







举例了解tcmalloc
让我们用生活中的例子来解释TCMalloc(Thread-Caching Malloc)的现象:我们可以考虑一个类似于“饮水机、水壶与水杯”的场景,比如我们想要喝水的话,如果没有一些媒介,我们需要直接在水站取水,但是在我们上学时每个宿舍楼都有一个公共饮水机(只考虑一个,不要钻牛角尖),如果每一次想喝水都是直接来喝水,下一次渴了再来喝水,这样饮水机前的队伍大概很拥挤,同时不管对于个人还是群体,喝水的效率都很低。为了提高接水的效率,我们往往都会购买一个水壶,接满满一瓶的水带回寝室,渴了就直接从水壶中取水喝、累了可以泡泡脚,这样既不用再去排队,又很高效使用到它们,如果水壶中的水空了或者不足够我们使用,我们可以再去打水。利用饮水机和水壶的存在,水站->饮水机->水壶->水杯->用水,通过这些媒介,我们可以更高效地获取水,减少排队等待时间(提高了内存分配效率)。
关于上述提到的内存分配效率,在使用水壶时,我们完全可以将其灌满,在需要时取水使用,而使用水杯接水,可能是需要多少就借多少水,这就使得水杯中出现未使用的空间。
TCMalloc 的核心框架就是我们举例中的饮水机->水壶->水杯。
在模拟实现 TCMalloc 前的扩展了解,首先引入的第一个概念就是池化技术的概念。
C/C++中,C语言使用malloc(及其相关的calloc、realloc、free)来管理动态内存,而C++保留了C语言的这些内存管理函数,但也引入了new和delete操作符,以及new[]和delete[]操作符来处理数组。new在实现层面上可能会间接地使用到malloc(或者类似的系统级内存分配函数)来分配内存。
在深入探讨内存池(Memory Pool)与 malloc 的关系之前,我们需要明确几个概念。
池化技术
了解概念即可池化技术(Pooling)是一种在多个领域广泛应用的资源管理策略。
池化技术指的是提前准备一些资源(如线程、数据库连接、内存等),在需要时可以重复使用这些预先准备的资源。这种技术通过减少资源的频繁创建和销毁,降低了系统开销,提高了系统的响应速度和稳定性。
其核心思想在于通过资源的预分配和重用,提高系统的性能和资源利用率。
资源的预分配和重用(原理)
在系统启动时或初始化阶段,根据系统的需求和预期负载,预先分配一定数量的资源到资源池中。当系统需要这些资源时,直接从资源池中获取,而不是新建资源。使用完毕后,资源被放回到资源池中,以供后续请求重用。池化技术的常见类型
线程池:
线程池是一种管理线程的池,通过维护一组可用线程来高效地执行并发任务。
原理:先启动若干数量的线程,并让这些线程都处于等待状态。当有任务需要执行时,唤醒线程池中的某个线程来处理任务,处理完毕后线程再次进入等待状态。
应用场景:广泛用于需要处理并发任务的应用程序,如Web服务器、多线程下载器等。
连接池:
连接池用于管理数据库连接或其他类型连接的复用。
原理:在启动时建立足够数量的连接,并将这些连接组成一个连接池。应用程序通过连接池动态地申请、使用和释放连接。
应用场景:主要用于数据库访问应用程序,如Web应用、企业应用和数据处理任务。
内存池:
内存池是一种内存分配方式,通过预先分配一块连续的内存,并将其分割成多个(固定大小)的对象块,以供后续使用。
原理:在启动时分配大块内存,并将其分割成较小的块。每次申请内存时,从内存池中获取而不是从操作系统申请。
应用场景:适用于需要频繁申请和释放小块内存的应用程序,如图形处理、游戏开发等。
对象池:
对象池用于管理对象的复用,通过维护一组已经创建的对象实例来减少对象的频繁创建和销毁。
原理:维护一组已经创建的对象实例,当需要新对象时从对象池中获取,使用完毕后归还给对象池。
应用场景:通常用于需要频繁创建和销毁对象实例的应用,如图形处理、网络通信等。
缓存池:
缓存池是一种将常用数据或计算结果存储在内存中的技术,以加快对这些数据的访问速度。
原理:将频繁访问的数据或计算结果存储在内存中,减少对慢速存储介质的访问次数。
应用场景:常用于缓存服务器和数据访问层,以提高数据访问的速度和应用程序的响应性。
3.池化技术的优点(了解即可)
- 提高性能:通过减少资源的频繁创建和销毁,降低了系统开销,提高了系统的响应速度和吞吐量。
- 节约资源:资源重用减少了资源的浪费,提高了资源的利用率。
- 简化管理:通过集中管理资源池,简化了资源的分配和回收过程,降低了系统的复杂性。
- 提高可伸缩性:池化技术可以根据系统的负载动态调整资源池的大小,以适应不同的系统需求。
我们所要实现的是高并发内存池,因此将重点着重放在内存池的概念了解上。
了解内存池
内存池是一种内存管理技术,指程序预先从操作系统申请一块连续的内存块,并将其分割成多个固定大小的对象块,此后,当程序中需要申请内存的时候,不是直接向操作系统申请,而是直接从内存池中获取;同理,当程序释放内存的时候,并不是真正将内存返回给操作系统,而是返回内存池。当程序退出(或者特定时间)时,内存池才将之前申请的内存真正释放。这种方式可以减少内存分配和释放的次数,提高内存使用效率,并减少内存碎片(解决直接使用如new、malloc等API申请分配内存时,由于所申请内存块的大小不定,当频繁使用时会造成大量的内存碎片并进而降低性能的问题)。
1.内存池优缺点
内存池优点
- 提高内存分配效率:内存池通过预先分配和管理内存块,减少了内存分配和释放的次数,提高了内存分配的效率。
- 减少内存碎片:由于内存池中的内存块大小固定,避免了因频繁申请不同大小的内存块而产生的内存碎片。
- 简化内存管理:内存池提供了一种统一的内存分配和释放方式,简化了内存管理的复杂性。
- 支持确定性行为:在实时系统中,内存池的使用可以确保内存分配的确定性行为,避免出现内存不足错误。
内存池缺点
- 内存池调整:内存池可能需要为部署它们的应用程序进行调整,以适应不同的内存需求。
- 空间浪费:在某些情况下,如果内存池中的内存块大小与实际需求不匹配,可能会导致一定的空间浪费。
2.内存碎片
在上面的介绍中,我们常看到内存碎片的字眼,那么它的存在是什么样的呢?内存碎片即“碎片的内存”,它分为外碎片和内碎片,内存碎片描述一个系统中所有不可用的空闲内存,这些碎片之所以不能被使用,是因为负责动态分配内存的分配算法使得这些空闲的内存无法使用,这一问题的原因在于这些空闲内存小且以不连续方式出现在不同的位置。因此这个问题的或大或小取决于内存管理算法的实现上。
外碎片和内碎片
外碎片:外部碎片指的是还没有被分配出去(不属于任何进程),但由于太小了无法分配给申请内存空间的新进程的内存空闲区域。频繁的分配与回收物理页面会导致大量的、连续且小的页面块夹杂在已分配的页面中间,从而产生外部碎片。

上图中标注的地方不一定就是外碎片(为了直观看到外碎片位置标注上了),比如现在申请的进程所需内存时大于6M的,这时由于连续的空闲空间太小无法分配给新进程。
内碎片:在内存分配过程中,已经分配给某个进程或对象的内存块中,未被该进程或对象实际使用的部分内存空间。内碎片的产生主要是由于内存分配策略的限制或对齐要求所导致的。
认识第一个内存池——malloc
调用malloc时发生了什么(1) - brk与sbrk-优快云博客
探究malloc | sbrk系统调用的简单使用_malloc 系统调用-优快云博客
malloc 是 C 语言标准库中的一个函数,用于动态地分配内存。malloc()相当于向OS“批发”一大块内存空间,然后“零售”给程序。malloc的实现方式在不同编译器平台是不同的。
然而,标准的 malloc 实现(如 glibc 中的 malloc)并不直接使用内存池的概念,但它可能采用类似于内存池的技术来优化内存分配的效率。
brk()在实现malloc()扩展或缩小堆空间
brk()是一个系统调用,用于调整进程的堆空间大小。在实现malloc()函数时,当需要分配的内存超出了当前堆空间的大小时,可以使用brk()来扩展堆空间。
具体来说,当malloc()函数需要分配一块内存时,它会首先检查当前堆空间是否足够容纳所需的内存。如果足够,malloc()会在堆空间中找到合适的空闲块,并将其分配给请求的内存。但如果堆空间不够,malloc()就需要通过brk()来扩展堆空间。
brk()函数的作用是将进程的堆空间的结束地址(即brk指针)移动到一个新的位置,从而扩展或缩小堆空间的大小。当调用brk()时,需要传入一个新的结束地址作为参数。如果新的结束地址大于当前的结束地址,brk()会将堆空间扩展到新的结束地址;如果新的结束地址小于当前的结束地址,brk()会释放多余的堆空间。
malloc 与 内存池的关系
虽然标准的 malloc 实现可能不直接使用内存池的概念,但许多高性能的库或应用程序会实现自己的内存池来优化内存分配。这些自定义的内存池可能会封装 malloc 的调用,以便在需要时从系统获取更多的内存,但它们会在自己的管理下分配和释放这些内存。实现自定义内存池
初始化内存:在程序启动时或需要时,预先分配一块大的内存作为内存池。
内存分配:当需要从内存池中分配内存时,检查池中是否有足够的空闲空间。如果有,则从池中分配内存;如果没有,则可能需要调用
malloc 来扩展内存池。内存释放:当内存不再需要时,将其释放回内存池而不是直接调用
free。这允许内存池重用这些内存块,从而减少内存分配的开销。内存池管理:内存池需要管理空闲内存块和已分配内存块的信息。这通常通过链表、位图或其他数据结构来实现。
↓↓↓ 设计定长内存池 ↓↓↓
制作一个简单的内存池——定长内存池
虽然标准的 malloc 实现可能不直接使用内存池的概念,但内存池是一种优化内存分配的有效方法。通过实现自定义的内存池,开发者可以针对特定应用的需求来优化内存分配的性能和效率。在需要时,这些自定义的内存池可能会封装 malloc 的调用,以便在必要时从系统获取更多的内存。设计定长内存池(Fixed-Size Memory Pool)是一种优化内存分配和释放效率的技术,特别适用于频繁分配和释放相同大小内存块的场景。这种内存池通过预先分配一大块内存,并在其中管理固定大小的内存块,来减少操作系统内存分配的开销和内存碎片。
定长内存池是一个固定内存申请或释放大小的内存池,其主要特点包括:
性能极致:由于内存池中的内存块大小一致,内存申请和释放操作通常只需要从池中取出或归还相应大小的内存块即可,避免了频繁的系统调用(如malloc和free),从而提高了内存管理效率,特别是在大量进行小对象内存分配和回收的场景下,性能优势更为明显。
减少内存碎片:因为内存池中的所有内存块大小相同,在分配和回收过程中不会产生不同大小的内存空洞,因此能够有效减少内存碎片。

现阶段可能有人会发现我们的分析缺少了一些内容,在后续详细分析中都会说到(这里没有完整说出所有的结构信息,是为了还原一个设计内存池时结构信息不全的场景,我们可以通过后续编写代码时查缺补漏)。
定长内存池的结构
首先,我们需要定义一个内存池的结构体,该结构体包含内存池的基本信息,如**内存块的大小、空闲内存块的链表**等。内存池的功能,申请空间(注意这里的申请是程序从内存池中申请内存,内存池中的一块内存块被分割交给程序使用)和 释放空间(注意这里的释放不是指内存还给操作系统,而是程序归还内存,内存回到内存池或者空间的内存块链表中)
// 创建头文件 ObjectPool.h
template <class T>
class ObjectPool
{
private:
// 定长内存池的结构
// 1.指向从系统申请的内存池
char* _memory;
/* 我们在申请内存时,_memory的指向的位置会发生变化
void* _memory:无类型指针,通用性强,但需要显式转换为其他类型的指针才能使用。
char* _memory:字符指针,可以直接解引用和操作字符数据,
每次移动一个字节,方便根据申请内存块的大小移动。*/
// 2.回收内存时管理内存块的链表
void* _freeList = nullptr;
public:
// 程序向定长内存池申请内存
T* New();
// 程序向定长内存池释放内存
void Delete(T* obj)
};
进行申请和释放空间
1.申请内存
我们申请内存可以通过malloc向系统申请空间,也可以通过系统调用直接向操作系统申请空间:要想直接向堆申请内存空间,在Windows下,可以调用VirtualAlloc函数;在Linux下,可以调用brk或mmap函数。Linux进程分配内存的两种方式–brk() 和mmap() - VinoZhu - 博客园
1.1 通过malloc申请内存(程序向内存池申请内存)
/* 通过malloc申请内存 */
T* New()
{
T* obj = nullptr; // 申请内存的对象 ,后续返回值
// 1. 申请一大块内存
// 怎么申请一大块内存? 通过malloc申请内存
_memory = (char*)malloc(128 * 1024);
if (_memory == nullptr)
{
throw std::bad_alloc();//抛异常机制
}
/* 分割T个字节的内存,我们要注意分辨T类型的字节大,
* 还是32位或64位下的指针字节大,取大的那个作为对象的内存空间 */
// 关于此处为什么要确定一个分割后的内存块至少为一个指针大小的原因在后续会有解释
obj = (T*) _memory;
_memory += max(sizeof(T), sizeof(void*));
return obj;
}
疑问:
- 使用 _memory == nullptr 来判断申请一个大块内存池合理吗?
- 关于申请内存池后,为什么要确定一个分割后的内存块至少为一个指针大小?
- 思考还有哪些在申请过程中需要注意的问题。
1.2 利用回收后的内存块内存空间

/* 1.3 利用回收后的内存块内存空间 */
void*& NextObj(void* obj)
{
return *(void**)obj;
}
// 申请内存
T* New()
{
T* obj = nullptr; // 申请内存的对象 ,后续返回值
// 2. 从回收后的链表中申请内存
if (_freeList != nullptr)
{
/* 链表不为空时,才可以从链表中申请到内存
* 这里我们需要对链表进行操作,比如头删或者尾删
* 鉴于我们的内存块只需要挂在链表上和取下的简单操作,我们使用单链表即可 */
/* 说是单链表,但实际我们不需要创建单链表
* 对于内存块而言,无论是挂上还是取下时,它的内部都没有存储什么信息,
* 它的大小由自身或指针大小决定
* 我们将它的前几位字节作为存放指针的位置,使它指向后方,彷佛就是一个链表 */
/* 申请内存时,就是从链表上取下的时候 */
obj = (T*)_freeList;
_freeList = *(void**)obj; // 指针指向下一内存块
/* 为了代码可读性,我们可以将内存块下一内存块用函数表示出来
* NextObj(obj) = *(void**)obj;
* 对二级指针解引用得到的是存放指针的字节大小,无论是32位还是64位,通过这种操作可以灵活使用
* 不用分32位和64位的情况,取obj前4,或8位字节存放下一内存块地址
*/
/* 以上内容修改为:
* obj = (T*)_freeList;
* _freeList = NextObj(obj);
*/
}
return obj;
}
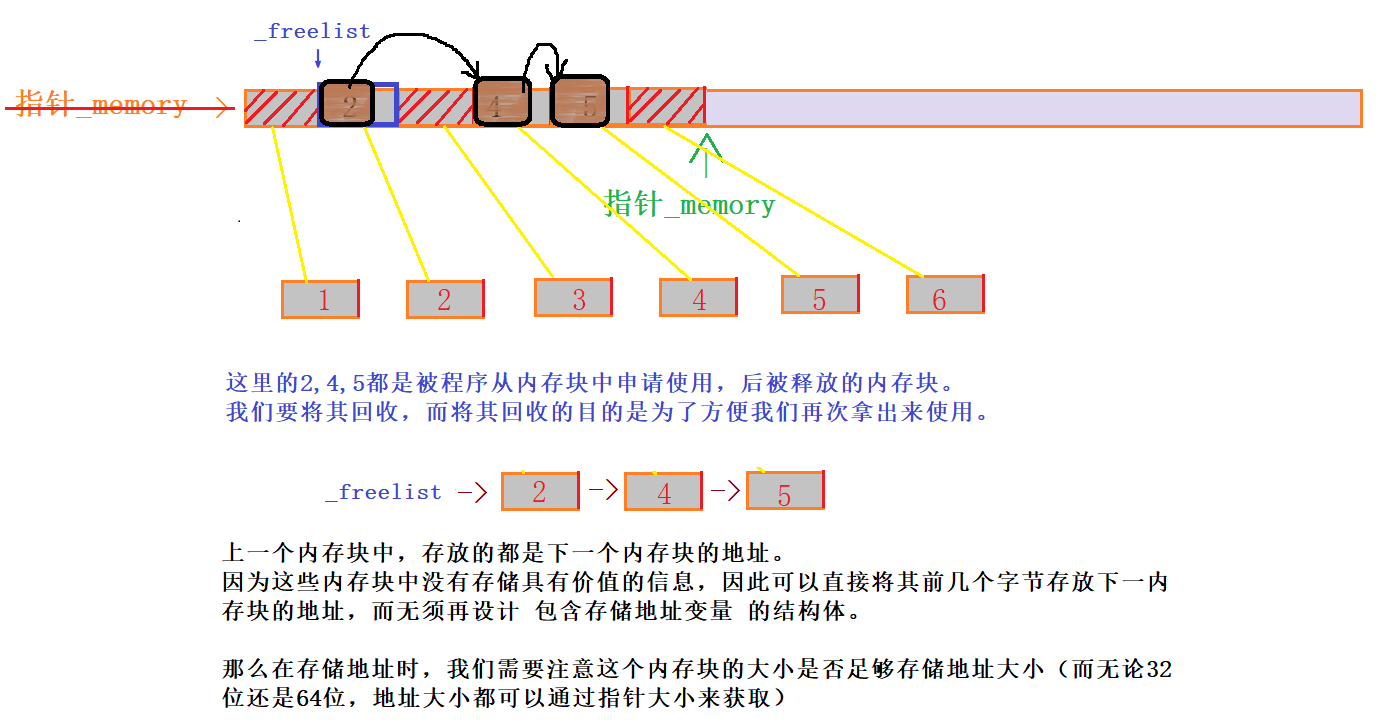
2.申请内存出现的问题
2.1使用 _memory == nullptr 来判断申请一个大块内存池合理吗?
答案:不合理。
当我们的程序一直向内存池申请内存 至 大块内存剩余空间 不足够 申请一个对象 时,我们要怎么做?(如图所示)
当 _memory移动到图中位置时,大块内存的剩余空间不足够再申请一个对象,此时此刻 _memory所指向的地址并不为空,强行申请的结果可能造成越界情况。上列所设计的代码就会失效。

那么我们如何对此进行修改?
通过设计一个判断值来分析大块内存是否足够申请接下来的一个对象,那么这个判断值是使用已分配空间还是剩余空间?
都可以,因为大块内存空间时固定,知道其中一个就可以得到另外一个。
在这里我们通过剩余空间与对象大小直接比较来判断是否要再申请大块内存。
// 定义一个新的成员变量
size_t _remainSize = 0;
/*----------------------------------------------------*/
/*----------------------------------------------------*/
T* New()
{
T* obj = nullptr;
// 要申请的内存大小为bytes
size_t bytes = max(sizeof(T), sizeof(void*));
// 在一大块内存块中申请
// 1.内存块中的内存是否足够申请内存
if (_remainSize < bytes)
{
_memory = (char*)malloc(128 * 1024);
if (_memory == nullptr)
{
throw std::bad_alloc();// 抛异常机制
}
_remainSize += 128 * 1024; // 剩余内存大小会发生变化
}
// 2.内存块中的内存足够申请内存时
obj = (T*)_memory;
_memory += bytes;
_remainSize -= bytes;
return obj;
}
2.2申请内存是否要注意哪些内存块要先消耗?
我们的程序在向我们设计的定长内存池申请内存时,只需要通过New()函数进行申请,但是将内存池中空闲的内存块分配给这些程序的顺序还需要考虑。1.从大块内存中再切割新的内存块获得空间(_memory);
2.从已使用后释放回收的内存块中获得空间( _freeList)。
在我们的链表中有回收的内存块时,我们应当优先使用这些内存块,否则等到_memory的大块内存条消耗到重新申请了一块内存,再持续使用大块内存条,链表中回收的内存块始终得不到利用。
2.3申请内存代码整理
因此,我们得到最后的申请内存的代码为:/* 2.3申请内存代码整理 */
//template<size_t N> // 非类型的模板参数,定长为N
template<class T>
class ObjectPool
{
private:
// 1. 一个申请到的大块内存块
char* _memory = nullptr;
// 2. 一个回收内存块的链表
void* _freeList = nullptr;
// 3. 判断大块内存块剩余空间(是否足够再一次定长的内存块申请)
size_t _remainSize = 0;
public:
void*& NextObj(T* obj) {
return *(void**)obj;
}
// 申请内存
T* New()
{
T* obj = nullptr; // 申请内存的对象 ,后续返回值
// 2. 从回收后的链表中申请内存
if (_freeList)
{
/* 申请内存时,就是从链表上取下的时候 */
obj = (T*)_freeList;
_freeList = NextObj(obj);
}
else {
// 1.1.2 直接向操作系统申请内存
/* 直接向操作系统申请内存意味着你可以绕过标准库的内存管理层,
* 直接使用系统提供的API(如 Linux 的 mmap 或 Windows 的 VirtualAlloc)来请求内存 */
if (_remainSize < sizeof(T))
{
_remainSize = 128 * 1024;
_memory = (char*)malloc(128*1024);
if (_memory == nullptr)
{
throw std::bad_alloc();//抛异常机制
}
}
obj = (T*)_memory;
size_t objSize = sizeof(T) > sizeof(void*) ? sizeof(T) : sizeof(void*);
_memory += objSize;
_remainSize -= objSize;
}
new(obj)T;// 使用定位new调用T的构造函数 初始化
return obj;
}
// 释放内存
void Delete(T* obj)
{
// 显示调用T的析构函数进行清理
obj->~T();
// 回收内存到链表中去
// 头插法
NextObj(obj) = _freeList;
_freeList = obj;
}
};
直接向操作系统申请内存中的条件编译的内容不在代码中赘述。
2.4定位new表达式的使用
定位 new 表达式的基本形式是 new (ptr) Type()。
- ptr 是一个指向已分配内存的指针;
- Type 是要构造的对象的类型。
这个表达式在 ptr 指向的内存上调用 Type 的构造函数来构造一个对象,但不分配新的内存。
这也意味着当我们创建一个类型为T的对象时,我们同时可以对其进行初始化。这样就相当于C++为我们提供的new函数。
3.释放内存
注意程序释放内存是将申请的内存块归还,并不是将内存释放归还给操作系统。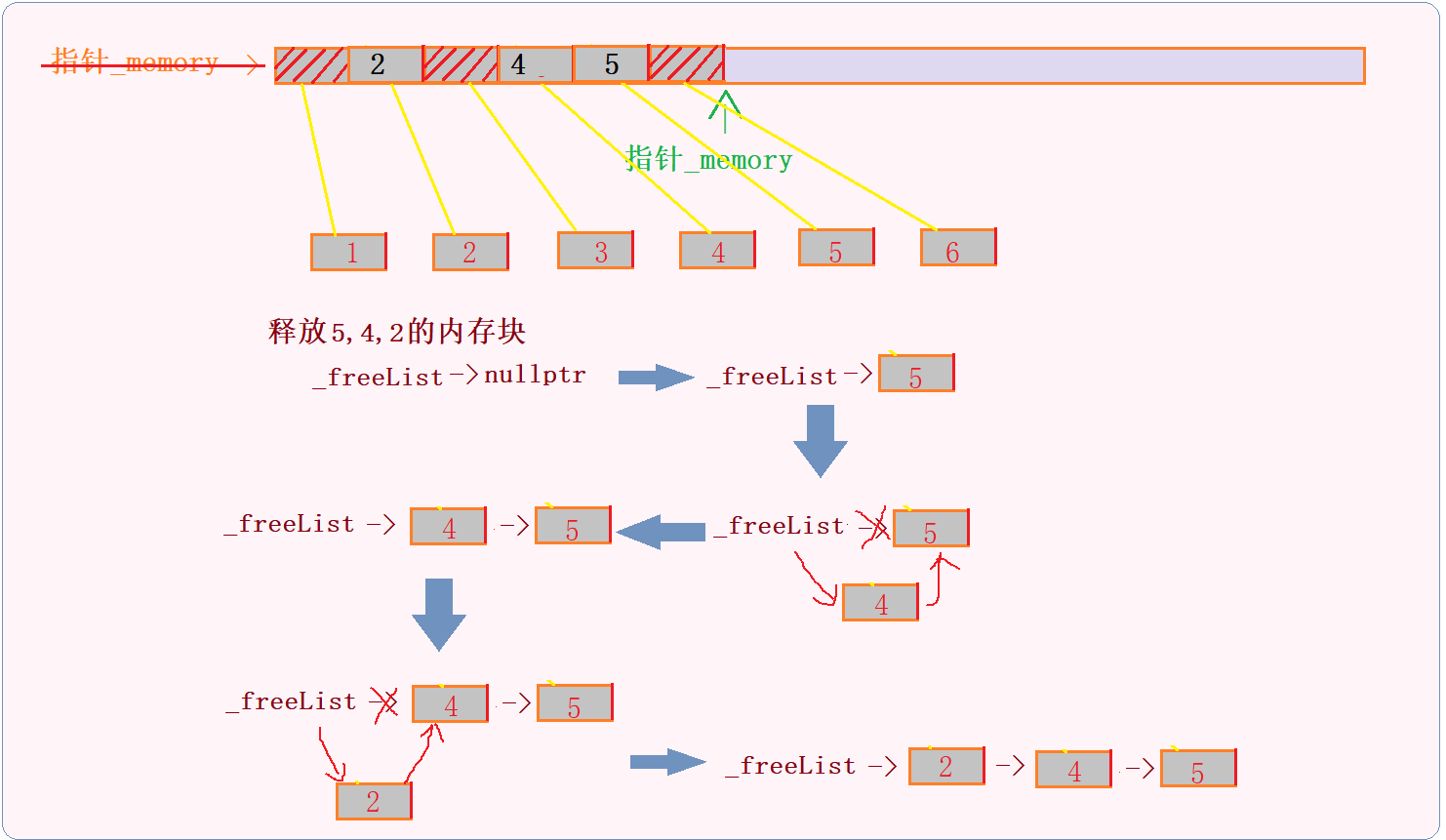
/* 3.释放内存 */
// 释放内存
void Delete(T* obj)
{
// 显示调用T的析构函数进行清理
obj->~T();
// 将归还回来的内存块的地址存放在上一个回收完成的内存块中,回收内存到链表中去
// 使用头插还是尾插的方式?
// 头插法
NextObj(obj) = _freeList;
_freeList = obj;
}
这个函数首先手动调用对象obj的析构函数obj->~T();
这一行显式地调用了对象obj的类型T的析构函数,以确保对象被正确地销毁,包括清理其内部资源(如动态分配的内存、文件句柄等)。然后,该函数将这个已销毁对象的内存地址添加到一个空闲链表(_freeList)中去,以便后续重用。
手动调用对象obj的析构函数是必要的,因为当使用new操作符动态分配内存并创建对象时,对象的构造函数会自动被调用,但析构函数不会自动在对象作用域结束时被调用(与局部自动变量不同)。如果不手动调用析构函数,那么对象可能不会被正确地销毁,导致资源泄露或其他问题。
4.程序申请和释放内存时所要注意的问题(设计程序本身)
正确地调用程序的构造函数和析构函数。
- 避免对象创建时没有进行初始化;
- 销毁对象时造成资源泄露等问题。
直接向操作系统申请内存——优化定长内存池
在Windows下,可以调用VirtualAlloc函数;在Linux下,可以调用brk或mmap函数// 直接去堆上申请按页申请空间
/* 在Windows下,可以调用VirtualAlloc函数;在Linux下,可以调用brk或mmap函数
* 使用条件编译,根据不同的平台选择不同的头文件
* _WIN32 宏在32位和64位Windows上都定义,
* 因此单独检查 _WIN32 而不排除 _WIN64 ,会导致在64位Windows上也执行32位分支的代码
* 或者 不判断定义64位,将_WIN64放在_WIN32前也可以
*/
#ifdef _WIN64
#include <Windows.h>
#elif defined(_WIN32) && !defined(_WIN64)
/* 检查是否定义了 _WIN32 宏但没有定义 _WIN64 宏,
* 这适用于32位Windows系统。
* 如果条件满足,也包含 <Windows.h> 头文件。
*/
#include <Windows.h>
#elif defined(__linux__)
#include <sys/mman.h> // 对于Linux
#include <fcntl.h> //<fcntl.h> 实际上不是必需的。
#include <unistd.h>
// 可能还需要其他Linux特定的头文件或定义
#else
#error "Unsupported platform" //#else 和 #error 指令用于捕获不支持的平台,并在编译时生成错误。
#endif
inline static void* SystemAlloc(size_t kpage)
{
#ifdef _WIN64
return VirtualAlloc(0, kpage << 13, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
/* void* ptr = VirtualAlloc(0, kpage * (1 << PAGE_SHIFT),MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
if (ptr == nullptr)
throw std::bad_alloc();
return ptr;
* 通常情况下不会申请失败,所以上面未注释的代码就不进行检查了
*/
#elif _WIN32
return VirtualAlloc(0, kpage << 12, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
#elif __linux__
//brk mmap等
/* 只在Linux上执行
* 在Linux上,函数使用 mmap 来分配内存。
* 这里使用了匿名映射(MAP_ANONYMOUS),并且文件描述符(fd)被设置为 -1,因为不需要映射到文件。
*
*/
void* ptr = mmap(0, kpage << 12, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
if (ptr == MAP_FAILED) { //如果内存分配失败(在Linux上 mmap 返回 MAP_FAILED),则函数返回 NULL。
return NULL;
}
return ptr;
#else
// 由于前面的#error,这行代码实际上不会执行
// 但为了保持函数完整性,这里保留了返回NULL的语句
return NULL;
#endif
}
// 申请内存
// 直接向操作系统申请内存
/* 直接向操作系统申请内存意味着你可以绕过标准库的内存管理层,
* 直接使用系统提供的API(如 Linux 的 mmap 或 Windows 的 VirtualAlloc)来请求内存 */
_memory = (char*)SystemAlloc(128 * 1024 >> 13);
//申请128*1024内存大小,一页8kb,右移13位求出多少页
if (_memory == nullptr)
{
throw std::bad_alloc();//抛异常机制
}
此处了解到的函数,在后续创建内存池向os申请内存时才会使用到,这里作为了解查看即可。
测试定长内存池
#include "ObjectPool.h"
struct TreeNode
{
int _val;
TreeNode* _left;
TreeNode* _right;
TreeNode()
:_val(0),
_left(nullptr),
_right(nullptr) {}
};
void TestObjectPool()
{
// 申请释放的轮次
const size_t Rounds = 3;
// 每轮申请释放多少次
const size_t N = 100000;
size_t begin1 = clock();
std::vector<TreeNode*> v1;
v1.reserve(N);
for (size_t j = 0; j < Rounds; ++j)
{
for (int i = 0; i < N; ++i)
{
v1.push_back(new TreeNode);
}
for (int i = 0; i < N; ++i)
{
delete v1[i];
}
v1.clear();
}
size_t end1 = clock();
ObjectPool<TreeNode> TNPool;
size_t begin2 = clock();
std::vector<TreeNode*> v2;
v2.reserve(N);
for (size_t j = 0; j < Rounds; ++j)
{
for (int i = 0; i < N; ++i)
{
v2.push_back(TNPool.New());
}
for (int i = 0; i < N; ++i)
{
TNPool.Delete(v2[i]);
}
v2.clear();
}
size_t end2 = clock();
cout << "new cost time:" << end1 - begin1 << endl;
cout << "ObjectPool cost time:" << end2 - begin2 << endl;
}
int main()
{
TestObjectPool();
return 0;
}
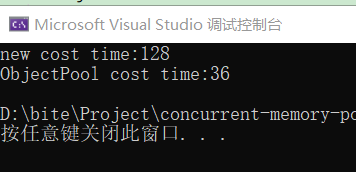
一种是直接使用new和delete操作符来分配和释放TreeNode对象,另一种是通过自定义的BMPool(内存池)来分配和释放TreeNode对象。
我们通过测试可以获得使用定长内存池的效率远高于使用new的效率(记得测试时加上对应的头文件)
定长内存池的源码链接

















 828
828

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









