






目录
Python基础
数据
一 、int : 整型
二 、float : 浮点型
三 、bool :布尔型
1.布尔型通常用于判断,有固定写法:True(真),False(假)。严格区分大小写。
2.可当做整型对待,True相当于1,False相当与0,True+False=1
四 、complex : 复数型
固定写法:z=a+bj a为实部,b为虚部,j为虚部单位
字符串 str
特点:需要加上引号,单、双引号都可以,多行可用三引号。
一、字符串编码
本质上就是二进制数据与语言文字的一一对应关系
1.Unicode:
多有字符都是2个字节
好处:字符与数字之间转换速度更快一些
坏处:占用空间大
2.UTF-8
精准,对不同的字符用不同的长度表示
优点:节省空间
缺点:字符与数字的转换速度较慢,每次都需要计算字符要用多少个字节来表示。
3.转换方式:
(1) encode():编码
(2) decode():解码
例:
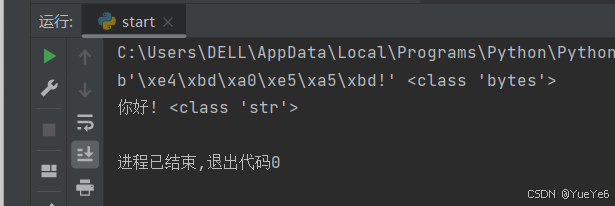
str = "你好!"
a1 = str.encode("UTF-8")
print(a1,type(a1))
a2 = a1.decode("UTF-8")
print(a2,type(a2))
二、下标/索引
作用:通过下标能够快速找到对应的数据。
写法: 字符串名 [下标值]
注意:python中下标通常是从0开始,从右往左数下标从-1开始,-1、-2、-3···
例:
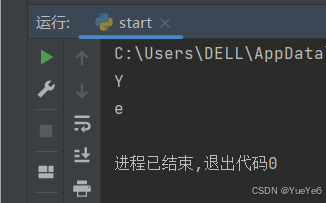
name = "Yuye"
print(name[0])
print(name[-1])
三、切片
指对操作的对象截取其中一部分的操作。
语法:[开始位置:结束位置:步长]
步长表示选取间隔,不写步长,则默认为1,绝对值大小决定切取的间隔,正负号决定切取的方向。
例:
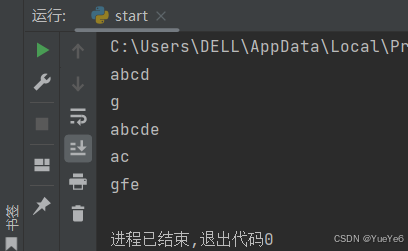
a = "abcdefg"
print(a[0:4])
print(a[-1:])
print(a[:-2])
print(a[0:4:2])
print(a[-1:-4:-1])### 字符串常见操作
四、字符串常见操作
1.查找
(1)find()
格式:find(子字符串,开始位置下标,结束位置下标)
作用:检测某个子字符串是否包含在字符串中,如果在就返回字符串开始位置下标,否则就返回-1,包前不包后。
(2)index()
格式:index(子字符串,开始位置下标,结束位置下标)
与find唯一区别就是找不到时会报错。
(1)count()
格式:count(子字符串,开始位置下标,结束位置下标)
返回某个子字符串在整个字符串中出现的次数,没有就返回0,包前不包后。
例:
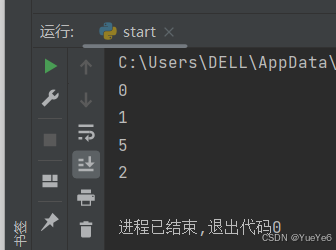
a = "learnmore"
print(a.find("learn"))
print(a.find("ear"))
print(a.index("more"))
print(a.count("r"))
2.判断
(1)startswitch()
是否以某个子字符串开头,是的话就返回True,不是的话就返回False。
格式:startwitch(子字符串,开始位置下标,结束位置下标)
(2)endswitch()
是否以某个子字符串结尾,是的话就返回True,不是的话就返回False。
格式:endswitch(子字符串,开始位置下标,结束位置下标)
(3)isupper()
检测字符串中所有的字母是否都是大写,是的话返回True。
例:
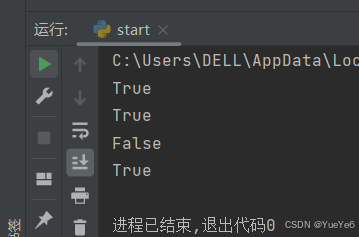
a = "learnmore"
print(a.startswith("learn"))
print(a.endswith("ore"))
print(a.isupper())
print("BIG".isupper())
3.修改
(1)replace():替换
格式:replace(旧内容,新内容,替换次数)
注:替换次数可以省略,默认全部替换。
(2)split():制定分隔符来切字符串
(3)capitalize():第一个字符大写,其他都小写
(4)lower():大写字母转为小写
(5)upper():小写字母转为大写
例:
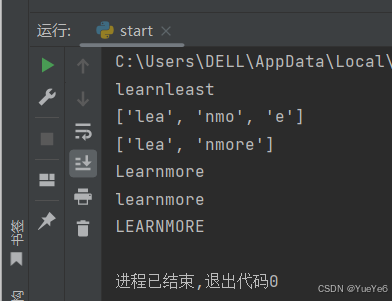
a = "learnmore"
print(a.replace("more","least"))
print(a.split("r"))
print(a.split("r",1))
print(a.capitalize())
print(a.lower())
print(a.upper())
占位符
占位符只是占据位置,并不会被输出。作用
生成一定格式的字符串
一、%
1. %s:字符串
2. %d:整数
%4d:数字设置位数,不足前面不空白。
例: %04d,位数为4,不足前面补0。
3. %f:浮点数
%0.4f:数字设置小数位数,遵循四舍五入。
二、f格式化
格式为:f " {表达式} " 例:
name = "YueYe"
age = 20
print(f"我的名字是{name},我今年{age}岁了。")
运算符
一、算术运算符
“+”:加
“-”:减
“*”:乘
“/”:除 商为浮点数,除数不为0。
“//”:取整数
“%”:取余数
“** ”:幂 m**n代表m的n次方
优先级: 幂 > 乘、除、取余、取整数 > 加减
二、赋值运算符
“=”
“+=” :先+后=,例:a+1=a 等效于 a+=1
“-=” :先-后=,例:a-1=a 等效于 a-=1
“+=”、“-=”必须连着写,中间不能有空格。
三、比较运算符
1.“==”
比较是否相等,相等返回值为True,不等返回值为False。
2.“!=”
比较是否相等,不等返回值为True,相等返回值为False。
3.“>”、“<”、“>=”、“<=”
四、逻辑运算符
1.“and”
and左右两边都符合才为真。
2.“or”
or左右两边只需要一边符合就为真。
3.“not”
表示相反的结果。
五、三目运算(三元表达式)
基本格式: 为真结果 if 判断语句 else 为假结果
例:
a = 10
b = 20
max_value = a if a>b else b
print(max_value)
六、字符串运算符
“+”:字符串拼接
“*”:重复输出
例:
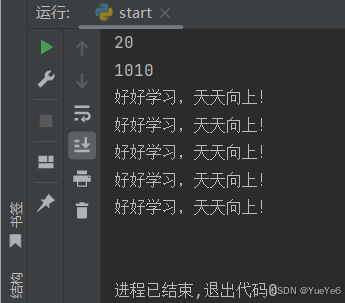
print(10 + 10)
print("10"+"10")
print("好好学习,天天向上!\n"*5)
七、成员运算符:
作用:检查字符串中是否包含了某子字符串。
1.“in”:
如果包含的话,返回True,不包含返回false。
2.“not in”:
如果不包含的话,返回True,包含返回false。
例:
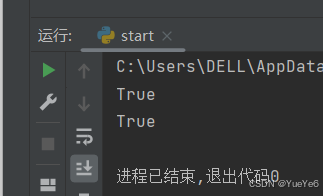
a = "abc"
print("a" in a)
print("A" not in a)
转义字符
1.\t :制表符
通常表示四个字符,也称缩进。
2.\n : 换行符
表示将当前位置移动到下一行开头。
3.\r :回车
表示将当前位置移动到本行开头。
4.\ :反斜杠符号
5.r’ ’ :原生字符串,默认取消转义
例:print(r'a///b')
if 语句
一、if判断
格式:
if 要判断的条件:
条件成立的时候要做的事情
二、if-else (二选一)
格式:
if 要判断的条件:
条件成立的时候要做的事情
else: #else后面不需要添加任何条件
不满足条件要做的事
三、if-elif (多选一)
格式:
if 条件1:
满足条件1要做的事
elif 条件2:
满足条件2要做的事情
elif 条件3:
满足条件3要做的事情
...
四、if-elif-else
格式:
if 条件1:
满足条件1要做的事
elif 条件2:
满足条件2要做的事情
elif 条件3:
满足条件3要做的事情
...
else:
不满足条件要做的事
五、if嵌套
格式:
if 条件1
事件1
if 条件2
事件2
...
else:
不满足条件的事情
内层if判断和 外层if判断都可以是if-else结构
循环语句
while循环:
基本语法:
定义初始变量
while 条件1:
循环体
改变变量
例:
i = 1
j = 0
while i <= 100:
j += i
i += 1
print(j)
死循环:
while True:
循环体 #只要条件不是False或0,其他单独存在的值也会是死循环
while 循环嵌套 :
一个我while循环里还有一个while循环
格式:
while 条件1:
循环体1 #缩进决定层次,严格控制缩进,最好自动缩进
while 条件2:
循环体2
改变变量2
改变变量1
for循环(迭代循环):
基本格式:
for 临时变量 in 可迭代对象: #可迭代对象是指要去遍历取值的整体,例如字符串。
循环体
例:
str = "hello python!"
for i in str:
print(i,end=",")
range(): 用来记录循环语句,相当于一个计数器。
格式:range(start,stop,step)
range()里面只写一个数时,这个数就是循环的次数,默认从0开始;写两个数时,前面的数字代表开始的位置,后面的数字代表结束位置,包前不包后
例:
j = 0
for i in range(1,101):
j += i
print(j)
break和continue
都是专门在循环中使用的关键字
break:某一条件满足时,退出循环。
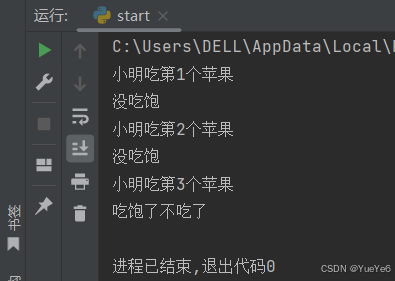
例:
for i in range(1,5):
print(f"小明吃第{i}个苹果")
if i == 3:
print("吃饱了不吃了")
break
print("没吃饱")
continue:退出本次循环,下次循环继续执行。
例:
for i in range(1,5):
print(f"小明吃第{i}个苹果")
if i == 3:
print(f"吃到了一只大虫子,第{i}个苹果不吃了")
continue
print("没吃饱")

列表 (list)
列表是处理一组有序项目的数据结构,也是可迭代对象,可以for循环遍历取值
基本格式:
列表名 = [元素1,元素2,元素3,···]
元素之间的数据类型可以各不相同,列表也可以进行切片操作。
常见操作
1.添加元素: append()、extend()、insert()
append()用于整体添加。
extend()用于分散添加。
insert()用于指定位置添加。
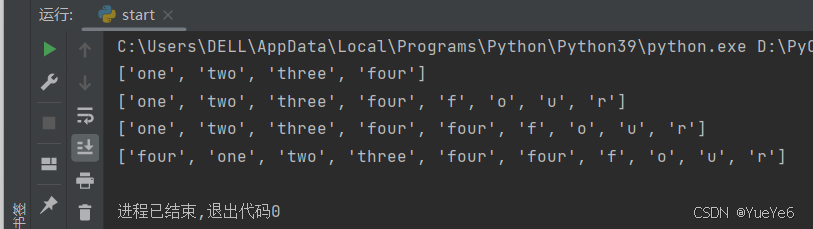
例:
a = ["one","two","three"]
a.append("four") #append整体添加
print(a)
a.extend("four") #extend分散添加,将另外一个类型中的元素逐一添加
print(a)
a.insert(3,"four") #在指定位置插入元素
print(a)
a.insert(0,"four") #指定位置如果有元素,原有元素将会后移
print(a)
2.修改元素
直接通过下标就可以进行修改。
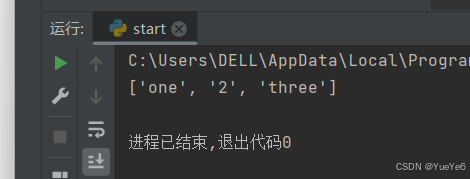
例:
a = ["one","two","three"]
a[1]="2"
print(a)
3.查找元素:in、not in、 index、count
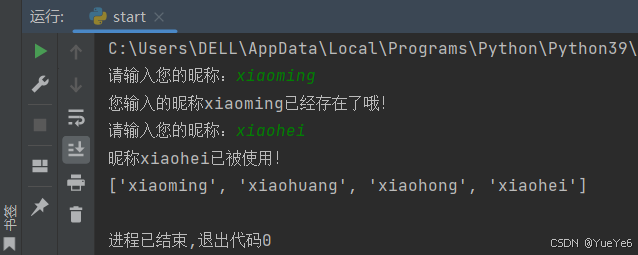
例:
name_list = ["xiaoming","xiaohuang","xiaohong"]
while True:
name = input("请输入您的昵称:")
if name not in name_list:
print(f"昵称{name}已被使用!")
name_list.append(name)
print(name_list)
break
else:
print(f"您输入的昵称{name}已经存在了哦!")
4.删除元素:del、pop()、remove()
li = ["a","b","c","d"]
del li #删除列表
del li[2] #根据下标删除
print(li)
li = ["a","b","c","d"]
li.pop() #默认删除最后一个元素
li.pop(2) #不能指定元素删除,只能根据下标进行删除,下标不能超出范围
print(li)
li = ["a","b","c","b","d"]
li.remove("b") #默认删除最开始出现的元素
print(li)
5.排序:sort()、reverse()
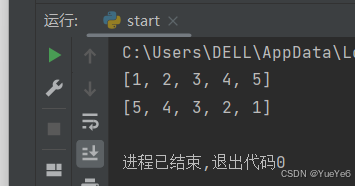
例:
li = [1,4,3,5,2]
li.sort() #按照从小到大的顺序排序
print(li)
li.reverse() #倒置
print(li)
6.列表推导式
格式一:[表达式 for 变量 in 列表]
格式二:[表达式 for 变量 in 列表 if 条件]
列表还可以替换为range(),可迭代对象。
例:
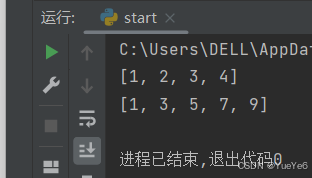
a = []
[a.append(i) for i in range(1,5)]
print(a)
b = []
[b.append(i) for i in range(1,11) if i%2 == 1]
print(b)
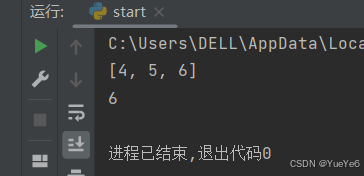
7.列表嵌套
一个列表里面又有一个列表。
例:
a = [1,2,3,[4,5,6]]
print(a[3]) #取出里面的列表
print(a[3][2]) #取出内列表中的元素
元组(tuple)
格式:元组名 = (元素1,元素2,元素3,···)
所有元素包含在小括号内,元素与元素之间用“,”隔开,不同元素也可以是不同的数据类型。
也可以进行切片操作。
a = () #定义空元祖
a = ("a",) #只有一个元素的时候,末尾必须加上','否则返回唯一的值的数据类型
元组与列表的区别:
1.元组只有一个元素末尾必须加上‘,’,列表不需要。
2.元组只支持查询操作,不支持增删改操作。
应用场景:
1.函数的参数和返回值。
2.格式化输出后面的()本质上就是一个元组。
3.数据不可以被修改,保护数据的安全。
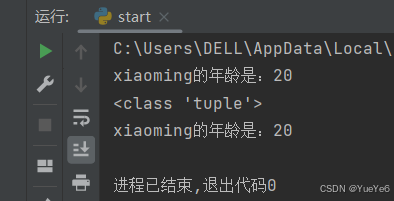
例:
name = 'xiaoming'
age = 20
print("%s的年龄是:%d" % (name,age))
all = (name,age)
print(type(all))
print("%s的年龄是:%d" % all)
字典(dict)
基本格式: 字典名 = {键1:值1,键2:值2,···}
键值对形式保存,键和值之间用:隔开,每个键值对之间用,隔开,字典中的键具有唯一性,但是值可以重复。
元素操作:
1.查看元素:
(1)变量名[键名]
(2)变量名.get[键名]
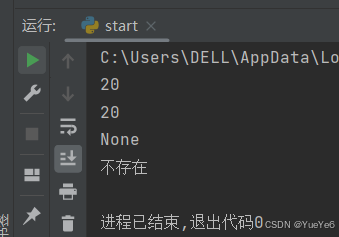
例:
xiaoming = {"score": "100","age":"20"}
# print(xiaoming[2]) #不可以根据下标,字典中没有下标,查找元素需要根据键名
print(xiaoming["age"])
print(xiaoming.get("age"))
print(xiaoming.get("like")) #键名不存在,返回None
print(xiaoming.get("like","不存在")) #如果没有这个键名,返回自己设置的默认值
2.修改元素:
变量名 [键名] = 值
列表通过下标修改,字典通过键名修改。
3.添加元素:
变量名 [键名] = 值
键名存在就修改,不存在就新增。
例:
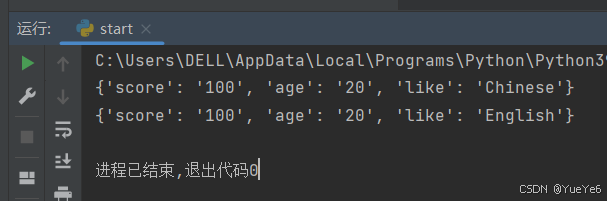
xiaoming = {"score": "100","age":"20"}
xiaoming["like"] = "Chinese"
print(xiaoming)
xiaoming["like"] = "English"
print(xiaoming)
4.删除元素:
(1)del
删除整个字典:del 字典名
删除指定键值对:del 字典名[键名]
(2)clear()
清空整个字典里面的东西,但保留了这个字典。
例:
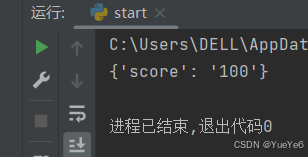
xiaoming = {"score": "100","age":"20"}
xiaoming.clear()
print(xiaoming)

(3)pop()
删除指定键值对,键不存在就会报错。
例:
xiaoming = {"score": "100","age":"20"}
xiaoming.pop("age")
# xiaoming.pop("like") #报错,不存在键名
# xiaoming.pop() #报错,没有指定键名
# xiaoming.popitem() #默认删除最后一个键值对
print(xiaoming)
字典操作
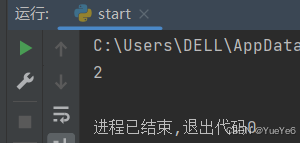
1.len()求长度
xiaoming = {"score": "100","age":"20"}
print(len(xiaoming))
2.keys():返回字典里面包含的所有键值
例:
xiaoming = {"score": "100","age":"20"}
print(xiaoming.keys())
for i in xiaoming: #只取出键名
print(i)

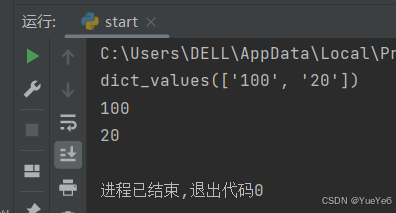
3.values() 返回字典里面包含的所有值
例:
xiaoming = {"score": "100","age":"20"}
print(xiaoming.values())
for i in xiaoming.values(): #只取出键值
print(i)
4.item() 返回字典里面包含的所有键值对,键值以元组形式
例:
xiaoming = {"score": "100","age":"20"}
print(xiaoming.items())
for i in xiaoming.items():
print(i,type(i)) #i是元组类型

应用场景
使用键值对存储描述一个物体的相关信息。
集合(set)
基本格式:集合名 = {元素1,元素2,元素3,···}
s1 = {} #定义空字典
s1 = set() #定义空集合
无序性:
集合无序的实现方式涉及hash表,不能修改集合中的值。
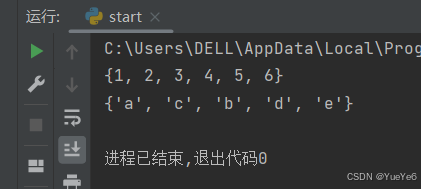
例:
s1 = {1,2,3,4,5,6} #数字运行结果一样
print(s1)
s2 = {"a","b","c","d","e"} #每次运行结果都不一样
print(s2)
唯一性:可以自动去重
常见操作:
1.添加元素:
(1)add():添加的是一个整体
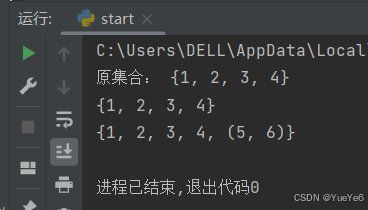
例:
s1 = {1,2,3,4}
print("原集合:",s1)
s1.add(1) #集合的唯一性,决定了如果需要添加的元素在原集合中已经存在,就不进行任何操作
print(s1)
s1.add((5,6)) #一次只能添加一次
print(s1)
(2)update():把传入的元素拆分,一个个放进集合中。
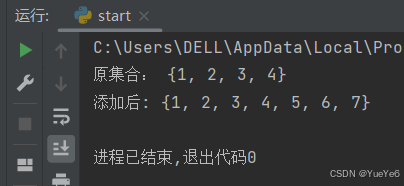
例:
s1 = {1,2,3,4}
print("原集合:",s1)
s1.update((5,6,7))
print("添加后:",s1)
2.删除元素:remove()、pop()、discard()
(1)remove(): 选择删除的元素,如果集合中有就删除,没有就会报错。
(2)pop(): 默认删除根据hash表排序后的第一个元素。
(3)discard():选择要删除的元素,有就会删除,没有则不会进行任何操作。
例:
s1 = {1,2,3,4}
print("原集合:",s1)
s1.remove(2)
print(s1)
s1.pop()
print(s1)
s1.discard(3)
print(s1)

拆包
含义:对于函数中的多个返回数据,去掉元组,列表,或者字典,直接获得里面数据的过程。
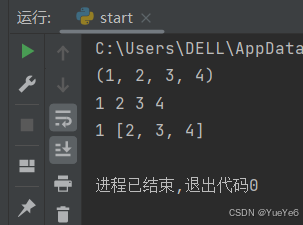
例:
tua = (1,2,3,4)
print(tua)
#方法一
a,b,c,d = tua
print(a,b,c,d)
#一般在获取元组值的时候使用
#方法二
a,*b = tua
print(a,b)
#先把单独的取完,其他剩下的全部都交给带*的变量
#一般在函数调用时使用
交集与并集
1.交集:共有的部分
2.并集:总和
例:
s1 = {1,2,3,4}
s2 = {3,4,5,6}
print(s1 & s2)
print(s1 | s2)
类型转换
1.int():转换为一个整数
只能转换由纯数字组成的字符串,浮点型强转整型会去掉小数点及后面的数据,只保留整数部分。
2.float():转换为一个小数
整型转换为浮点型会自动添加一位小数。
3.str():转换为字符串类型
任何类型都可以转换成字符串类型。
float转换成str会取出末尾为0的小数部分。
4.eval():用来执行一个字符串表达式,并返回表达式的值
可以实现list、dict、tuple和str之间的转换
eval():非常强大,但是不够安全,容易被恶意修改数据,不建议使用。
5.list():将可迭代对象转换为列表
符合的可迭代对象有:str、tuple、dict、set。
字典转换成列表会取键名作为列表的值。
集合转换成列表,会先去重,再转换。
6.tuple():转换为一个元组
7.chr():将一个整数转换为一个字符串
深浅拷贝
1.赋值
会随着原对象一起变,等于完全共享资源,一个值的改变会完全被另一个值共享。
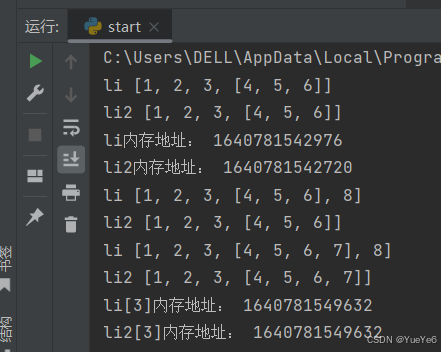
2.浅拷贝(数据半共享)
会创建新的对象,拷贝第一层的数据,嵌套层会指向原来的内存地址
外层的内存地址不同,但是内层的内存地址相同。
优点:拷贝速度快,占用空间小,拷贝效率高。
例:
import copy
li = [1,2,3,[4,5,6]]
li2 = copy.copy(li)
print("li",li)
print("li2",li2)
print("li内存地址:",id(li)) # 查看内存地址 id()
print("li2内存地址:",id(li2)) #内存地址不一样,说明不是同一个对象
li.append(8)
print("li",li)
print("li2",li2)
li[3].append(7)
print("li",li)
print("li2",li2)
print("li[3]内存地址:",id(li[3]))
print("li2[3]内存地址:",id(li2[3]))
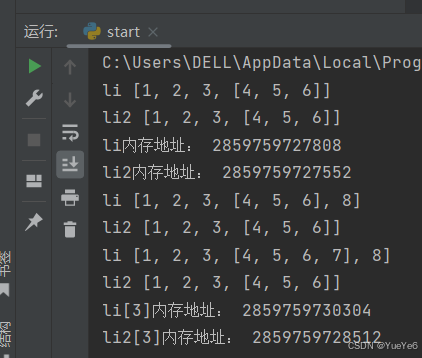
3.深拷贝(数据完全不共享)
深拷贝数据变化只影响自己本身,跟原来的对象没有联系。
例:
import copy
li = [1,2,3,[4,5,6]]
li2 = copy.deepcopy(li) #深拷贝
print("li",li)
print("li2",li2)
print("li内存地址:",id(li))
print("li2内存地址:",id(li2)) #内存地址不一样,说明不是同一个对象
li.append(8)
print("li",li)
print("li2",li2)
li[3].append(7)
print("li",li)
print("li2",li2)
print("li[3]内存地址:",id(li[3]))
print("li2[3]内存地址:",id(li2[3]))
可变对象与不可变对象
可变对象:变量对应的值可以修改,但是内存地址不会发生改变。
常见的可变类型:list、dict、set。
不可变对象:变量对应的值不能被修改,如果修改就会生成一个新的值从而分配新的内存空间。
常见的不可变类型:整型、字符串、元组tuple
注:前面所说的深浅拷贝只针对可变对象,不可变对象没有拷贝的说法。
函数
含义:将独立的代码块组织成一个整体,使其具有特殊功能的代码集,在需要的时候再去调用即可。
作用:提高代码的重用性,使整体代码看起来更加简练。
一、基本格式:
def 函数名(): #定义函数
函数体
函数名() #调用函数
调用几次,函数里面的代码就会运行几次,每次调用,函数都会从头开始执行。
例:
def say_hello():
print("帅哥,你好!")
say_hello() #调用函数前,必须保证函数已存在
say_hello()
二、返回值 return:
含义:函数执行结束后,最后给调用者的一个结果。
作用:
(1)return会给函数的执行者返回值。
(2)函数中遇到return,表示此函数结束,不继续执行。
return返回多个值,以元组的形式返回给调用者,没有则返回None
return与print的区别:
(1)return表示此函数结束,print会一直进行 。
(2)return是返回计算值,print是打印结果。
三、参数
定义:
def 函数名(形参a,形参b) #形参:定义函数时,小括号里面的变量
函数体
调用格式:
函数名(实参1,实参2) #实参:调用函数时,小括号里面的具体值
1.必备参数(位置参数)
含义:传递和定义参数的顺序及个数必须一致。
格式:def 函数名(a,b)
例:
def score(a,b):
return a+b
print(score(46,49))

2.默认参数
含义:为参数提供默认值,调用函数时可不传该默认参数。
注意:所有的位置参数必须出现在默认参数前,包括函数的定义和调用
设置默认值,没有传值会根据默认值来运行代码,传了值根据传入的值来执行代码
例:
def score(a=50,b=50):
return a+b
print(score())
print(score(46,49))
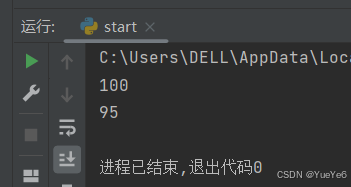
3.可变参数
含义:传入的值的数量是可以改变的,可以传入多个,也可以不传。
格式:def func(*args)
以元组的形式接受
例:
def func(*args):
print(args)
print(type(args))
func("海绵宝宝","派大星星","章鱼哥哥")
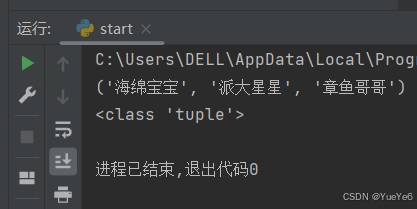
4.关键字参数
格式:def func(**kwargs)
作用:可以扩展函数的功能
例:
def func(**kwargs): #以字典形式接收
print(kwargs)
print(type(kwargs))
func(name="海绵宝宝",age=18) #传值的时候,需要采用键=值的形式
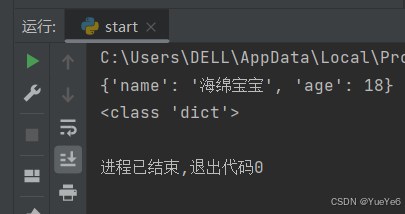
四、函数嵌套
(1)嵌套调用:
含义:在一个函数里面调用另外一个函数。
例:
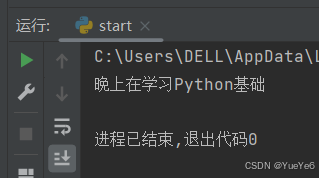
def study():
print("晚上在学习",end="")
def course():
study()
print("Python基础")
course()
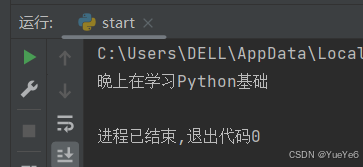
(2)嵌套定义
含义:在一个函数中定义另外一个函数。
例:
def study(): #外函数
print("晚上在学习",end="")
def course(): #内函数
print("Python基础")
course() #注意缩进,定义和调用是同级的,调用如果在定义里面则永远调用不到。
study()
五、匿名函数
基本语法:函数名 = lambda 形参 : 返回值(表达式)
调用: 结果 = 函数名(实参)
例:
def add(a,b): #普通函数
return a+b
print(add(1,3))
#匿名函数
add = lambda a,b:a+b #a,b就是匿名函数的形参,a+b是返回值的表达式
print(add(1,5)) #lambda不需要写return来返回值,表达式本身结果就是返回
1.lambda的参数形式
(1)无参数
(2)一个参数
(3)默认参数
(4)关键字参数
默认参数必须写在非默认参数后面
例:
funa = lambda : "你好" #无参数
print(funa())
funb = lambda name:name #一个参数
print(funb("小明"))
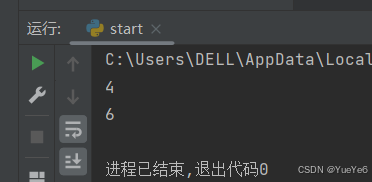
func = lambda name,age=18:(name,age) #默认参数
print(func("小明",20))
fund = lambda **kwargs:kwargs #关键字参数
print(fund(name = "小明",age = 18))
2.lambda结合if判断
特点:lambda只能实现简单的逻辑,如果逻辑复杂切代码量较大,不建议使用lambda。
例:
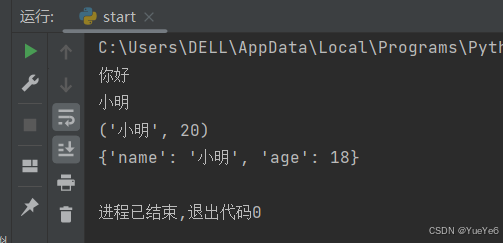
comp = lambda a,b:"a比b小" if a<b else "a大于等于b"
print(comp(8,5))

六、内置函数
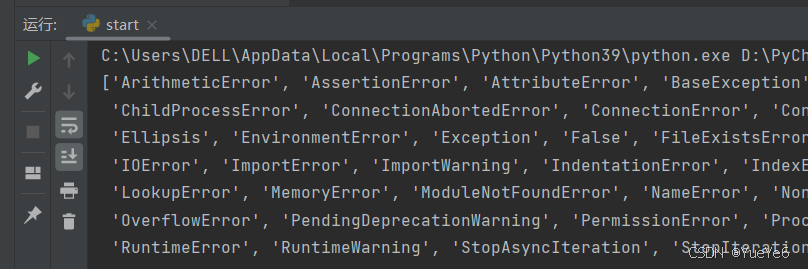
1.查看所有的内置函数
大写字母一般是内置常量名,小写字母开头一般是内置函数名。
import builtins
print(dir(builtins))
2.abs():返回绝对值
3.sum():求和
sum()函数内要放可迭代对象,运算时,只要有一个浮点数,那么结果必定是浮点数。
4.min():求最小值
例:
print(min(-8,5,key=abs))
#先求绝对值,再取较小值
5.max():求最大值
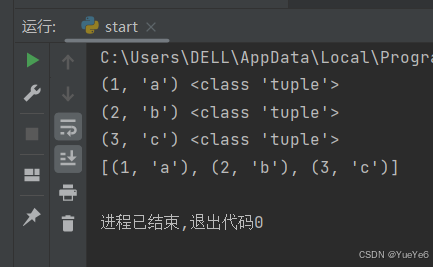
6.zip():将可迭代对象作为参数,将对象中对应的元素打包成一个元组
例:
li = [1,2,3]
li2 = ["a","b","c"]
#第一种方式:通过for循环
for i in zip(li,li2):
print(i,type(i)) #如果元素个数不一致,就按长度最短的
#第二种方式:转换成列表打印
print(list(zip(li,li2)))
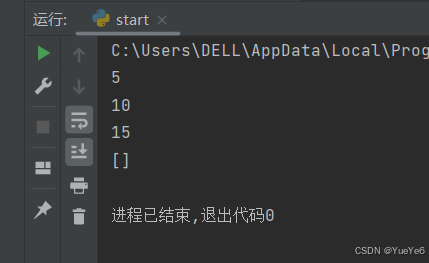
7.map():可以将可迭代对象中的每一个元素进行映射,分别去执行
map(func,iter1)
func指的是自己定义的函数,iter1指的是要放进去的可迭代对象。
简单来说就是对象中的每一个元素都会去执行这个函数。
例:
li = [1,2,3]
def funa(x):
return x*5
mp = map(funa,li)
#第一种方式:通过for循环
for i in mp:
print(i)
#第二种方式:转换成列表打印
print(list(mp))
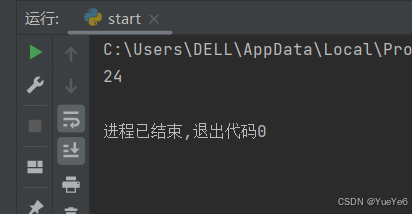
8.reduce()
先把对象中的两个元素取出,计算出一个值,然后保存着,接下来把这个计算值跟第三个元素进行计算。
reduce(function,sequence)
function指的是必须有两个参数的函数,sequence指的是序列,即可迭代对象。
例:
from functools import reduce
li2 = [1,2,3,4]
def add(x,y):
return x*y
res = reduce(add,li2)
print(res)
9.input():输入函数
input(prompt):prompt是提示,会在控制台中显示。
input():默认输入字符串。
七、递归函数
含义:如果一个函数在内部不调用其他函数,而是调用它本身的话,这个函数就是递归函数。
一、条件:
1.必须有一个明确的结束条件——递归出口
2.每进行更深一层的递归,问题模块相比上次递归都要有所减少
3.相邻两次重复之间有密切点联系
二、优点:
简洁、逻辑清晰、解题更具有思路。
三、缺点;
使用递归函数的时候,需要反复调用函数,耗内存。运行效率低。
例:
# 斐波那契数列;1,1,2,3,5,8,13···
def funa(n):
if n<=1:
return n
return funa(n-1)+funa(n-2)
print(funa(10))

八、函数引用:通过引用调用函数
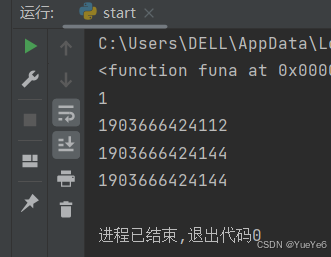
例:
def funa():
print(123)
print(funa) #函数名里面保存了函数所在位置的引用
a = 1 #a只不过是一个变量名,存的是1这个数值所在的地址
print(a)
print(id(a))
a = 2 #修改a,生成了新的值,重新赋值给变量a
print(id(a))
print(id(2)) #内存地址发生变化,因此值也发生变化
例:
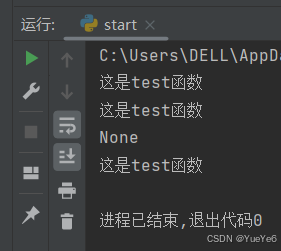
def test1(): #test1也只不过是一个函数名,里面存了这个函数所在位置的引用
print("这是test函数")
test1()
print(test1()) #内存地址(引用)
te = test1
te() #通过引用调用函数
作用域
含义:指的是变量生效的范围,分为两种,分别是全局变量和局部变量。
一、全局变量
函数外部定义的变量,在整个文件中都是有效的。
二、局部变量
函数内部定义的变量,在定义位置开始,到函数定义结束位置有效。
作用:在函数体内部,临时保存数据,即将函数调用完成之后,就销毁局部变量。
局部变量正能在被定义的函数中使用,函数外部不能使用。
三、global:将变量声明为全局变量
语法格式:global 变量名
例:
def study():
global name #将局部变量name声明为全局变量
name = "Python基础" #局部变量
print(f"我在学习{name}")
study()
四、nonlocal:用来声明外层的局部变量
只能在嵌套函数中使用,在外部函数先进行声明,内部函数进行nonlocal声明。
nonlocal只能对上一级进行修改
异常
含义:是一个事件,这个时间在程序执行过程中发生影响了程序的正常进行。
一、异常处理
1.格式一:
try: except:
例:
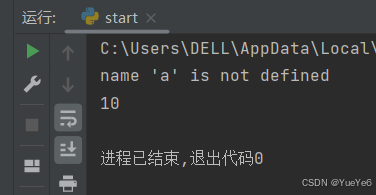
try:
print(a)
except Exception as e: #万能异常Exception 可以捕获任意异常
print(e)
b = 10
print(b)
2.格式二:
try: except: else:
else只有在没有异常时才会执行的代码,except和else不能同时进行。
例:
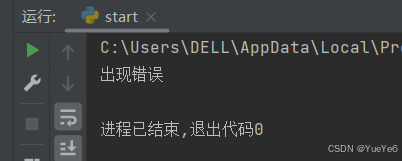
dic = {"name","zs"}
try:
print(dic["age"])
except Exception:
print("出现错误")
else:
print("没有捕获到异常")
3.格式三:
try: except: finally:
finally无论是否有异常,都会执行的代码。
例:
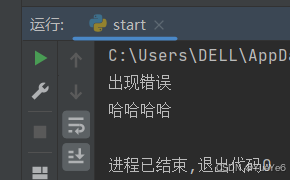
dic = {"name","zs"}
try:
print(dic["age"])
except Exception:
print("出现错误")
finally:
print("哈哈哈哈")
4.格式四:
try: except: else: finally
二、抛出异常
步骤:
1.创建一个Exception(“xxx”)对象,xxx—异常提示信息
2.raise抛出这个对象(异常对象)
捕获异常是为了检测到异常时代码还能继续往下运行,即程序不会终止。
例:
def login():
password = (input("请输入您的密码:"))
if len(password) >= 6:
return "密码输入成功"
raise Exception("长度不足六位,密码输入失败")
try:
print(login())
except Exception as e:
print(e)

模块:
一、含义:
在Python中一个py文件就是一个模块,里面定义了一些函数和变量,需要的时候可以导入和使用这些模块。
二、分类:
1.内置模块:直接导入即可使用
2.第三方模块(第三方库):
下载: cmd窗口输入:pip install 模块名
3.自定义模块:
注意:命名要遵循标志符规定以及变量的命名规范,并且不要与内置模块起冲突,否则将导致模块功能无法使用。
三、导入模块:
1.方式一:import 模块名
导入方式:import 模块名
调用方式:模块名.功能名
2.方式二:from…import…
从模块中导入指定部分:from 模块名 import 功能1,功能2…
调用功能:直接输入功能即可,不需要添加模块名。
3.方式三: from…import *
语法:from 模块名 import *
把模块中的所有内容全部导入
四、as起别名
1.as给模块起别名
语法:import 模块名 as 别名
2.as给功能起别名
语法:from 模块名 import 功能名 as 别名
注:导入多个功能使用“,”将功能与功能隔开,后面的功能也可以取别名。
例:
import pytest as pt #给模块起别名
pt.funa() #调用模块中的funa()
print(pt.name) #打印模块中的name变量
五、内置全局变量:name
name:导入时不会被显示
语法:if name== “main”:
作用:用来控制py文件在不同的应用场景执行不同的逻辑
被当作模块导入时,name == "main"下面的代码不会被显示出来
包
含义:就是项目结构中的文件夹或目录
与普通文件夹的区别:包是含有__init__.py文件的代码
作用:将有联系的模块放在同一文件夹,有效避免模块名称冲突问题,让结构更清晰。
一、注意:
1.import导入包时,首先执行__init__.py文件的代码。
2.不建议在init文件中编写过多的代码,尽量保证init文件的内容简单。init文件的作用是:导入这个包内的其他模块。
3.all:本质上是一个列表,列表里面的元素就代表要导入的模块。
作用是:可以控制要引入的东西
格式:all = [" “,” "···] 相当于导入[]里面定义的模块
4.包的本质依然是模块,包又可以包含包。
二、闭包函数:
条件:
1.函数嵌套
2.内层函数使用外层函数的局部变量
3.外层函数的返回值是内层函数的函数名
例:
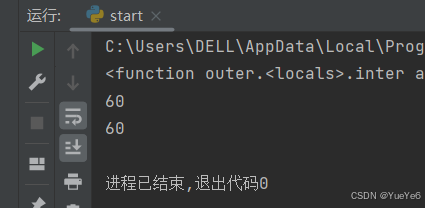
def outer(m): #外层函数
n = 10 #外层函数的局部变量
def inter(a): #内层函数
print(m+n+a) #内层函数使用外层函数的局部变量
return inter #外层函数的返回值是内层函数的函数名
print(outer(20)) #返回的是内部函数的内存地址
#第一种调用写法:
outer(20)(30)
#第二种调用写法:
ot = outer(20) #调用外函数
ot(30) #调用内函数
三、闭包
每次开启内函数都在使用同一份闭包变量
总结:
使用闭包过程中,一旦外函数被调用一次,返回了内函数的引用,虽然每次调用内函数,会开启一个函数,执行后消亡,但是闭包变量实际上只有一份,每次开启内函数都在使用同一份闭包变量。
装饰器
作用:在不改变原有代码的情况下添加新的功能。
条件:
1.不修改源程序或函数的代码
2.不改变函数或程序的调用方式
含义:
装饰器本质上就是一个闭包函数,它的好处就是在不修改原有代码的基础上,增加额外的功能。
一、标准版装饰器
原理:将原有的函数名重新定义为以原函数为参数的闭包。
例:
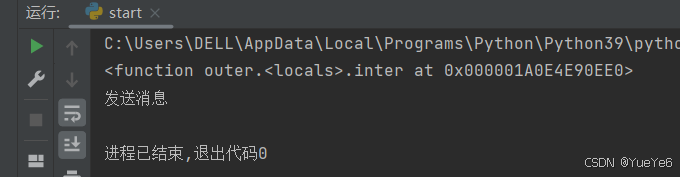
def send(): #被装饰的函数
print("发送消息")
def outer(fn): #外层函数,fn是形参,但是往里面传的是被装饰的函数名
def inter(): #内层函数
fn() #执行被装饰的函数
return inter
print(outer(send))
ot = outer(send)
ot()
二、语法糖:
**格式:@装饰器名称 **
例:
def outer(fn):
def inter():
print("登录···")
fn() #执行被装饰的函数
return inter
@outer #注意装饰器名称后面不要加上(),前者是引用,后者是调用函数,返回该函数要返回的值
def send():
print("发送消息:笑死我了")
send()
@outer
def send1():
print("发送消息:呵呵呵")
send1()

三、被装饰的函数有参数
例:
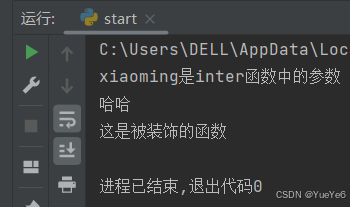
def outer(fn):
def inter(name):
print(f"{name}是inter函数中的参数")
print("哈哈")
fn(name)
return inter
@outer
def func(name):
print("这是被装饰的函数")
func("xiaoming")
四、被装饰的函数有可变参数*args、**kwargs
例:
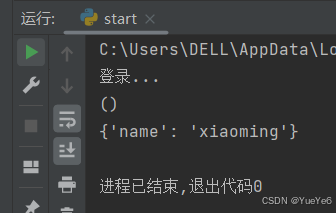
def outer(fn): #被装饰的函数
def inter(*args,**kwargs):
print("登录...")
fn(*args,**kwargs)
return inter
def func(*args,**kwargs): #被装饰函数
print(args)
print(kwargs)
ot = outer(func)
ot(name = "xiaoming")
五、多个装饰器:
多个装饰器的装饰过程,里函数最近的装饰器先装饰,然后外面的装饰器再进行装饰,有内到外的装饰过程。
例:
def deco1(fn):
def inter():
return "哈哈哈"+fn()+"呵呵呵"
return inter
def deco2(fn):
def inter():
return "奈斯"+fn()+"非常优秀"
return inter
@deco2
@deco1
def test1():
return "晚上在学习Python基础"
print(test1())


















 51万+
51万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









