






参考:https://zhuanlan.zhihu.com/p/704342927
由于我对感知部分了解不够,所以主要看规控的部分
主要的收获是:如果周围的智能体是从图像中聚合出来的,那么对于主车的感知几乎是没有的。他们使用了前置摄像头的最小特征图来初始化自我实例特征。
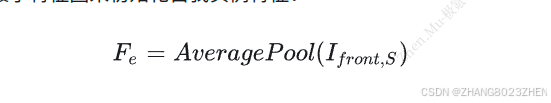
这样做有两个好处:
- 最小特征图已经编码了驾驶场景的语义上下文
- 密集特征图作为稀疏场景的补充,以放存在一些黑名单障碍物,而稀疏感知无法检测到这些障碍物
除了感知的信息,还使用主车的矢量化信息,通过解码来监督主车的位置、速度、转向角等信息。每一帧使用上一帧的预测速度作为自我锚点速度的初始化。
得到这些智能体的信息之后,使用三种交互形式,智能体之间的交互、智能体与地图的交互、智能体与历史帧的交互(场景级的交互)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









