




1、Hudi介绍
1.1、介绍
Overview | Apache Hudi!Welcome to Apache Hudi! This overview will provide a high level summary of what Apache Hudi is and will orient you on https://hudi.apache.org/docs/overview
https://hudi.apache.org/docs/overview
Apache Hudi(Hadoop Upserts Delete and Incremental)是下一代流数据湖平台。Apache Hudi将核心仓库和数据库功能直接引入数据湖。Hudi提供了表、事务、高效的upserts/delete、高级索引、流摄取服务、数据集群/压缩优化和并发,同时保持数据的开源文件格式。
Apache Hudi不仅非常适合于流工作负载,而且还允许创建高效的增量批处理管道。
Apache Hudi可以轻松地在任何云存储平台上使用。Hudi的高级性能优化,使分析工作负载更快的任何流行的查询引擎,包括Apache Spark、Flink、Presto、Trino、Hive等。
1.2、发展历史
2015 年:发表了增量处理的核心思想/原则(O'reilly 文章)。
2016 年:由 Uber 创建并为所有数据库/关键业务提供支持。
2017 年:由 Uber 开源,并支撑 100PB 数据湖。
2018 年:吸引大量使用者,并因云计算普及。
2019 年:成为 ASF 孵化项目,并增加更多平台组件。
2020 年:毕业成为 Apache 顶级项目,社区、下载量、采用率增长超过 10 倍。
2021 年:支持 Uber 500PB 数据湖,SQL DML、Flink 集成、索引、元服务器、缓存。
1.3、特性
- 可插拔索引机制支持快速Upsert/Delete。
- 支持增量拉取表变更以进行处理。
- 支持事务提交及回滚,并发控制。
- 支持Spark、Presto、Trino、Hive、Flink等引擎的SQL读写。
- 自动管理小文件,数据聚簇,压缩,清理。
- 流式摄入,内置CDC源和工具。
- 内置可扩展存储访问的元数据跟踪。
- 向后兼容的方式实现表结构变更的支持。
1.4、使用场景
- 近实时写入
- 减少碎片化工具的使用。
- CDC 增量导入 RDBMS 数据。
- 限制小文件的大小和数量。
- 近实时分析
- 相对于秒级存储(Druid, OpenTSDB),节省资源。
- 提供分钟级别时效性,支撑更高效的查询。
- Hudi作为lib,非常轻量。
- 增量 pipeline
- 区分arrivetime和event time处理延迟数据。
- 更短的调度interval减少端到端延迟(小时 -> 分钟) => Incremental Processing。
- 增量导出
- 替代部分Kafka的场景,数据导出到在线服务存储 e.g. ES。
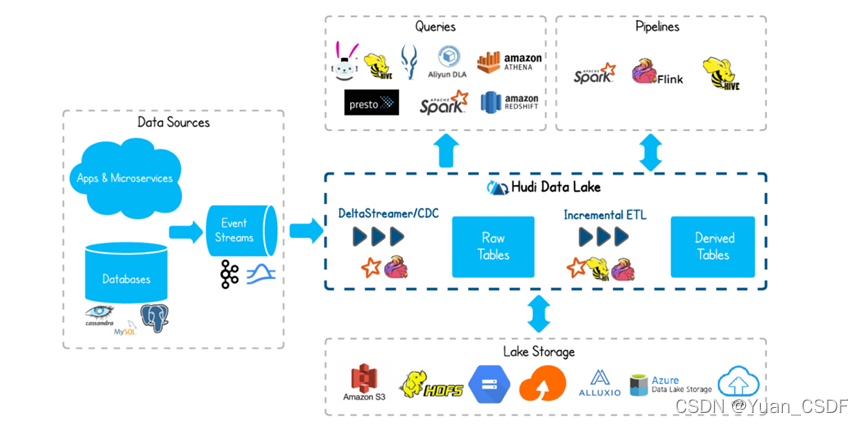
2、概要
2.1、时间轴(Timeline)
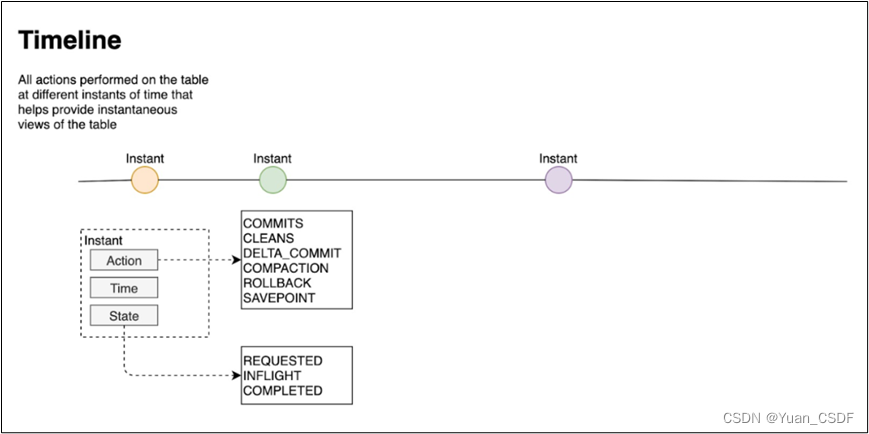
hudi的核心是维护在不同时刻在表上执行的所有操作的时间表,提供表的即时视图,同时还有效地支持按时间顺序检索数据。Hudi的时刻由以下组件组成:
- Instant action: 在表上执行的操作类型
- commits: 表示将一批数据原子写入表中
- cleans: 清除表中不在需要的旧版本文件的后台活动。
- delta_commit:增量提交是指将一批数据原子性写入MergeOnRead类型的表中,其中部分或者所有数据可以写入增量日志中。
- compaction: 合并Hudi内部差异数据结构的后台活动,例如:将更新操作从基于行的log日志文件合并到列式存储的数据文件。在内部,COMPACTION体现为timeline上的特殊提交。
- rollback:表示提交操作不成功且已经回滚,会删除在写入过程中产生的数据
- savepoint:将某些文件标记为“已保存”,以便清理程序时不会被清楚。在需要数据恢复的情况下,有助于将数据集还原到时间轴上某个点。
- Instant time:即时时间
- 通常是一个时间戳(例如:20230422210349),它按照动作开始时间的顺序单调增加。
- State: 时刻的当前状态
- requested:表示一个动作已被安排,但尚未启。
- inflight:表是当前正在执行操作。
- completed:表是在时间线上完成了操作。
-
两个时间概念
区分两个重要的时间概念:
-
Arrival time: 数据到达 Hudi 的时间,commit time。
-
Event time: record 中记录的时间。
-
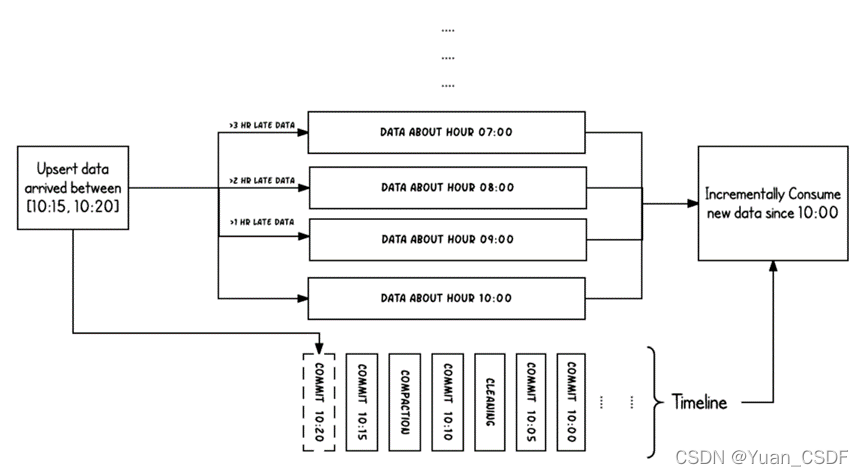
上图中采用时间(小时)作为分区字段,从 10:00 开始陆续产生各种 commits,10:20 来了一条 9:00 的数据,根据event time该数据仍然可以落到 9:00 对应的分区,通过 timeline 直接消费 10:00 (commit time)之后的增量更新(只消费有新 commits 的 group),那么这条延迟的数据仍然可以被消费到。
2.2、文件布局(File Layout)
Hudi将一个表映射为如下文件结构
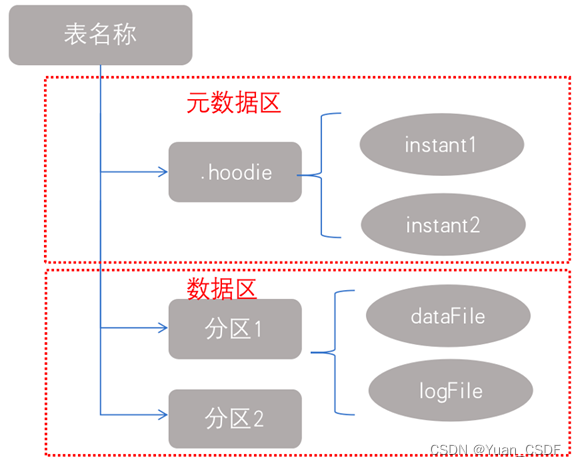
Hudi存储分为两个部分:
- 1、元数据:.hoodie目录对应着表的元数据信息,包括表的版本管理(Timeline)、归档目录(存放过时的instant也就是版本),一个instant记录了一次提交(commit)的行为、时间戳和状态,Hudi以时间轴的形式维护了在数据集上执行的所有操作的元数据;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1598
1598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









