







 本文介绍使用KNN、朴素贝叶斯及SVM等算法对电影评论进行情感分类的方法,并对比了不同距离度量方式和模型的准确性。
本文介绍使用KNN、朴素贝叶斯及SVM等算法对电影评论进行情感分类的方法,并对比了不同距离度量方式和模型的准确性。
1. 使用sklearn的KNN做分类
import nltk
from sklearn.neighbors import KNeighborsClassifier
from nltk.corpus import movie_reviews
import random
from nltk.corpus import stopwords
import numpy as np
###看一下影评的格式###
# for category in movie_reviews.categories():
# print(category)
# #查看各标签包含的文件
# print(movie_reviews.fileids("neg"))
# print(movie_reviews.fileids("pos"))
# #看一下文件里的内容与文件的长度
# print(movie_reviews.words("pos/cv938_10220.txt"))
# print(len(movie_reviews.words("pos/cv938_10220.txt")))
###将影评和标签转换为二元组的测试###
# tuple1 = [list(movie_reviews.words("pos/cv938_10220.txt")),"pos"]
# print(tuple1)
# #使用列表生成式 转化为词列表的影评,与标签,组成二元组
documents = [(list(movie_reviews.words(fileid)),category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]
# print(documents[0])
random.shuffle(documents)
# #获取影评的频率分布情况
all_words = nltk.FreqDist(w.lower() for w in movie_reviews.words())
# print(list(all_words))
#词频表按频率排序
all_words=all_words.most_common(2000)
# print(all_words)
stop_words=stopwords.words("english")
# 去停用词
word_features =[w for (w,f) in all_words if w not in stop_words]
# print(len(word_features))
# len(documents)是共有2000条影评,1880列去停用词之后的
# 2000*1880的矩阵
features = np.zeros([len(documents),len(word_features)],dtype=float)
for n in range(len(documents)):
# 获取每个文件中的词
document_words = set(documents[n][0])
# print(document_words)
for m in range(len(word_features)):
if word_features[m] in document_words:
features[n,m] = 1 # 文件-词集矩阵
target=[c for (d,c) in documents]
train_set=features[:1500,:]
target_train=target[:1500]
test_set=features[1500:,:]
target_test=target[1500:]
knnclf = KNeighborsClassifier(n_neighbors=7)#default with k=5
knnclf.fit(train_set,target_train)
pred = knnclf.predict(test_set)
print(sum([1 for n in range(len(target_test)) if pred[n]==target_test[n] ])/len(target_test))正确率:0.61
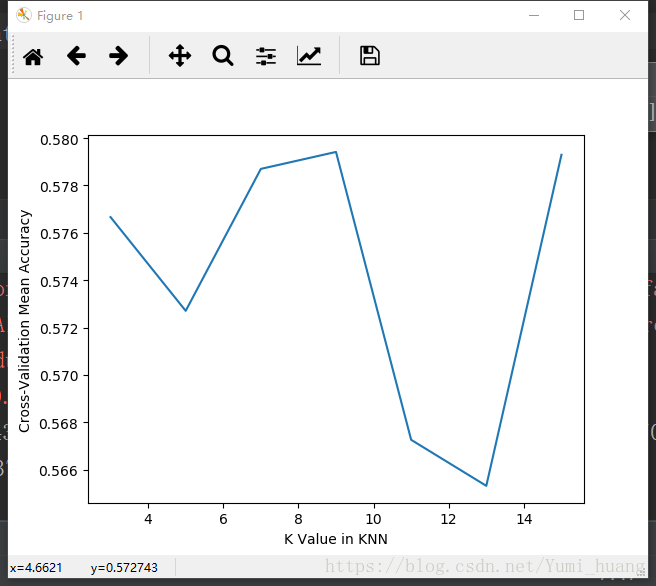
使用海明距离、余弦距离、欧式距离的KNN分类器
交叉验证:
from sklearn.cross_validation import cross_val_score
import matplotlib.pyplot as plt
X =[3,5,7,9,11,13,15]
k_scores = []
for k in X:
knnclf = KNeighborsClassifier(n_neighbors=k)
scores = cross_val_score(knnclf,train_set,target_train,cv=10)
k_scores.append(scores.mean())
print(k_scores)
plt.plot(X, k_scores)
plt.xlabel('K Value in KNN')
plt.ylabel('Cross-Validation Mean Accuracy')
plt.show()结果:

from scipy.spatial import distance
import nltk
from nltk.corpus import movie_reviews
import random
from nltk.corpus import stopwords
import numpy as np
def euc(a,b):#计算欧氏距离
return distance.euclidean(a,b)
def hamming(a,b): #计算海明距离
# 两个长度相等的字符串的海明距离是在相同位置上不同的字符的个数,也就是将一个字符串替换成另一个字符串需要的替换的次数。
return distance.hamming(a,b)
def cos(a,b): #余弦距离
return distance.cosine(a,b)
class ScrappyKnn():
def fit(self,X_train,y_train):
self.X_train=X_train
self.y_train=y_train
def predictEuc(self,X_test):
predictions=[]
for row in X_test:
label= self.eucclosest(row)
predictions.append(label)
return predictions
def predictHamming(self,X_test):
predictions = []
for row in X_test:
label = self.hamclosest(row)
predictions.append(label)
return predictions
def predictcos(self,X_test):
predictions = []
for row in X_test:
label = self.cosclosest(row)
predictions.append(label)
return predictions
def eucclosest(self,row):
best_dist=euc(row,self.X_train[0])
best_index=0
for i in range(1,len(self.X_train)):
dist=euc(row,self.X_train[i])
if dist < best_dist :
best_dist = dist
best_index=i
return self.y_train[best_index]
def hamclosest(self,row):
best_dist=hamming(row,self.X_train[0])
best_index=0
for i in range(1,len(self.X_train)):
dist=hamming(row,self.X_train[i])
if dist < best_dist :
best_dist = dist
best_index=i
return self.y_train[best_index]
def cosclosest(self,row):
best_dist=cos(row,self.X_train[0])
best_index=0
for i in range(1,len(self.X_train)):
dist=cos(row,self.X_train[i])
if dist < best_dist :
best_dist = dist
best_index=i
return self.y_train[best_index]
def main():
documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]
random.shuffle(documents)
all_words = nltk.FreqDist(w.lower() for w in movie_reviews.words())
all_words = all_words.most_common(2000)
stop_words = stopwords.words("english")
word_features = [w for (w, f) in all_words if w not in stop_words]
features = np.zeros([len(documents), len(word_features)], dtype=float)
for n in range(len(documents)):
# 获取每个文件中的词
document_words = set(documents[n][0])
# print(document_words)
for m in range(len(word_features)):
if word_features[m] in document_words:
features[n, m] = 1 # 文件-词集矩阵
target = [c for (d, c) in documents]
train_set = features[:1500, :]
target_train = target[:1500]
test_set = features[1500:, :]
target_test = target[1500:]
my_classifier = ScrappyKnn() # 调用上面写好的KNN分类器
my_classifier.fit(train_set, target_train) # 训练
pred1 = my_classifier.predictEuc(test_set)
print("使用欧氏距离:")
print(sum([1 for n in range(len(target_test)) if pred1[n] == target_test[n]]) / len(target_test))
pred2 = my_classifier.predictHamming(test_set)
print("使用海明距离:")
print(sum([1 for n in range(len(target_test)) if pred2[n] == target_test[n]]) / len(target_test))
pred3 = my_classifier.predictcos(test_set)
print("使用余弦距离:")
print(sum([1 for n in range(len(target_test)) if pred3[n] == target_test[n]]) / len(target_test))
if __name__ == '__main__':
main()准确率:
使用欧氏距离:
0.51
使用海明距离:
0.51
使用余弦距离:
0.658
2.朴素贝叶斯的三种模型
原理:贝叶斯模型是把后验概率转换为先验概率进行计算的过程。朴素即是假设各特征之间相互独立,即假设样本的每个特征与其他特征都不相关。
当特征是离散的时候,使用多项式模型;
当特征是连续变量的时候,运用多项式模型就会导致很多P(xi|yk)=0(不做平滑的情况下),此时即使做平滑,所得到的条件概率也难以描述真实情况。所以处理连续的特征变量,应该采用高斯模型;
与多项式模型一样,伯努利模型适用于离散特征的情况,所不同的是,伯努利模型中每个特征的取值只能是1和0(以文本分类为例,某个单词在文档中出现过,则其特征值为1,否则为0).
from sklearn.naive_bayes import GaussianNB
from sklearn.naive_bayes import MultinomialNB
from sklearn.naive_bayes import BernoulliNB
import nltk
from nltk.corpus import movie_reviews
from nltk.corpus import stopwords
import numpy as np
import random
documents = [(list(movie_reviews.words(fileid)),category) for category in movie_reviews.categories() for fileid in movie_reviews.fileids(category)]
random.shuffle(documents)
all_words = nltk.FreqDist(w.lower() for w in movie_reviews.words())
all_words = all_words.most_common(2000)
stop_words = stopwords.words("english")
word_features = [w for (w,f) in all_words if w not in stop_words]
features = np.zeros([len(documents),len(word_features)],dtype=float)
for n in range(len(documents)):
document_words = set(documents[n][0])
for m in range(len(word_features)):
if word_features[m] in document_words:
features[n,m] = 1 # 文件-词集矩阵
target=[c for (d,c) in documents]
train_set=features[:1500,:]
target_train=target[:1500]
test_set=features[1500:,:]
target_test=target[1500:]
#######选取贝叶斯训练模型########
gauNB = GaussianNB()
gauNB.fit(train_set,target_train)
pred = gauNB.predict(test_set)
print("高斯模型准确率:"+str(sum([1 for n in range(len(target_test)) if pred[n]==target_test[n] ])/len(target_test)))
mulNB = MultinomialNB()
mulNB.fit(train_set,target_train)
pred = mulNB.predict(test_set)
print("多项式模型准确率:"+str(sum([1 for n in range(len(target_test)) if pred[n]==target_test[n] ])/len(target_test)))
berNB = GaussianNB()
berNB.fit(train_set,target_train)
pred = berNB.predict(test_set)
print("伯努利模型准确率:"+str(sum([1 for n in range(len(target_test)) if pred[n]==target_test[n] ])/len(target_test)))
结果:

3.SVM
from sklearn.svm import SVC
import nltk
from nltk.corpus import movie_reviews
from nltk.corpus import stopwords
from sklearn.model_selection import GridSearchCV
import numpy as np
import random
documents = [(list(movie_reviews.words(fileid)),category) for category in movie_reviews.categories() for fileid in movie_reviews.fileids(category)]
random.shuffle(documents)
all_words = nltk.FreqDist(w.lower() for w in movie_reviews.words())
all_words = all_words.most_common(2000)
stop_words = stopwords.words("english")
word_features = [w for (w,f) in all_words if w not in stop_words]
features = np.zeros([len(documents),len(word_features)],dtype=float)
for n in range(len(documents)):
document_words = set(documents[n][0])
for m in range(len(word_features)):
if word_features[m] in document_words:
features[n,m] = 1 # 文件-词集矩阵
target=[c for (d,c) in documents]
train_set=features[:1500,:]
target_train=target[:1500]
test_set=features[1500:,:]
target_test=target[1500:]
# svc= SVC()
# svc.fit(train_set,target_train)
# pred = svc.predict(test_set)
# print("支持向量机准确率:"+str(sum([1 for n in range(len(target_test)) if pred[n]==target_test[n] ])/len(target_test)))
tuned_parameters = [{'kernel': ['rbf','poly','linear','sigmoid']}]
svm_clf = GridSearchCV(SVC(), tuned_parameters, cv=10)
svm_clf.fit(train_set,target_train)
print("The best parameters are %s with a score of %0.2f" % (svm_clf.best_params_,svm_clf.best_score_))运行结果:


















 1188
1188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









