







问题:
etcd leader非预期切换
1.客户端(apiserver)日志:
@#journalctl -u kube-apiserver.service |egrep -i leader
Oct 18 01:07:25 k8s2-master-host kube-apiserver[46885]: E1018 01:07:25.793677 46885 status.go:71] apiserver received an error that is not an metav1.Status: rpctypes.EtcdError{code:0xe, desc:"etcdserver: leader changed"}: etcdserver: leader changed2.etcd日志:
Oct 18 01:07:26 k8s2-etcd-host etcd[36200]: {"level":"warn","ts":"2024-10-18T01:07:26.019943+0800","caller":"etcdserver/v3_server.go:897","msg":"waiting for ReadIndex response took too long, retrying","sent-request-id":11782140720230007501,"retry-timeout":"500ms"}
Oct 18 01:07:26 k8s2-etcd-host etcd[36200]: {"level":"warn","ts":"2024-10-18T01:07:26.397175+0800","caller":"wal/wal.go:805","msg":"slow fdatasync","took":"1.910237721s","expected-duration":"1s"}
Oct 18 01:07:26 k8s2-etcd-host etcd[36200]: {"level":"warn","ts":"2024-10-18T01:07:26.3973+0800","caller":"etcdserver/util.go:170","msg":"apply request took too long","took":"1.878776088s","expected-duration":"100ms","prefix":"read-only range ","request":"key:\"/registry/namespaces/default\" ","response":"","error":"etcdserver: leader changed"}分析:
1.etcd日志里提示“slow fdatasync”,对应的查看etcd主机磁盘监控,对应时刻disk util和write time指标都有抖动
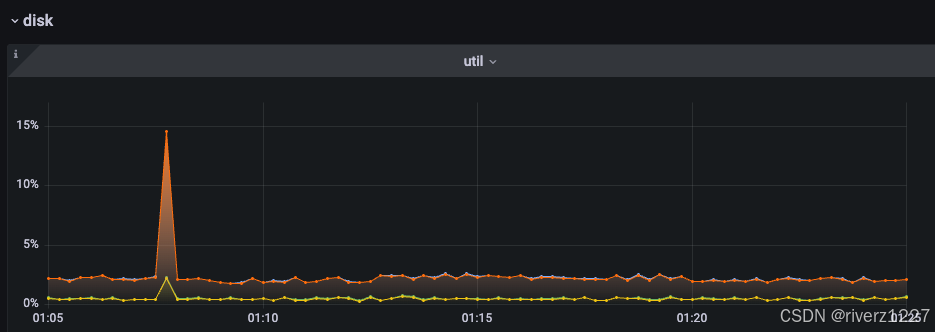
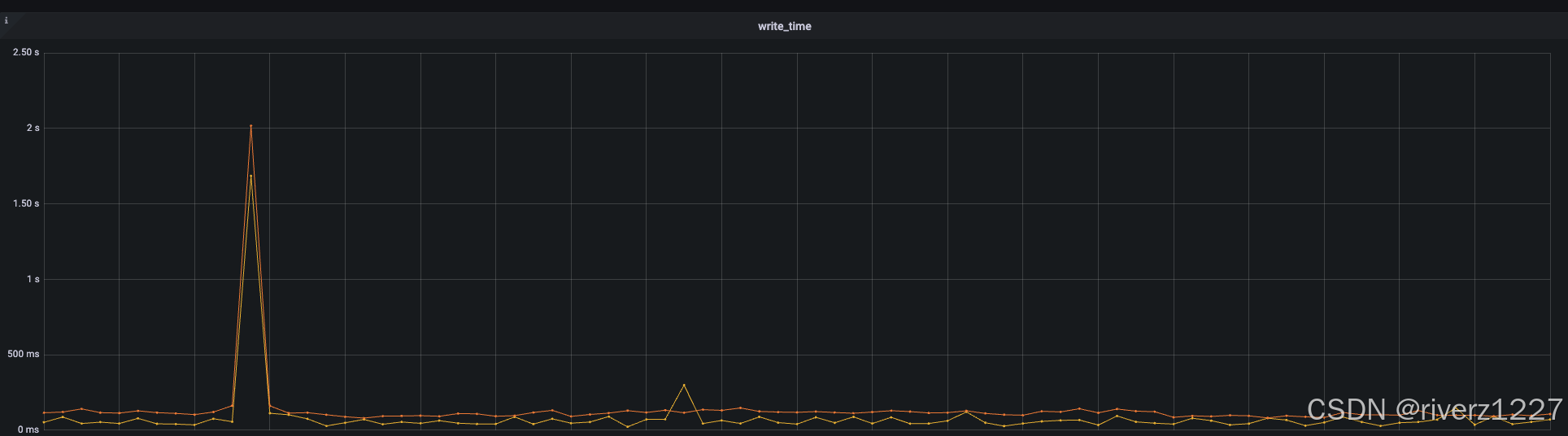
write time指标是计算/proc/diskstats第11列两次采集的差值
正常时候不大于100ms,异常时超过了2s,与日志里"took":"1.910237721s",可以对应的上
2.切换原因
etcd leader 每 100ms 向 follower 发送心跳,维持 leader 地位。
磁盘性能抖动,etcd fdatasync耗时太久,超过 etcd follower选举超时时间(election timeout,默认 1000ms)从而 etcd 其他 follower 节点开始新一轮 leader 选举
etcd 的共识协议依赖于将元数据持久存储到日志 (WAL),因此 etcd 对磁盘写入延迟很敏感

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









