







1 BroadcastState介绍
在开发过程中,如果遇到需要下发/广播配置、规则等低吞吐事件流到下游所有 task 时,就可以使用 Broadcast State。Broadcast State 是 Flink 1.5 引入的新特性。下游的 task 接收这些配置、规则并保存为 BroadcastState, 将这些配置应用到另一个数据流的计算中 。
⚫ 场景举例
- 动态更新计算规则: 如事件流需要根据最新的规则进行计算,则可将规则作为广播状态广播到下游Task中。
- 实时增加额外字段: 如事件流需要实时增加用户的基础信息,则可将用户的基础信息作为广播状态广播到下游Task中。
⚫ API介绍
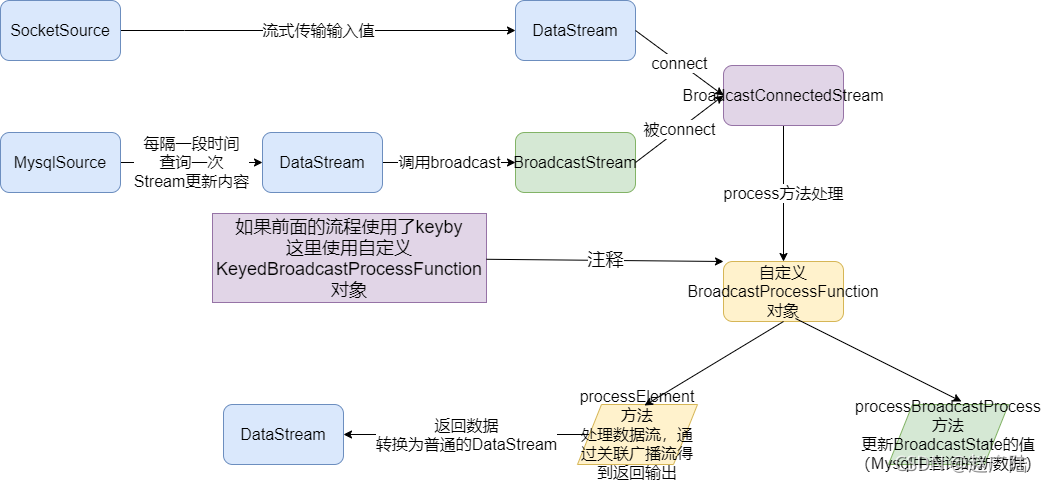
首先创建一个Keyed 或Non-Keyed 的DataStream,然后再创建一个BroadcastedStream,
最后通过DataStream来连接(调用connect 方法)到Broadcasted Stream 上,这样实现将BroadcastState广播到Data Stream 下游的每个Task中。
1.如果DataStream是Keyed Stream ,则连接到Broadcasted Stream 后, 添加处理
ProcessFunction 时需要使用KeyedBroadcastProcessFunction 来实现, 下面是
KeyedBroadcastProcessFunction 的API,代码如下所示:
public abstract class KeyedBroadcastProcessFunction<KS, IN1, IN2, OUT> extends BaseBroadcastProcessFunction {
public abstract void processElement(final IN1 value, final ReadOnlyContext ctx, final Collector<OUT> out) throws Exception;
public abstract void processBroadcastElement(final IN2 value, final Context ctx, final Collector<OUT> out) throws Exception;
}
上面泛型中的各个参数的含义,说明如下:
- KS:表示Flink 程序从最上游的Source Operator 开始构建Stream,当调用keyBy 时所依赖的Key 类型;
- IN1:表示非Broadcast 的Data Stream 中的数据记录的类型;
- IN2:表示Broadcast Stream 中的数据记录的类型;
- OUT:表示经过KeyedBroadcastProcessFunction 的processElement()和processBroadcastElement()方法处理后输出结果数据记录的类型。
2.如果Data Stream 是Non-Keyed Stream,则连接到Broadcasted Stream 后,添加处ProcessFunction 时需要使用BroadcastProcessFunction 来实现, 下面是BroadcastProcessFunction 的API,代码如下所示:
public abstract class BroadcastProcessFunction<IN1, IN2, OUT> extends BaseBroadcastProcessFunction {
public abstract void processElement(final IN1 value, final ReadOnlyContext ctx, final Collector<OUT> out) throws Exception;
public abstract void processBroadcastElement(final IN2 value, final Context ctx, final Collector<OUT> out) throws Exception;
}
上面泛型中的各个参数的含义,与前面KeyedBroadcastProcessFunction 的泛型类型中的后3 个含义相同,只是没有调用keyBy 操作对原始Stream 进行分区操作,就不需要KS 泛型参数。具体如何使用上面的BroadcastProcessFunction,接下来我们会在通过实际编程,来以使用KeyedBroadcastProcessFunction 为例进行详细说明。
⚫ 注意事项
- Broadcast State 是Map 类型,即K-V 类型。
- Broadcast State 只有在广播的一侧, 即在BroadcastProcessFunction 或
KeyedBroadcastProcessFunction 的processBroadcastElement 方法中可以修改。在非广播的一侧, 即在BroadcastProcessFunction 或KeyedBroadcastProcessFunction 的processElement 方
法中只读。 - Broadcast State 中元素的顺序,在各Task 中可能不同。基于顺序的处理,需要注意。
- Broadcast State 在Checkpoint 时,每个Task 都会Checkpoint 广播状态。
- Broadcast State 在运行时保存在内存中,目前还不能保存在RocksDB State Backend 中。
2 需求-实现配置动态更新
实时过滤出配置中的用户,并在事件流中补全这批用户的基础信息。
⚫ 事件流:表示用户在某个时刻浏览或点击了某个商品,格式如下。
{"userID": "user_3", "eventTime": "2019-08-17 12:19:47", "eventType": "browse", "productID": 1}
{"userID": "user_2", "eventTime": "2019-08-17 12:19:48", "eventType": "click", "productID": 1}
⚫ 配置数据: 表示用户的详细信息,在Mysql中,如下。
DROP TABLE IF EXISTS `user_info`;
CREATE TABLE `user_info` (
`userID` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`userName` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`userAge` int(11) NULL DEFAULT NULL,
PRIMARY KEY (`userID`) USING BTREE
) ENGINE = MyISAM CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of user_info
-- ----------------------------
INSERT INTO `user_info` VALUES ('user_1', '张三', 10);
INSERT INTO `user_info` VALUES ('user_2', '李四', 20);
INSERT INTO `user_info` VALUES ('user_3', '王五', 30);
INSERT INTO `user_info` VALUES ('user_4', '赵六', 40);
SET FOREIGN_KEY_CHECKS = 1;
⚫ 输出结果:
(user_3,2019-08-17 12:19:47,browse,1,王五,33)
(user_2,2019-08-17 12:19:48,click,1,李四,20)
3 编码步骤
- env
- source
-1.构建实时数据事件流-自定义随机
<userID, eventTime, eventType, productID>
-2.构建配置流-从MySQL
<用户id,<姓名,年龄>> - transformation
-1.定义状态描述器
MapStateDescriptor<Void, Map<String, Tuple2<String, Integer>>> descriptor =
new MapStateDescriptor<>(“config”,Types.VOID, Types.MAP(Types.STRING,
Types.TUPLE(Types.STRING, Types.INT)));
-2.广播配置流
BroadcastStream<Map<String, Tuple2<String, Integer>>> broadcastDS =
configDS.broadcast(descriptor);
-3.将事件流和广播流进行连接
BroadcastConnectedStream<Tuple4<String, String, String, Integer>, Map<String,
Tuple2<String, Integer>>> connectDS =eventDS.connect(broadcastDS);
-4.处理连接后的流-根据配置流补全事件流中的用户的信息 - sink
- execute
4 代码实现
package cn.oldlu.action;
import org.apache.flink.api.common.state.BroadcastState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.common.state.ReadOnlyBroadcastState;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple4;
import org.apache.flink.api.java.tuple.Tuple6;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.BroadcastConnectedStream;
import org.apache.flink.streaming.api.datastream.BroadcastStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.util.Collector;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
/**
* Author oldlu
* Desc
* 需求:
* 使用Flink的BroadcastState来完成
* 事件流和配置流(需要广播为State)的关联,并实现配置的动态更新!
*/
public class BroadcastStateConfigUpdate {
public static void main(String[] args) throws Exception{
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.source
//-1.构建实时的自定义随机数据事件流-数据源源不断产生,量会很大
//<userID, eventTime, eventType, productID>
DataStreamSource<Tuple4<String, String, String, Integer>> eventDS = env.addSource(new MySource());
//-2.构建配置流-从MySQL定期查询最新的,数据量较小
//<用户id,<姓名,年龄>>
DataStreamSource<Map<String, Tuple2<String, Integer>>> configDS = env.addSource(new MySQLSource());
//3.transformation
//-1.定义状态描述器-准备将配置流作为状态广播
MapStateDescriptor<Void, Map<String, Tuple2<String, Integer>>> descriptor =
new MapStateDescriptor<>("config", Types.VOID, Types.MAP(Types.STRING, Types.TUPLE(Types.STRING, Types.INT)));
//-2.将配置流根据状态描述器广播出去,变成广播状态流
BroadcastStream<Map<String, Tuple2<String, Integer>>> broadcastDS = configDS.broadcast(descriptor);
//-3.将事件流和广播流进行连接
BroadcastConnectedStream<Tuple4<String, String, String, Integer>, Map<String, Tuple2<String, Integer>>> connectDS =eventDS.connect(broadcastDS);
//-4.处理连接后的流-根据配置流补全事件流中的用户的信息
SingleOutputStreamOperator<Tuple6<String, String, String, Integer, String, Integer>> result = connectDS
//BroadcastProcessFunction<IN1, IN2, OUT>
.process(new BroadcastProcessFunction<
//<userID, eventTime, eventType, productID> //事件流
Tuple4<String, String, String, Integer>,
//<用户id,<姓名,年龄>> //广播流
Map<String, Tuple2<String, Integer>>,
//<用户id,eventTime,eventType,productID,姓名,年龄> //需要收集的数据
Tuple6<String, String, String, Integer, String, Integer>>() {
//处理事件流中的元素
@Override
public void processElement(Tuple4<String, String, String, Integer> value, ReadOnlyContext ctx, Collector<Tuple6<String, String, String, Integer, String, Integer>> out) throws Exception {
//取出事件流中的userId
String userId = value.f0;
//根据状态描述器获取广播状态
ReadOnlyBroadcastState<Void, Map<String, Tuple2<String, Integer>>> broadcastState = ctx.getBroadcastState(descriptor);
if (broadcastState != null) {
//取出广播状态中的map<用户id,<姓名,年龄>>
Map<String, Tuple2<String, Integer>> map = broadcastState.get(null);
if (map != null) {
//通过userId取map中的<姓名,年龄>
Tuple2<String, Integer> tuple2 = map.get(userId);
//取出tuple2中的姓名和年龄
String userName = tuple2.f0;
Integer userAge = tuple2.f1;
out.collect(Tuple6.of(userId, value.f1, value.f2, value.f3, userName, userAge));
}
}
}
//处理广播流中的元素
@Override
public void processBroadcastElement(Map<String, Tuple2<String, Integer>> value, Context ctx, Collector<Tuple6<String, String, String, Integer, String, Integer>> out) throws Exception {
//value就是MySQLSource中每隔一段时间获取到的最新的map数据
//先根据状态描述器获取历史的广播状态
BroadcastState<Void, Map<String, Tuple2<String, Integer>>> broadcastState = ctx.getBroadcastState(descriptor);
//再清空历史状态数据
broadcastState.clear();
//最后将最新的广播流数据放到state中(更新状态数据)
broadcastState.put(null, value);
}
});
//4.sink
result.print();
//5.execute
env.execute();
}
/**
* <userID, eventTime, eventType, productID>
*/
public static class MySource implements SourceFunction<Tuple4<String, String, String, Integer>>{
private boolean isRunning = true;
@Override
public void run(SourceContext<Tuple4<String, String, String, Integer>> ctx) throws Exception {
Random random = new Random();
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
while (isRunning){
int id = random.nextInt(4) + 1;
String user_id = "user_" + id;
String eventTime = df.format(new Date());
String eventType = "type_" + random.nextInt(3);
int productId = random.nextInt(4);
ctx.collect(Tuple4.of(user_id,eventTime,eventType,productId));
Thread.sleep(500);
}
}
@Override
public void cancel() {
isRunning = false;
}
}
/**
* <用户id,<姓名,年龄>>
*/
public static class MySQLSource extends RichSourceFunction<Map<String, Tuple2<String, Integer>>> {
private boolean flag = true;
private Connection conn = null;
private PreparedStatement ps = null;
private ResultSet rs = null;
@Override
public void open(Configuration parameters) throws Exception {
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata", "root", "root");
String sql = "select `userID`, `userName`, `userAge` from `user_info`";
ps = conn.prepareStatement(sql);
}
@Override
public void run(SourceContext<Map<String, Tuple2<String, Integer>>> ctx) throws Exception {
while (flag){
Map<String, Tuple2<String, Integer>> map = new HashMap<>();
ResultSet rs = ps.executeQuery();
while (rs.next()){
String userID = rs.getString("userID");
String userName = rs.getString("userName");
int userAge = rs.getInt("userAge");
//Map<String, Tuple2<String, Integer>>
map.put(userID,Tuple2.of(userName,userAge));
}
ctx.collect(map);
Thread.sleep(5000);//每隔5s更新一下用户的配置信息!
}
}
@Override
public void cancel() {
flag = false;
}
@Override
public void close() throws Exception {
if (conn != null) conn.close();
if (ps != null) ps.close();
if (rs != null) rs.close();
}
}
}



















 3343
3343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











