







NLP-Assign-02
本次作业包括:
- 利用nltk库进行文本切分、标准化(包括消除标点符号、大小写转换、去除停用词)、词干提取、词形还原、词频统计
- 基于中文词典对句子进行匹配
- 正向最大匹配算法
- 逆向最大匹配算法
- 双向最大匹配算法
- jieba分词的四种模式尝试
任务描述:IMDB电影评论处理
使用IMDB电影部分评论,进行切分、标准化(消除标点符号、大小写转换、去停用词等)、词干提取、词形还原以及高频词统计的训练。
**输入:**使用开源数据索引,下载IMDB电影评论数据集,使用其中部分评论(积极消极共20条),已下载在本地的data文件夹中。
http://ai.stanford.edu/~amaas/data/sentiment/
**输出:**每一步都需要输出,如
Tokenization: ["don't", 'hesitate', 'to', 'ask', 'questions', '.', 'he', 'works', 'happily', '.']
Normalization: ['dont', 'hesitate', 'ask', 'questions', 'works', 'happily']
Stemming: ['dont', 'hesit', 'ask', 'quest', 'work', 'happy']
Lemmatization: ['dont', 'hesitate', 'ask', 'question', 'work', 'happily']
Freq: 统计词频,按顺序从高到低列出前十个单词
代码
import nltk
from nltk.tokenize import RegexpTokenizer
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
from nltk.stem import WordNetLemmatizer
from collections import Counter
from pyecharts.charts import Bar
from pyecharts import options as opts
import json
import os
# 将所有评论存进text中
text = []
file_list = os.listdir('data/')
for file in file_list:
f_obj = open('data/'+file, 'r')
line = f_obj.readline()
text.append(line)
# print(text[0])
# 文本切分+去除标点
tokenized_text = []
for obj in text:
tokenizer = RegexpTokenizer(r'\w+')
tokenized_text.append(tokenizer.tokenize(obj))
# print(tokenized_text[0])
# 文本标准化
normalized_text = []
for words in tokenized_text:
# 转换为小写
words = [word.lower() for word in words]
# 去除停用词
stop_words = set(stopwords.words("english"))
words = [word for word in words if word not in stop_words]
normalized_text.append(words)
# print(normalized_text[0])
# 词干提取
stemmed_text = []
for words in normalized_text:
stemmer = PorterStemmer()
stemmed_words = [stemmer.stem(word) for word in words]
stemmed_text.append(stemmed_words)
# print(stemmed_text[0])
# 词形还原
lemmatized_text = []
for words in normalized_text:
lemmatizer = WordNetLemmatizer()
lemmatized_words = [lemmatizer.lemmatize(word) for word in words]
lemmatized_text.append(lemmatized_words)
# print(lemmatized_text[0])
# 词频统计
all_words = [word for words in lemmatized_text for word in words]
freq = Counter(all_words).most_common(10)
# 将结果写入JSON文件
results = {
"tokenized_text": tokenized_text,
"normalized_text": normalized_text,
"stemmed_text": stemmed_text,
"lemmatized_text": lemmatized_text,
"word_frequencies": freq
}
with open("ex1_result.json", "w") as json_file:
json.dump(results, json_file, indent=4)
word_counts = Counter(all_words)
top_10_words = word_counts.most_common(10)
# 创建柱状图
words, counts = zip(*top_10_words)
bar = (
Bar()
.add_xaxis(list(words))
.add_yaxis("词频", list(counts))
.set_global_opts(title_opts=opts.TitleOpts(title="Top 10 单词词频"))
)
bar.render("word_frequency_bar_chart.html")
输出
json文件略
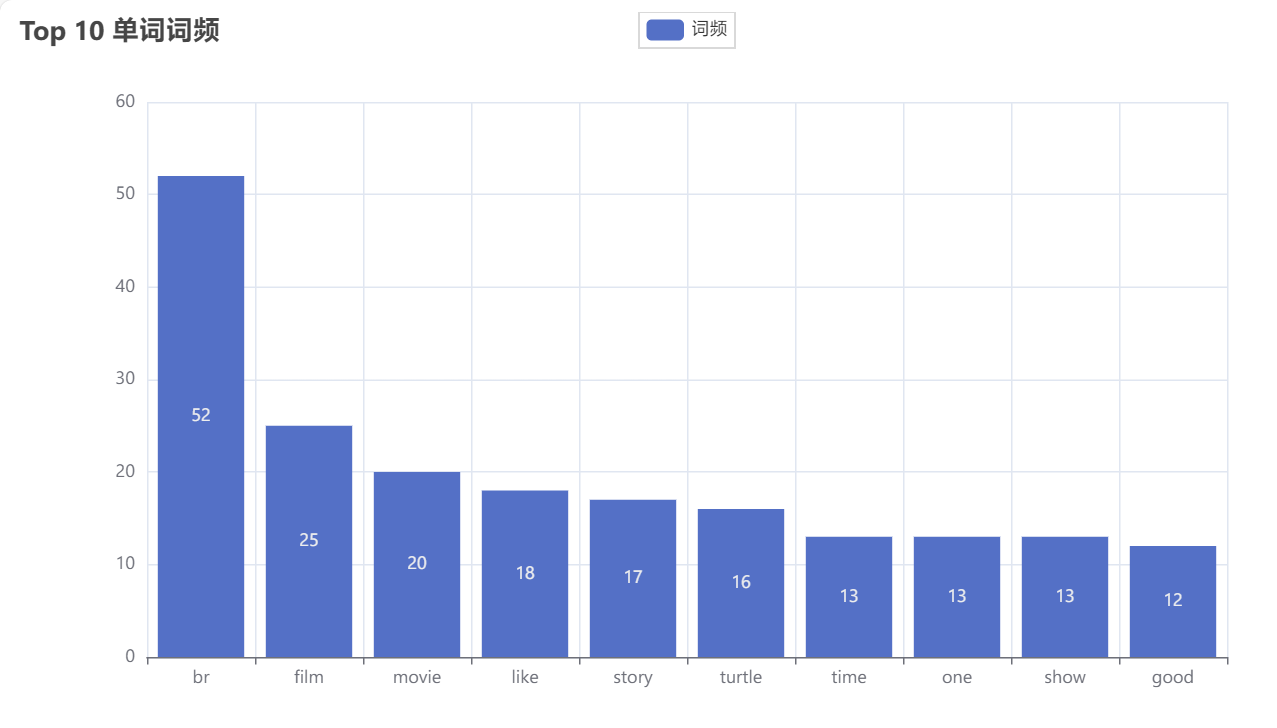
柱状图:
任务描述:基于规则的中文分词方法
-
依据给定的文本和词表,实现
- 正向最大匹配
- 逆向最大匹配
- 双向最大匹配
-
jieba分词使用尝试
三种匹配算法的实现
-
正向匹配算法FMM:
双指针(指针
i为当前扫描到的字符,指针j表示从i开始往后扫描的字符长度)因此当前匹配到的字符串就是原字符串的
i到i+j位(记原字符串为words,则当前匹配到的字符串记为words[i:i+j])接下来只需要检索词典中是否存在
words[i:i+j]注意:
j要从MAX_LENGTH递减,以优先匹配出词典中较长的词语 -
逆向匹配算法RMM:
同样双指针,只不过
i从字符串末尾开始递减,j同上,从MAX_LENGTH递减当前匹配到的字符串就是
words[i-j:i] -
双向匹配算法BMM

如上图,综合考虑三种判定规则然后选择匹配效果最好的一种
我的想法:
分别为正向/逆向匹配设置一个指数index,然后通过不同规则对index进行加减运算
比较正向/逆向的index大小,输出结果(在我的代码设计中,index越大代表匹配效果越好)
但这里的index计算公式中,每个变量的系数/次方是我假定的(理论上应该会有不同的权重)
i n d e x = ∑ i = 0 n − 1 l e n ( w o r d s [ i ] ) 2 − ∑ w o r d n o t i n d i c t ∣ s i n g l e w o r d l e n ( w o r d ) − l e n ( w o r d s ) index=\sum_{i=0}^{n-1}len(words[i])^{2}-\sum_{word\ not\ in\ dict|single\ word}len(word)-len(words) index=i=0∑n−1len(words[i])2−word not in dict∣single word∑len(word)−len(words)
sentences = {
0: '南京市长江大桥成功落建',
1: '北京大学生前来应聘',
2: '北京大学生喝进口红酒',
3: '在北京大学生活区喝进口红酒',
4: '这块地面积还真不小'
}
dictionary = []
dict_file = open('./dict/dict.txt.small', 'r', encoding='utf-8')
for line in dict_file.readlines():
line=line.strip('\n')
dictionary.append(line)
# 逆向最大匹配
def RMM(sentence, dictionary, max_length):
words = []
i = len(sentence) # 从末尾开始匹配
while i > 0:
for j in range(max_length, 0, -1):
if i - j >= 0:
word = sentence[i - j:i]
if word in dictionary:
words.insert(0, word) # 插入到结果列表的开头
i -= j
break
else:
# 无法找到匹配的词,将当前字符作为单字词
words.insert(0, sentence[i - 1])
i -= 1
return words
# 正向最大匹配
def FMM(sentence, dictionary, max_length):
words = []
i = 0
# i为当前扫描到的字符,j为正在匹配的字符串长度
# 双循环,对sentence中每个i位置的字符,向后分别匹配1~max_length位的字符串,并检查是否在词典中
while i < len(sentence):
for j in range(max_length, 0, -1):
if i + j <= len(sentence):
word = sentence[i:i+j]
if word in dictionary:
words.append(word)
i += j
break
else:
# 无法找到匹配的词,将当前字符作为单字词
words.append(sentence[i])
i += 1
return words
# 统计非字典词/单字字典词
def SingleWords(words, dictionary):
count = 0
for word in words:
if word not in dictionary:
count += len(word) # 对非字典词:计算每个非字典词的长度,index减去该长度
if len(word) == 1:
count += 1 # 对单字字典词:index减去单字字典词的个数
return count
# 双向最大匹配
def BMM(sentence, dictionary, max_length):
FMM_words = FMM(sentence, dictionary, n)
RMM_words = RMM(sentence, dictionary, n)
FMM_index = 0
RMM_index = 0
# 大颗粒度词
# 分别计算两种匹配算算法结果中,每个word的长度的平方,累加到index上
# index越大,整体颗粒度越大
for word in FMM_words:
FMM_index += len(word) * len(word)
for word in RMM_words:
RMM_index += len(word) * len(word)
# 非字典词/单字字典词
# 非字典词/单字字典词越少,index越大
FMM_index -= SingleWords(FMM_words, dictionary)
RMM_index -= SingleWords(RMM_words, dictionary)
# 总词数
# index减去总词数(总词数越少,index越大)
FMM_index -= len(FMM_words)
RMM_index -= len(RMM_words)
return FMM_words if FMM_index > RMM_index else RMM_words
MAX_LENGTH = 5
n = 2
# 循环匹配单词最大长度2~5
while n <= MAX_LENGTH:
print("单词最大长度:", n, "\n")
for i, sentence in sentences.items():
print(f"句子{i}: {sentence}")
BMM_words = BMM(sentence, dictionary, n)
FMM_words = FMM(sentence, dictionary, n)
RMM_words = RMM(sentence, dictionary, n)
print("双向最大匹配:", BMM_words)
print("正向最大匹配:", FMM_words)
print("逆向最大匹配:", RMM_words)
n += 1
jieba分词
对sentences字典内每一句话尝试结巴分词的全模式,精确模式,新词模式和搜索引擎模式
import jieba
sentences = {
0:'没有什么比时间更具有说服力了,因为时间无需通知我们就可以改变一切。',
1:'检验一个人的标准,就是看他把时间放在了哪儿。别自欺欺人;当生命走到尽头,只有时间不会撒谎。',
2:'近年来,卷积神经网络因其优异的性能,在计算机视觉、自然语言处理等各个领域受到了研究者们的青睐',
3:'来自北京大学、东方理工、南方科技大学和鹏城实验室等机构的研究团队提出了一种语义可解释人工智能的研究框架,该框架从语义层面解释了卷积神经网络的学习机制。'
}
# 全模式
full_mode_results = {}
for key, sentence in sentences.items():
full_mode_results[key] = jieba.cut(sentence, cut_all=True)
# 精确模式
accurate_mode_results = {}
for key, sentence in sentences.items():
accurate_mode_results[key] = jieba.cut(sentence, cut_all=False)
# 新词模式
new_word_mode_results = {}
for key, sentence in sentences.items():
new_word_mode_results[key] = jieba.cut(sentence, HMM=True)
# 搜索引擎模式
search_engine_mode_results = {}
for key, sentence in sentences.items():
search_engine_mode_results[key] = jieba.cut_for_search(sentence)
# 打印分词结果
for key, sentence in sentences.items():
print(f'Sentence {key}: {sentence}')
print(f'全模式: {" / ".join(full_mode_results[key])}')
print(f'精确模式: {" / ".join(accurate_mode_results[key])}')
print(f'新词模式: {" / ".join(new_word_mode_results[key])}')
print(f'搜索引擎模式: {" / ".join(search_engine_mode_results[key])}')
print()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









