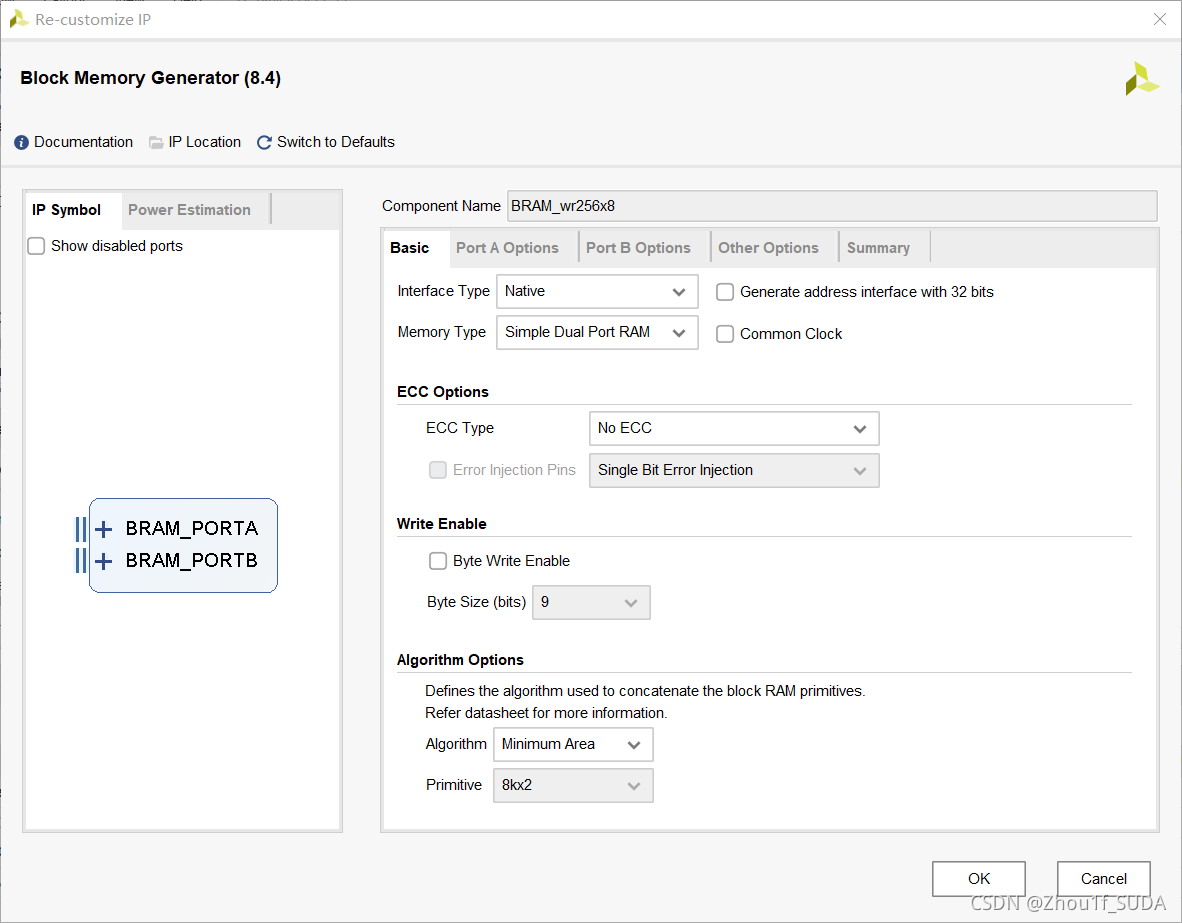
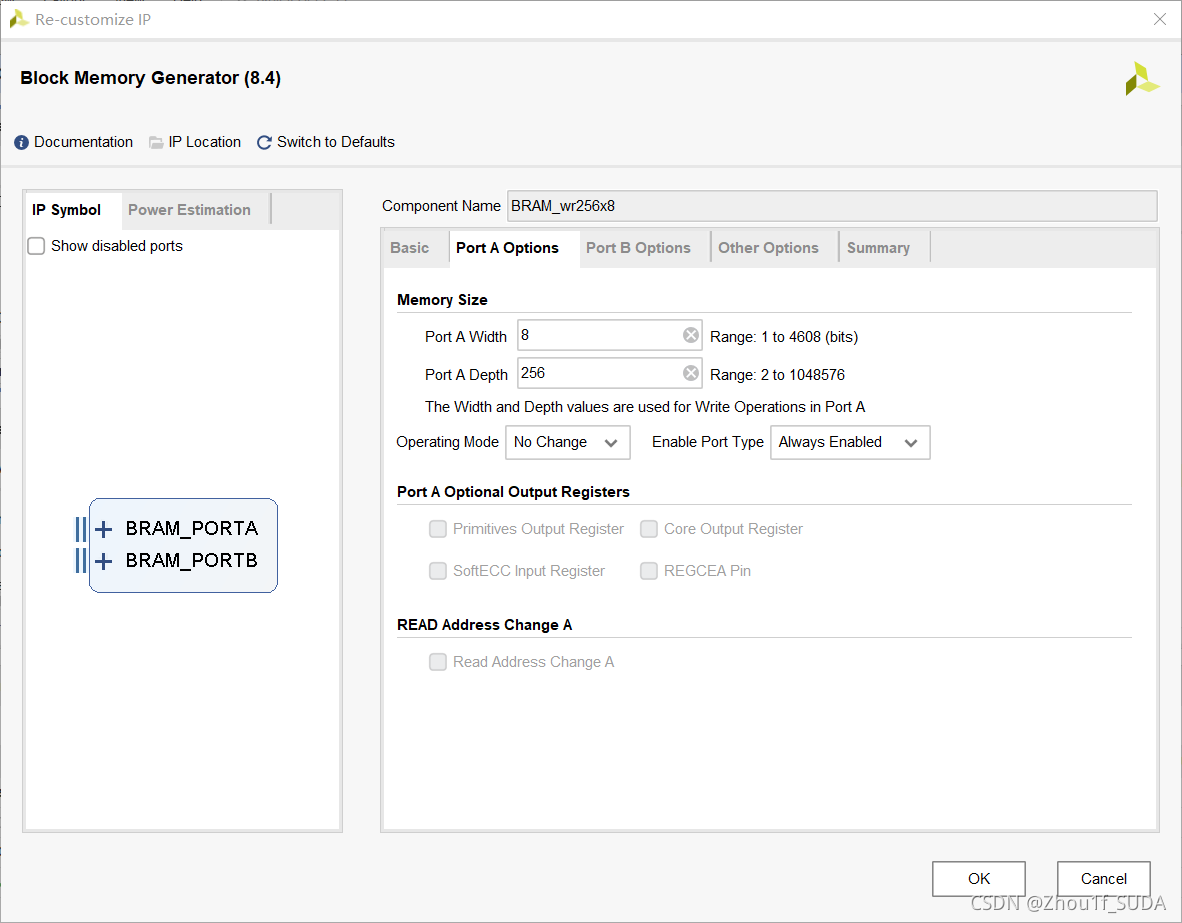
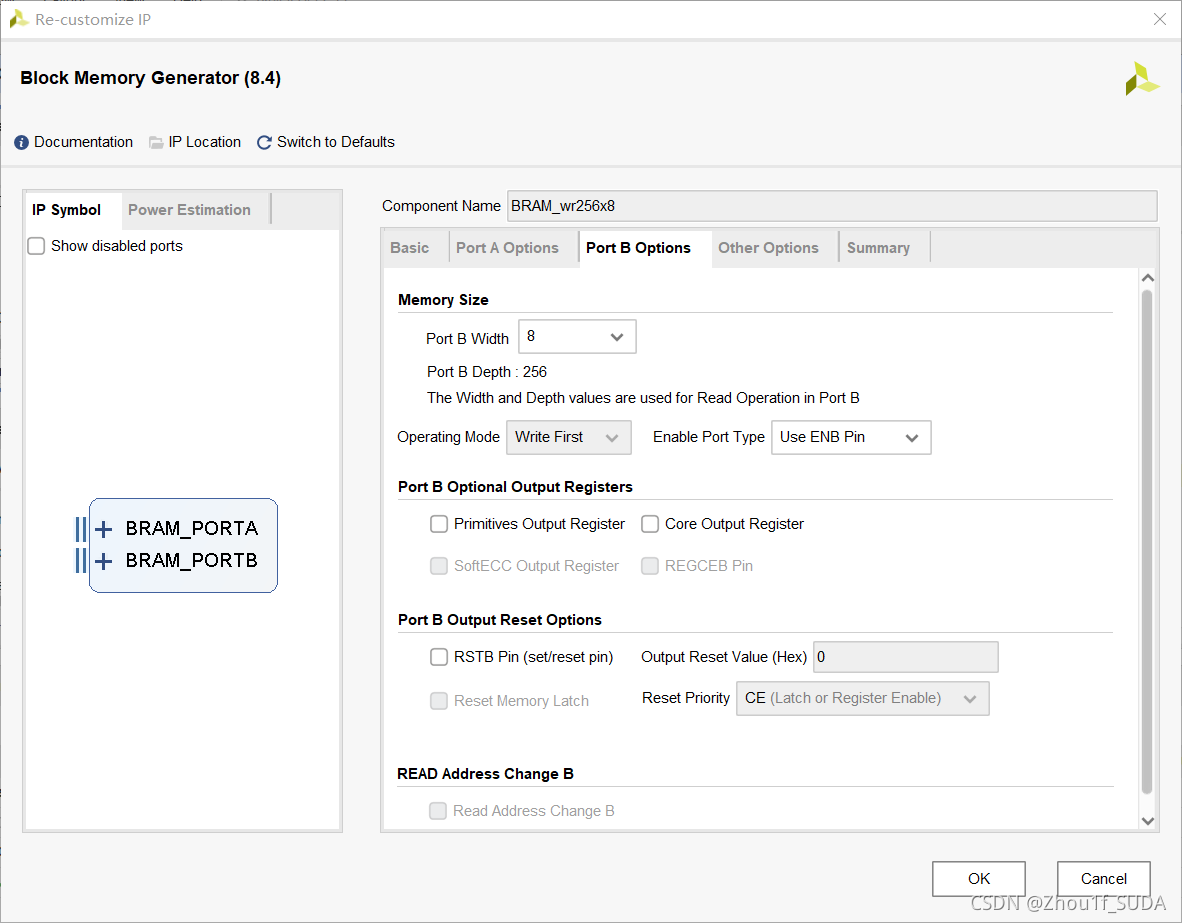
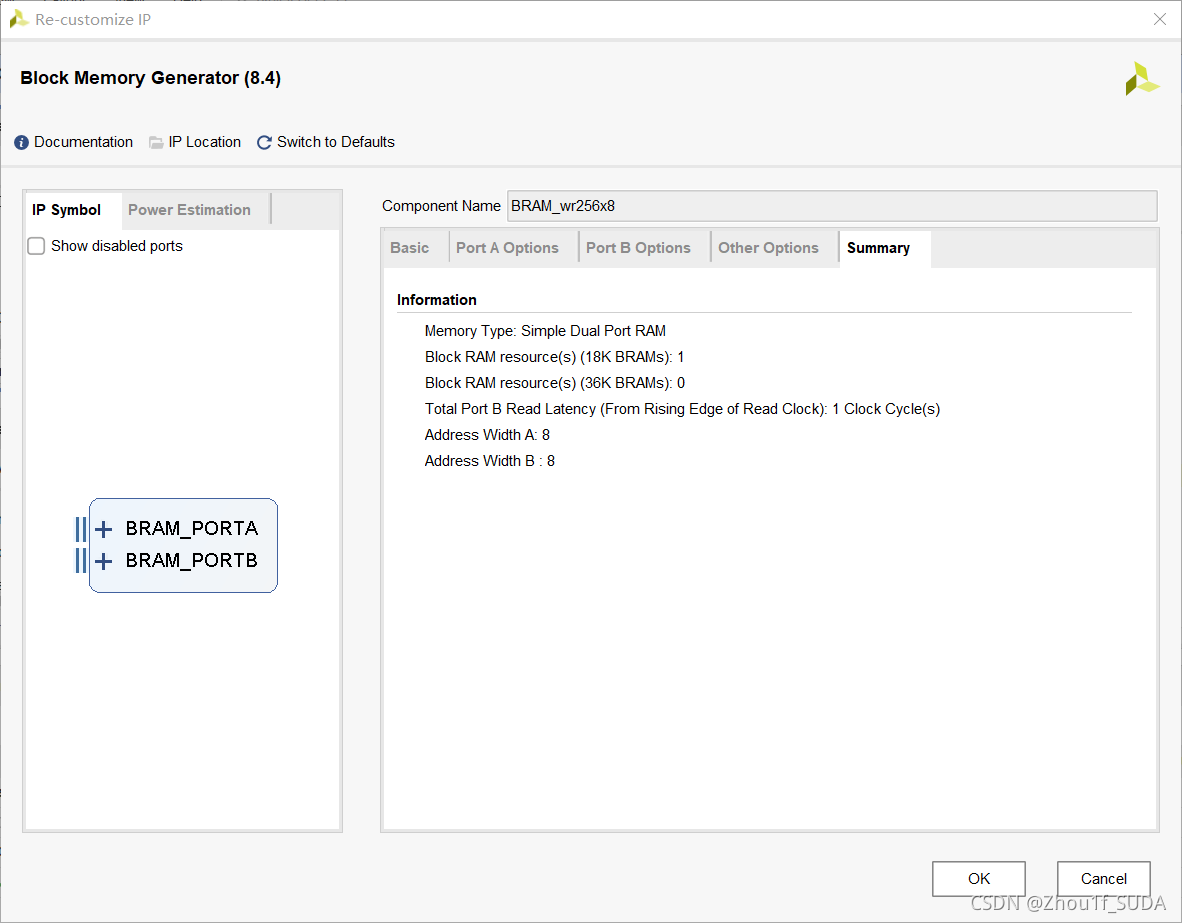
设置如上,设置成simple dual port BRAM,这样就既可以写也可以读了。portA和portB的位宽和深度设置成8*256,即写入和读出端口都设置成一样的位宽和深度。
读出端口不勾选primitive output register,这个只是会影响读出是否会延迟。不勾选,读出会有一个时钟周期的延迟,勾选了就会变成2 clock cycles。
3.代码
设计文件代码如下:
module DPRAM(clk,rst_n,dout);
input clk;
input rst_n;
output [7:0] dout;
reg wr_ramA_en;
reg [7:0] wr_addr_A;
wire [7:0] DinA;
reg [7:0] rd_addr_A;
reg wr_ramB_en;
reg [7:0] wr_addr_B;
wire [7:0] DinB;
reg [7:0] rd_addr_B;
wire [7:0] Dout_A;
wire [7:0] Dout_B;
//用于例化单端口BRAM
wire wea_A;
wire [7:0] addr_A;
wire [7:0]rd_add_A;
wire wea_B;
wire [7:0] addr_B;
wire [7:0]rd_add_B;
assign wea_A =wr_ramA_en;
assign addr_A=wr_addr_A;
assign rd_add_A =rd_addr_A;
assign wea_B =wr_ramB_en;
assign addr_B=wr_addr_B;
assign rd_add_B =rd_addr_B;
reg wr_ramA_delay;//存放打过一拍的ramA写使能信号
reg [7:0] dataout;
parameter MAX = 256-1;
//写使能信号的控制
always @(posedge clk or negedge rst_n)begin
if(!rst_n)begin
wr_ramA_en <=1'b0;
end
else if((wr_addr_A==MAX)&&(wr_ramA_en==1'b1))begin
wr_ramA_en <=1'b0;
end
else if((wr_addr_B==MAX)&&(wr_ramA_en==1'b0))begin
wr_ramA_en <=1'b1;
end
else wr_ramA_en <= wr_ramA_en;
end
//通过组合逻辑把写RAMA和RAMB的使能信号勾连起来,两个信号是相反的
always @(*)begin
wr_ramB_en <= ~wr_ramA_en;
end
//在写使能有效时,写地址随着时钟上升沿逐次加1,与此同时每个地址写入数据
//写ramA
always @(posedge clk or negedge rst_n)begin
if(!rst_n)begin
wr_addr_A <= 'd0;
end
else if(wr_ramA_en==1'b1)begin
if(wr_addr_A==MAX)begin
wr_addr_A <='d0;
end
else wr_addr_A <= wr_addr_A+ 1'b1;
end
else begin
wr_addr_A <= 'd0;
end
end
assign DinA = wr_addr_A;
//读ramB
always @(posedge clk or negedge rst_n)begin
if(!rst_n)begin
rd_addr_B <= 'd0;
end
else if(wr_ramA_en==1'b1)begin
if(rd_addr_B==MAX)begin
rd_addr_B <='d0;
end
else rd_addr_B <= rd_addr_B+ 1'b1;
end
else begin
rd_addr_B <= 'd0;
end
end
//-------------------------------------
//写ramB
always @(posedge clk or negedge rst_n)begin
if(!rst_n)begin
wr_addr_B <= 'd0;
end
else if(wr_ramB_en==1'b1)begin
if(wr_addr_B==MAX)begin
wr_addr_B <='d0;
end
else wr_addr_B <= wr_addr_B+ 1'b1;
end
else begin
wr_addr_B <= 'd0;
end
end
assign DinB =wr_addr_B;
//读ramA
always @(posedge clk or negedge rst_n)begin
if(!rst_n)begin
rd_addr_A <= 'd0;
end
else if(wr_ramB_en==1'b1)begin
if(rd_addr_A==MAX)begin
rd_addr_A <='d0;
end
else rd_addr_A <= rd_addr_A+ 1'b1;
end
else begin
rd_addr_A <= 'd0;
end
end
BRAM_wr256x8 RAM_A (
.clka(clk), // input wire clka
.wea(wea_A), // input wire [0 : 0] wea
.addra(addr_A), // input wire [7 : 0] addra
.dina(DinA), // input wire [7 : 0] dina
.clkb(clk), // input wire clkb
.addrb(rd_add_A), // input wire [7 : 0] addrb
.doutb(Dout_A) // output wire [7 : 0] doutb
);
BRAM_wr256x8 RAM_B (
.clka(clk), // input wire clka//注意这里A端口是写入端口,B端口是读出端口。所以分别会有写入和读出地址。
.wea(wea_B), // input wire [0 : 0] wea
.addra(addr_B), // input wire [7 : 0] addra
.dina(DinB), // input wire [7 : 0] dina
.clkb(clk), // input wire clkb
.addrb(rd_add_B), // input wire [7 : 0] addrb
.doutb(Dout_B) // output wire [7 : 0] doutb
);
always @(posedge clk or negedge rst_n)begin
if(!rst_n)begin
wr_ramA_delay <=1'b0;
end
else wr_ramA_delay<=wr_ramA_en;
end
always @(*)begin
if(wr_ramA_delay==1'b1)begin
dataout <=Dout_B;
end
else
dataout <=Dout_A;
end
assign dout = dataout;
endmodule

















 2649
2649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









