






一、弹幕爬取
1. 获取剧集编码
这段代码的主要功能是爬取腾讯视频网页上的电视剧《繁花》列表,并提取每部电视剧的名称、集数、剧集编码 (data-vid) 和剧集类别编码 (data-cid)。
-
导入必要的库
requests:用于发起HTTP请求。lxml.etree:用于解析HTML文档,并提供XPath查询功能。
-
定义URL:电视剧列表的网页地
-
发起HTTP GET请求
- 使用
requests.get()方法发起请求,并将响应对象保存在response变量中。
- 使用
-
设置响应内容的编码
- 将响应的编码设置为
utf-8,以确保正确解析内容。
- 将响应的编码设置为
-
解析HTML内容
- 使用
etree.HTML()方法将响应的文本内容解析为一个HTML对象树。
- 使用
-
使用XPath查询定位元素
et: 使用XPath查询定位到电视剧列表的特定元素。这个XPath表达式是根据网页结构手动编写的,用于定位到包含电视剧信息的元素。
-
提取电视剧信息
- 使用for循环遍历查询到的每一个电视剧元素
- 在循环内部,使用XPath查询分别提取电视剧的名称、集数、剧集编码 (
data-vid) 和剧集类别编码 (data-cid)。
-
异常处理
- 使用
try-except结构来捕获可能出现的异常。如果在提取信息时发生任何异常(例如XPath查询返回空列表),则except块会被执行,但这里并没有进行任何特定的处理,只是简单地使用pass语句跳过。
- 使用
import requests
from lxml import etree
url = 'https://v.qq.com/x/cover/mzc00200whsp9r6/a0047l69jnp.html'
response = requests.get(url=url)
response.encoding = 'utf-8'
html_etree = etree.HTML(response.text)
et = html_etree.xpath('//*[@id="app"]/div[2]/div[2]/div/div[2]/div/div/div[2]/div[1]/div[2]/div[2]/div/div/div')
for item in et:
try:
name = item.xpath('./div/div[2]/text()')[0]
episodes = item.xpath('./div/div[1]/span/text()')[0]
video_code = item.xpath('./div/div[1]/@data-vid')[0]
video_cid = item.xpath('./div/div[1]/@data-cid')[0]
print(episodes,video_cid,video_code,name)
except:
pass2. 弹幕爬取
2.1 普通话版
这段代码的目的是从腾讯视频的弹幕API中获取多个视频的弹幕数据,并将这些数据保存到CSV文件中。以下是代码的详细解读:
-
导入必要的库
requests: 用于发起HTTP请求。pandas: 用于数据处理和保存为CSV文件。
-
初始化一个空的DataFrame
:episodes_danmu_DataFrame用于存储所有视频的弹幕数据 -
定义视频编号、请求次数和步进参数
code: 包含多个腾讯视频编号的列表。num: 每个视频获取弹幕的次数。step: 每次请求弹幕数据的步进参数。
-
双重循环
- 外层循环遍历视频编号列表,即遍历每个视频。
- 内层循环负责获取每个视频的弹幕数据。
-
构建请求URL
url是根据视频编号、请求次数和步进参数构建的。
-
发起HTTP GET请求
- 使用
requests.get()方法发起请求,并获取响应内容。 - 响应内容被解析为JSON格式。
- 使用
-
处理响应数据
- 如果响应中的
barrage_list长度大于0,说明获取到了弹幕数据。- 使用
pd.json_normalize()将弹幕数据转化为DataFrame格式。 - 将转化后的DataFrame与
episodes_danmu_DataFrame合并。 - 打印当前请求的状态和已获取的弹幕数量。
- 使用
- 如果
barrage_list为空,则跳出内层循环。
- 如果响应中的
-
保存数据到CSV文件
- 在外层循环的每次迭代结束时,将当前视频的弹幕数据保存到CSV文件中。
- 文件名包含视频编号和已获取的弹幕数量。
- 仅保存
time_offset、create_time和content这三个字段。 encoding="utf-8"指定文件的编码格式。errors='ignore'在写入文件时忽略编码错误。index=False表示在保存时不包含DataFrame的索引。
import requests
import pandas as pd
episodes_danmu_DataFrame = pd.DataFrame()
code = ["a0047l69jnp","g0047vju30g","w0047o2kopn","j004785qmr9","v0047cau7sj",
"h0047fake5u","o004779m63e","j00474mkhx6","t0047rz7dck","e0047gxi761",
"e0047epaspf","i0047ki4jfc","w0047tsttcp","s0047fm6glr","u0047daapp7",
"c004725utxa","y004730ezg7","v0047xsyni7","i0047rygj57","j0047femzt9",
"x0047thj870","l004791c4ca","z0047l46lz4","q0047ugihqv","r00473liw97",
"t0047mh70jw","v0047u4dyt6","b0047n3hzrh","b0047fgdeuq","j0047aj1c1n"]
num = 10000
step = 30000
for j in range(30):
video_code=code[j]
for i in range(num):
url = f'https://dm.video.qq.com/barrage/segment/{video_code}/t/v1/{i*30000}/{i * 30000 + step}'
response = requests.get(url=url).json()
if (len(response["barrage_list"])) > 0:
temp_danmu_DataFrame = pd.json_normalize(response['barrage_list'], errors='ignore')
episodes_danmu_DataFrame = pd.concat([episodes_danmu_DataFrame, temp_danmu_DataFrame])
print("第",i+1,"次请求弹幕,请求地址为:",url, "获取到:",temp_danmu_DataFrame.shape[0],
"条弹幕,这一集总弹幕已获取到",episodes_danmu_DataFrame.shape[0],"条。")
else:
break
print("总共获取到", episodes_danmu_DataFrame.shape[0],"条弹幕")
rows = episodes_danmu_DataFrame.shape
print("请求得到的表格行数与列数:",rows)
episodes_danmu_DataFrame=episodes_danmu_DataFrame.loc[:, ['time_offset', 'create_time', 'content']]
episodes_danmu_DataFrame.to_csv(f"繁花第{j+1}集{episodes_danmu_DataFrame.shape[0]}条弹幕.csv", mode='w',
encoding="utf-8", errors='ignore', index=False)
print("弹幕保存完成!")2.2 沪语版
import requests
import pandas as pd
episodes_danmu_DataFrame = pd.DataFrame()
# video_code是腾讯视频的编号,num是获取弹幕的次数,step是步进参数
code = ["r0047sjjwbr","x004753w2fl","d004733alk2","t0047jcvifm","n00477upxr3",
"n0047y1acrc","g0047cy4d1e","d0047hlhubk","v00478364l1","h0047of07l9",
"q0047gl2she","e0047jq251d","x0047c2sgdz","q0047ctkx8a","p0047wldlo3",
"c0047uus3fb","c00473h5wf8","z0047f79bok","a00477w866c","n00479a9fyb",
"e004758nkjl","o0047obgazl","j0047g1or8g","y0047uwkroa","e00478jxgsm",
"d0047qoayc5","h0047ojtsdq","b00473f1sof","y0047qwkl9n","u0047wreyf8"]
num = 10000
step = 30000
for j in range(30):
video_code=code[j]
for i in range(num):
url = f'https://dm.video.qq.com/barrage/segment/{video_code}/t/v1/{i * 30000}/{i * 30000 + step}'
response = requests.get(url=url).json()
if (len(response["barrage_list"])) > 0:
temp_danmu_DataFrame = pd.json_normalize(response['barrage_list'], errors='ignore')
episodes_danmu_DataFrame = pd.concat([episodes_danmu_DataFrame, temp_danmu_DataFrame])
print("第", i + 1, "次请求弹幕,请求地址为:", url, "获取到:", temp_danmu_DataFrame.shape[0],
"条弹幕,这一集总弹幕已获取到", episodes_danmu_DataFrame.shape[0], "条。")
else:
break
print("总共获取到", episodes_danmu_DataFrame.shape[0], "条弹幕")
rows = episodes_danmu_DataFrame.shape
print("请求得到的表格行数与列数:", rows)
episodes_danmu_DataFrame = episodes_danmu_DataFrame.loc[:, ['time_offset', 'create_time', 'content']]
episodes_danmu_DataFrame.to_csv(f"繁花第{j+1}集{episodes_danmu_DataFrame.shape[0]}条弹幕.csv", mode='w',
encoding="utf-8", errors='ignore', index=False)
print("弹幕保存完成!")二、文本统计
1. 预处理
这段代码的主要功能是读取电视剧《繁花》的多个集数的弹幕数据,并对这些数据进行一系列的处理,然后将处理后的数据保存为新的CSV文件。以下是对代码的详细解读:
-
导入所需的库
pandas as pd:用于数据处理。datetime:用于处理日期和时间。SnowNLP:一个用于中文自然语言处理的库,这里主要用来获取弹幕的情感分析。
-
定义弹幕CSV文件的路径
- 代码定义了从第1集到第30集的弹幕CSV文件的路径,并存储在变量
d1到d30中。 - 创建一个名为
list的列表,包含所有定义的弹幕CSV文件路径。
- 代码定义了从第1集到第30集的弹幕CSV文件的路径,并存储在变量
-
遍历指定的集数并处理数据
- 使用
for循环遍历从第1集到第30集(包括)的弹幕数据。pd.read_csv(list[i]):读取当前集数的弹幕数据到dataDataFrame中。data['content'] = data['content'].astype(str):确保content列的数据类型为字符串。data['time']=data['create_time'].map(datetime.fromtimestamp):将create_time列的时间戳转换为datetime对象,并存储在time列中。data['hour'],data['day'],data['month'],data['year']:从time列中提取小时、天、月和年,并分别存储在相应的列中。data['content_length']=data['content'].map(lambda x: len(str(x))):计算content列中每条弹幕的长度,并存储在content_length列中。data['sentiments']=data['content'].map(lambda x:SnowNLP(x).sentiments):使用SnowNLP库对每条弹幕进行情感分析,并将结果存储在sentiments列中。data.to_csv(f'繁花第{i+1}集_普通话版.csv',index=False):将处理后的数据保存为一个新的CSV文件,文件名中包含集数信息。
- 使用
2. 弹幕长度
length_series=data['content_length'].value_counts():统计content_length列中各个弹幕长度的出现次数。length_series.sort_index(ascending=True, inplace=True):对length_series按索引(即弹幕长度)进行升序排序。print(length_series):打印排序后的弹幕长度统计结果。
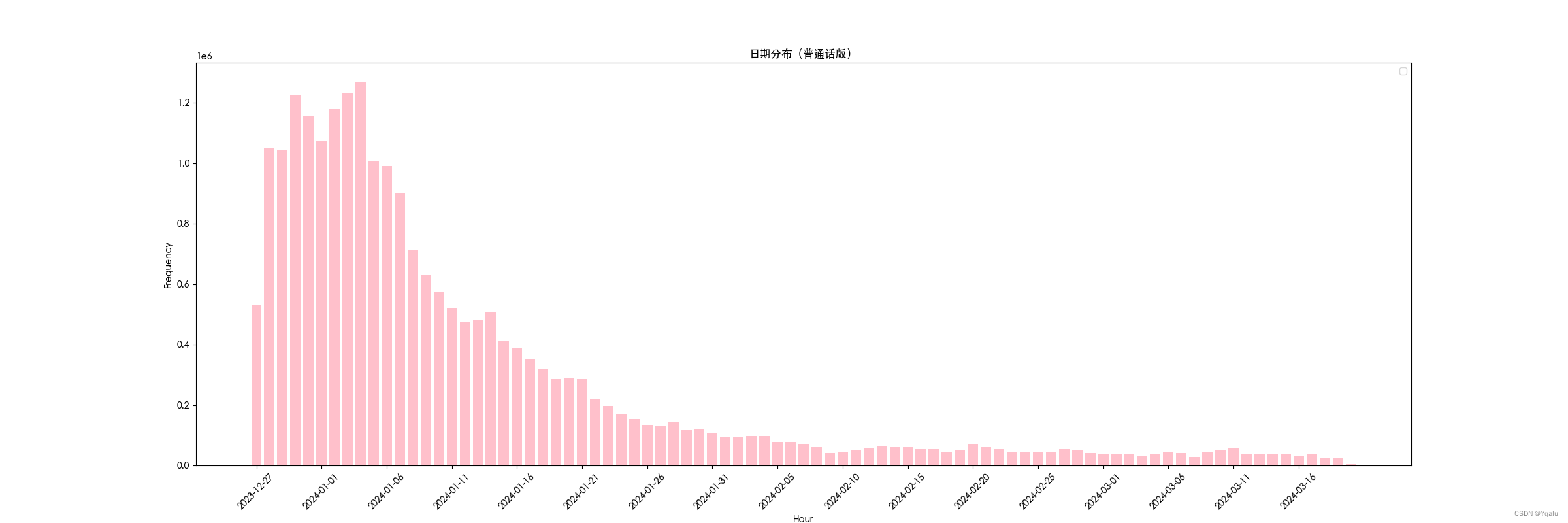
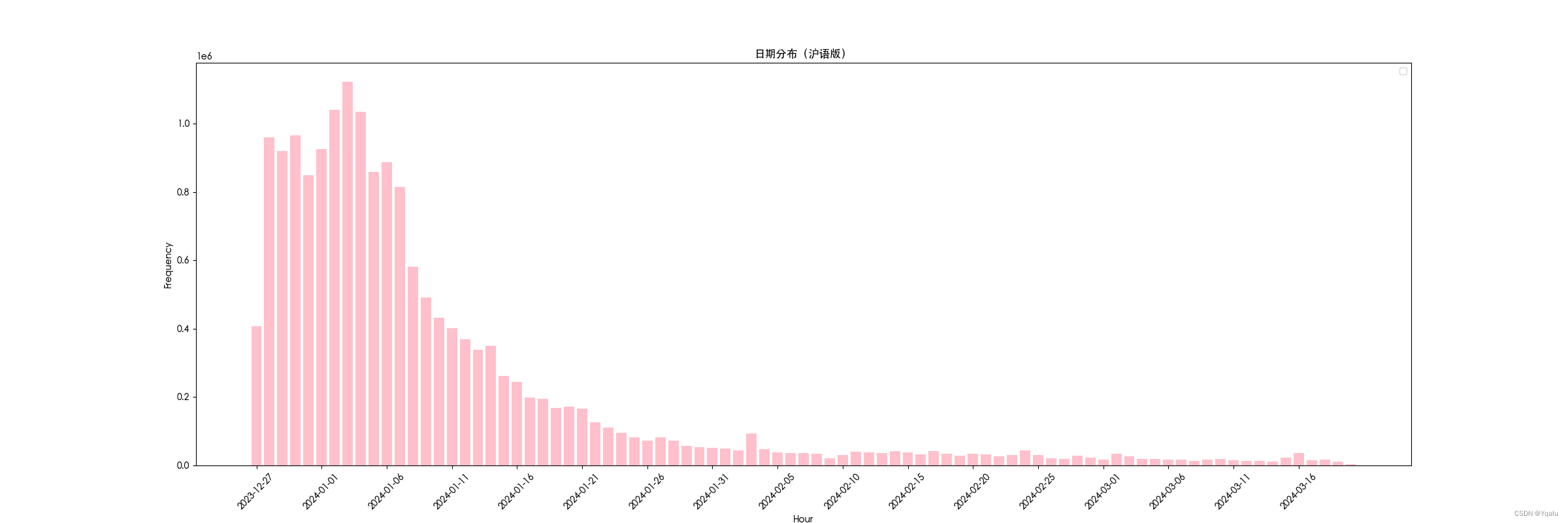
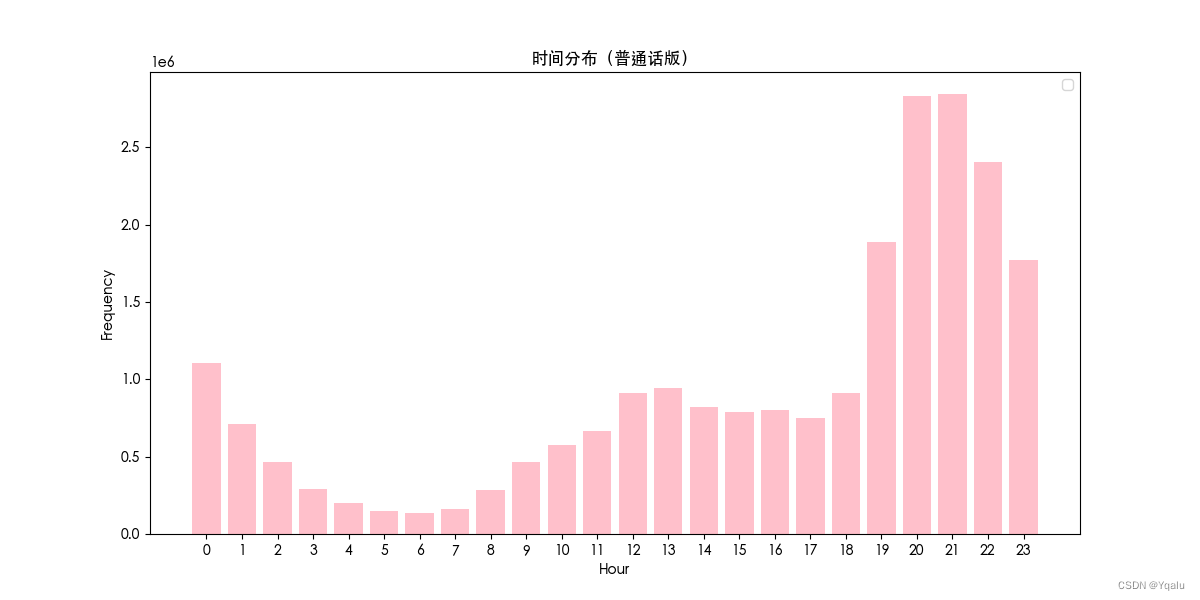
3. 日期分布
- 设置图表的大小和样式。
- 将
time列转换为字符串并截取到日期部分。 - 使用
groupby和size统计每天的弹幕数量。 - 使用
plt.bar()绘制柱状图,展示每天弹幕数量的分布。 - 设置图表的标题、轴标签等。
- 保存图表为图片文件,并显示图表。
import pandas as pd
from datetime import datetime
from snownlp import SnowNLP
d1='繁花第1集54734条弹幕.csv'
d2='繁花第2集102524条弹幕.csv'
d3='繁花第3集146823条弹幕.csv'
d4='繁花第4集190014条弹幕.csv'
d5='繁花第5集235109条弹幕.csv'
d6='繁花第6集280344条弹幕.csv'
d7='繁花第7集327469条弹幕.csv'
d8='繁花第8集375750条弹幕.csv'
d9='繁花第9集425708条弹幕.csv'
d10='繁花第10集476173条弹幕.csv'
d11='繁花第11集525328条弹幕.csv'
d12='繁花第12集574031条弹幕.csv'
d13='繁花第13集625604条弹幕.csv'
d14='繁花第14集678280条弹幕.csv'
d15='繁花第15集726749条弹幕.csv'
d16='繁花第16集778476条弹幕.csv'
d17='繁花第17集830916条弹幕.csv'
d18='繁花第18集884291条弹幕.csv'
d19='繁花第19集937939条弹幕.csv'
d20='繁花第20集990481条弹幕.csv'
d21='繁花第21集1039859条弹幕.csv'
d22='繁花第22集1090621条弹幕.csv'
d23='繁花第23集1143738条弹幕.csv'
d24='繁花第24集1194684条弹幕.csv'
d25='繁花第25集1244422条弹幕.csv'
d26='繁花第26集1296392条弹幕.csv'
d27='繁花第27集1347222条弹幕.csv'
d28='繁花第28集1395271条弹幕.csv'
d29='繁花第29集1448081条弹幕.csv'
d30='繁花第30集1511838条弹幕.csv'
list=[d1,d2,d3,d4,d5,d6,d7,d8,d9,d10,d11,d12,d13,d14,d15,d16,d17,d18,d19,d20,d21,d22,d23,d24,d25,d26,d27,d28,d29,d30]
for i in range(0,1):
data=pd.read_csv(list[i])
data['content'] = data['content'].astype(str)
data['time']=data['create_time'].map(datetime.fromtimestamp)
data['hour']=data['time'].map(lambda x:x.hour)
data['day']=data['time'].map(lambda x:x.day)
data['month']=data['time'].map(lambda x:x.month)
data['year']=data['time'].map(lambda x:x.year)
data['content_length']=data['content'].map(lambda x: len(str(x)))
data['sentiments']=data['content'].map(lambda x:SnowNLP(x).sentiments)
data.to_csv(f'繁花第{i+1}集_普通话版.csv',index=False)
length_series=data['content_length'].value_counts()
length_series.sort_index(ascending=True,inplace=True)
print(length_series)
plt.figure(figsize=(12,6))
plt.rcParams['font.sans-serif']='Heiti TC'
plt.rcParams['axes.unicode_minus'] = False
data['time']=data['time'].astype(str).str[:10]
result = data.groupby('time').size().reset_index(name='count')
plt.bar(result['time'], result['count'], color='pink')
plt.xticks(result['time'][::10], rotation=45)
plt.xlabel('hour')
plt.ylabel('弹幕数量')
plt.title('时间分析')
plt.savefig(f'繁花第{i+1}集_普通话版_日期分布')
plt.show()
print(f'繁花第{i+1}集,处理完成')三、情感分析
1. 情感分析
- 遍历
list中的每个文件路径。 - 使用
pandas读取CSV文件内容到dataDataFrame。 - 将
content列转换为字符串类型。 - 获取日期部分,将
time列的前10个字符作为新的时间值。 - 情感倾向分布图:使用
seaborn绘制sentiments列的分布图,并保存为PNG文件。

- 词云图:
- 使用
jieba对content列中的文本进行分词。 - 读取一个名为 "停用词.txt" 的文件,该文件可自行在网页检索、获取。
- 过滤掉分词结果中的停用词。
- 使用
WordCloud生成词云图,并保存为PNG文件。
- 使用

注意:
- 在生成词云时,指定了字体路径为
/System/Library/Fonts/STHeiti Medium.ttc,这是Mac OS系统中的黑体字体路径。如果在其他操作系统上运行代码,需要修改字体路径为相应的字体文件。
import pandas as pd
import numpy as np
import re
import jieba
from snownlp import SnowNLP
import matplotlib.pyplot as plt
import seaborn as sns
from wordcloud import WordCloud
d1='繁花第1集_普通话版.csv'
d2='繁花第2集_普通话版.csv'
d3='繁花第3集_普通话版.csv'
d4='繁花第4集_普通话版.csv'
d5='繁花第5集_普通话版.csv'
d6='繁花第6集_普通话版.csv'
d7='繁花第7集_普通话版.csv'
d8='繁花第8集_普通话版.csv'
d9='繁花第9集_普通话版.csv'
d10='繁花第10集_普通话版.csv'
d11='繁花第11集_普通话版.csv'
d12='繁花第12集_普通话版.csv'
d13='繁花第13集_普通话版.csv'
d14='繁花第14集_普通话版.csv'
d15='繁花第15集_普通话版.csv'
d16='繁花第16集_普通话版.csv'
d17='繁花第17集_普通话版.csv'
d18='繁花第18集_普通话版.csv'
d19='繁花第19集_普通话版.csv'
d20='繁花第20集_普通话版.csv'
d21='繁花第21集_普通话版.csv'
d22='繁花第22集_普通话版.csv'
d23='繁花第23集_普通话版.csv'
d24='繁花第24集_普通话版.csv'
d25='繁花第25集_普通话版.csv'
d26='繁花第26集_普通话版.csv'
d27='繁花第27集_普通话版.csv'
d28='繁花第28集_普通话版.csv'
d29='繁花第29集_普通话版.csv'
d30='繁花第30集_普通话版.csv'
list=[d1,d2,d3,d4,d5,d6,d7,d8,d9,d10,d11,d12,d13,d14,d15,d16,d17,d18,d19,d20,d21,d22,d23,d24,d25,d26,d27,d28,d29,d30]
for i in range(30):
data=pd.read_csv(list[i])
data['content'] = data['content'].astype(str)
data['time'] = data['time'].str[:10]
plt.figure(figsize=(8, 6))
ax = sns.distplot(data['sentiments'],hist_kws={'color': 'pink'},kde_kws={'color': 'gray'},bins=20)
ax.set_title(f'episode {i+1}')
plt.savefig(f'繁花第{i+1}集_普通话版.png')
plt.clf()
result = data.groupby('time').mean('sentiments')
result = result.reset_index()
plt.bar(result['time'], result['sentiments'], color='pink')
plt.xticks(result['time'][::10], rotation=45)
plt.xlabel('hour')
plt.ylabel('sentiments')
plt.title('情感分析')
plt.savefig(f'繁花第{i+1}集_普通话版_日期分布')
plt.clf()
data['content'] = data['content'].astype(str)
content_list = data['content'].tolist()
data_text=''.join(content_list)
seg_list=jieba.cut(data_text)
stopwords=[]
with open('停用词.txt','r',encoding='utf-8') as file:
for line in file:
stopwords.append(line.strip())
filtered_seg_list=[word for word in seg_list if word not in stopwords]
seg_text=''.join(filtered_seg_list)
wordcloud=WordCloud(font_path='/System/Library/Fonts/STHeiti Medium.ttc',colormap='magma',
width=800,height=400,background_color='white').generate(seg_text)
plt.figure(figsize=(10,5))
plt.imshow(wordcloud,interpolation='bilinear')
plt.axis('off')
plt.savefig(f'繁花第{i+1}集_普通话版_词云图.png')
print(f'繁花第{i+1}集,处理完成')
print('处理完成')
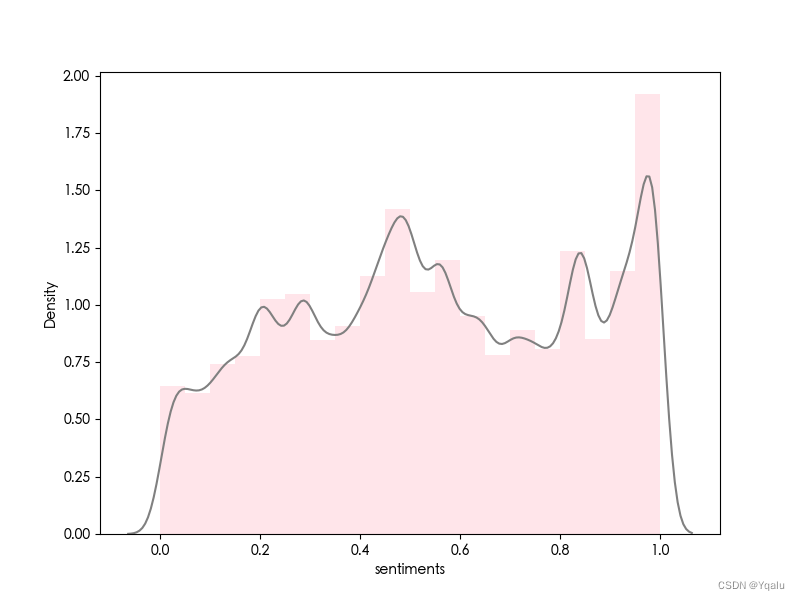
2. 地域
-
情感分析
- 使用正则表达式筛选出包含“上海”、“沪”或“魔都”的弹幕数据。
- 打印这部分弹幕数据的情感均值。
- 使用
seaborn绘制情感分布图,并保存为图片。
| 普通话版 | 沪语版 |
 | 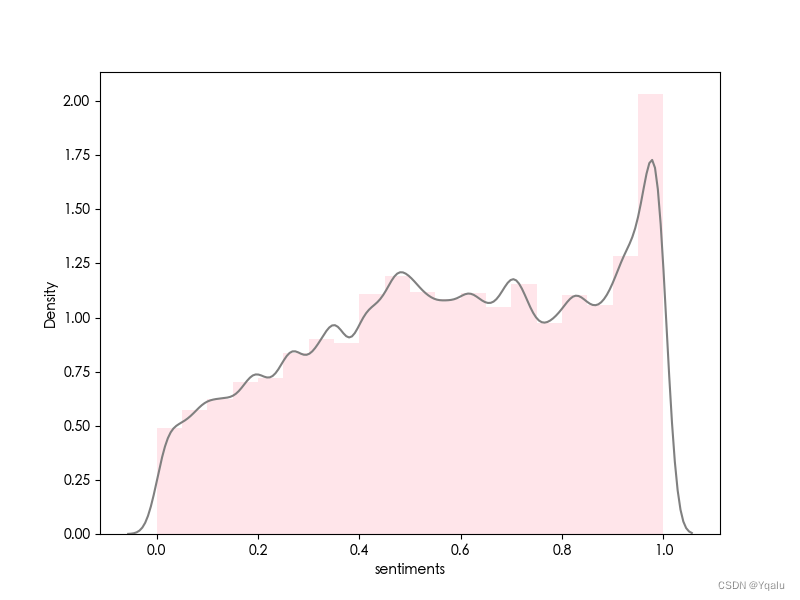 |
-
词云生成
- 将
content列的数据转换为字符串列表。 - 使用
jieba进行中文分词。 - 读取停用词文件,去除分词结果中的停用词。
- 使用
WordCloud生成词云图,并保存为图片。
- 将
import pandas as pd
import re
import jieba
import matplotlib.pyplot as plt
import seaborn as sns
from wordcloud import WordCloud
d1='繁花第1集_普通话版.csv'
d2='繁花第2集_普通话版.csv'
d3='繁花第3集_普通话版.csv'
d4='繁花第4集_普通话版.csv'
d5='繁花第5集_普通话版.csv'
d6='繁花第6集_普通话版.csv'
d7='繁花第7集_普通话版.csv'
d8='繁花第8集_普通话版.csv'
d9='繁花第9集_普通话版.csv'
d10='繁花第10集_普通话版.csv'
d11='繁花第11集_普通话版.csv'
d12='繁花第12集_普通话版.csv'
d13='繁花第13集_普通话版.csv'
d14='繁花第14集_普通话版.csv'
d15='繁花第15集_普通话版.csv'
d16='繁花第16集_普通话版.csv'
d17='繁花第17集_普通话版.csv'
d18='繁花第18集_普通话版.csv'
d19='繁花第19集_普通话版.csv'
d20='繁花第20集_普通话版.csv'
d21='繁花第21集_普通话版.csv'
d22='繁花第22集_普通话版.csv'
d23='繁花第23集_普通话版.csv'
d24='繁花第24集_普通话版.csv'
d25='繁花第25集_普通话版.csv'
d26='繁花第26集_普通话版.csv'
d27='繁花第27集_普通话版.csv'
d28='繁花第28集_普通话版.csv'
d29='繁花第29集_普通话版.csv'
d30='繁花第30集_普通话版.csv'
list=[d1,d2,d3,d4,d5,d6,d7,d8,d9,d10,d11,d12,d13,d14,d15,d16,d17,d18,d19,d20,d21,d22,d23,d24,d25,d26,d27,d28,d29,d30]
plt.rcParams['font.sans-serif']='Heiti TC'
plt.rcParams['axes.unicode_minus']=False
dataframe=pd.DataFrame()
for i in range(30):
data=pd.read_csv(list[i])
data['content']=data['content'].astype(str)
data['time']=data['time'].str[:10]
df=data.loc[data['content'].str.contains('上海|沪|魔都')]
plt.figure(figsize=(8, 6))
ax = sns.distplot(df['sentiments'], hist_kws={'color': 'pink'}, kde_kws={'color': 'gray'}, bins=20)
ax.set_title(f'episode {i + 1}')
plt.savefig(f'繁花第{i + 1}集_普通话版_城市情感.png')
plt.clf()
result=df.groupby('time').mean('sentiments')
result=result.reset_index()
plt.bar(result['time'],result['sentiments'],color='pink')
plt.xticks(result['time'][::10],rotation=45)
plt.xlabel('hour')
plt.ylabel('sentiments')
plt.title('城市形象分析')
plt.savefig(f'繁花第{i+1}集_普通话版_日期分布')
plt.clf()
content_list = df['content'].tolist()
data_text = ''.join(content_list)
seg_list = jieba.cut(data_text)
stopwords = []
with open('停用词.txt', 'r', encoding='utf-8') as file:
for line in file:
stopwords.append(line.strip())
filtered_seg_list = [word for word in seg_list if word not in stopwords]
seg_text = ''.join(filtered_seg_list)
wordcloud = WordCloud(font_path='/System/Library/Fonts/STHeiti Medium.ttc', colormap='magma',
width=800, height=400, background_color='white').generate(seg_text)
plt.figure(figsize=(10,5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.savefig(f'繁花第{i+1}集_普通话版_城市词云.png')
print(f'繁花第{i+1}集,处理完成')
dataframe.to_csv('时间分布_普通话版.csv')3. 人物
类似地,对电视剧《繁花》中的四位主要人物进行情感分析。
| 普通话版 | 沪语版 |
 | 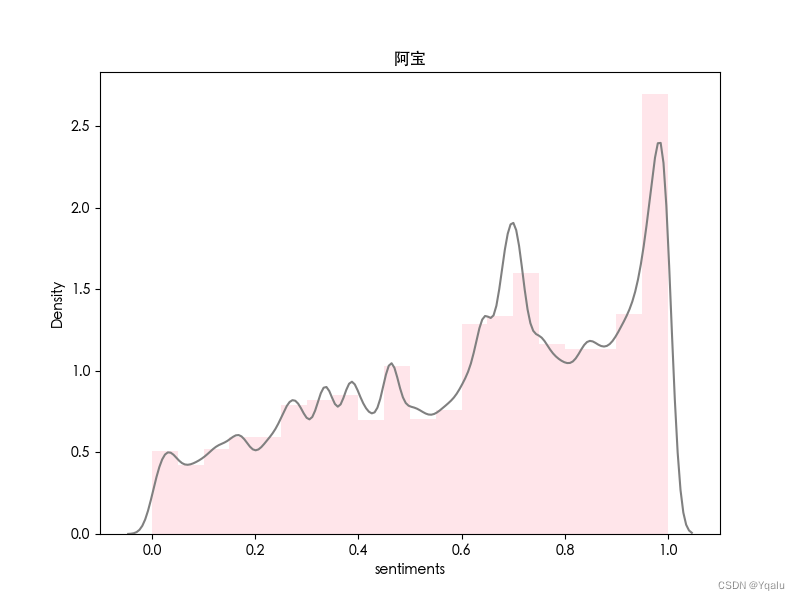 |
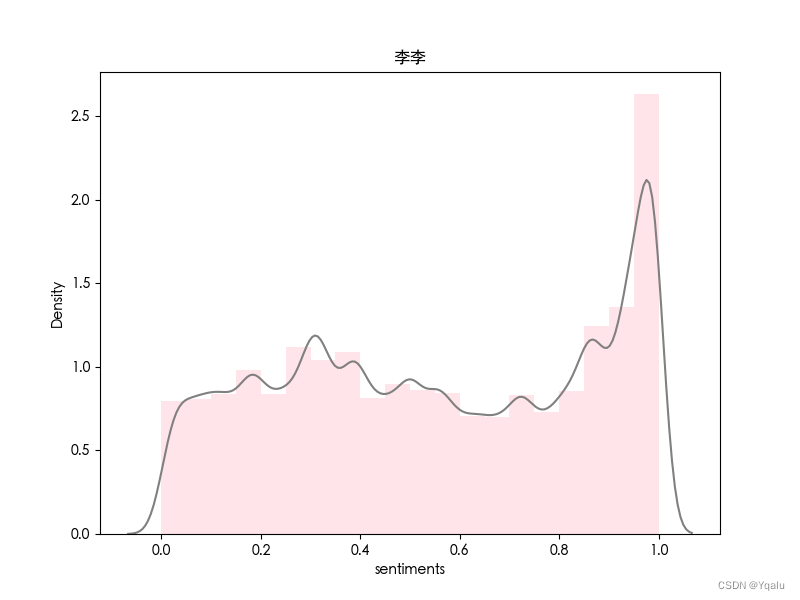 | 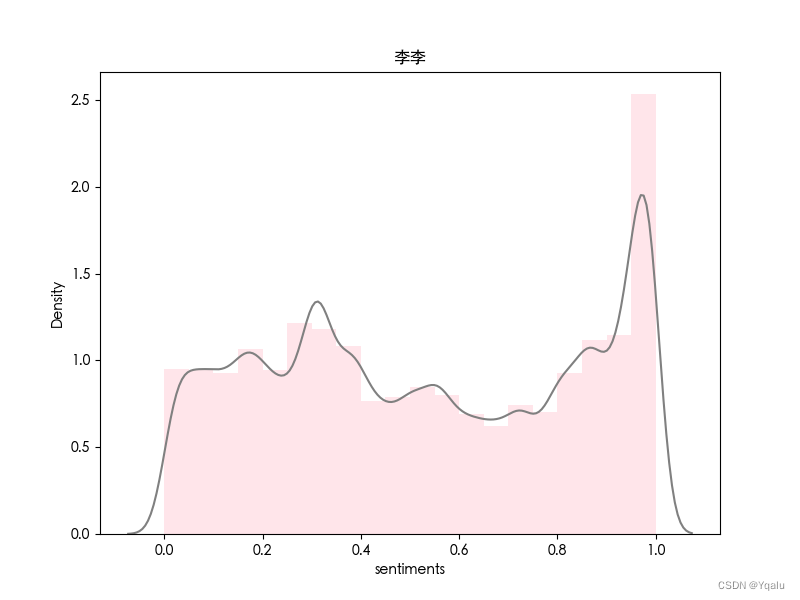 |
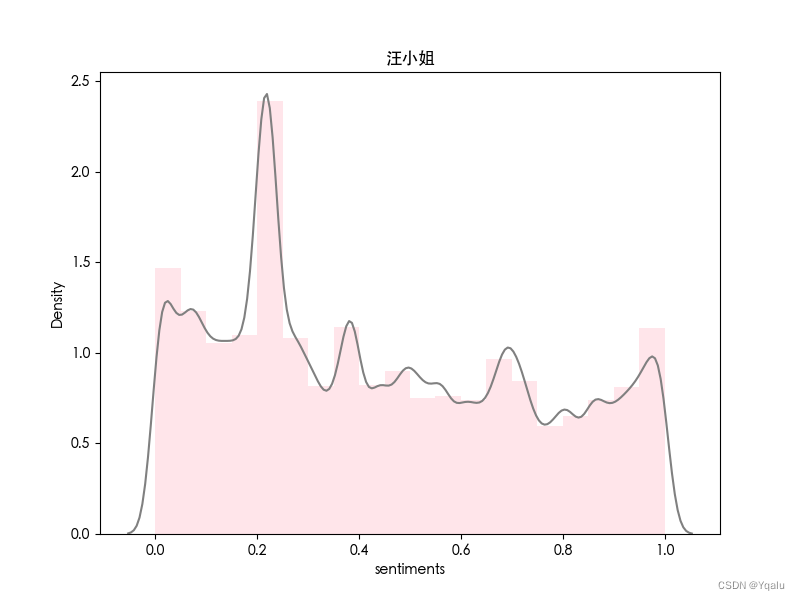 | 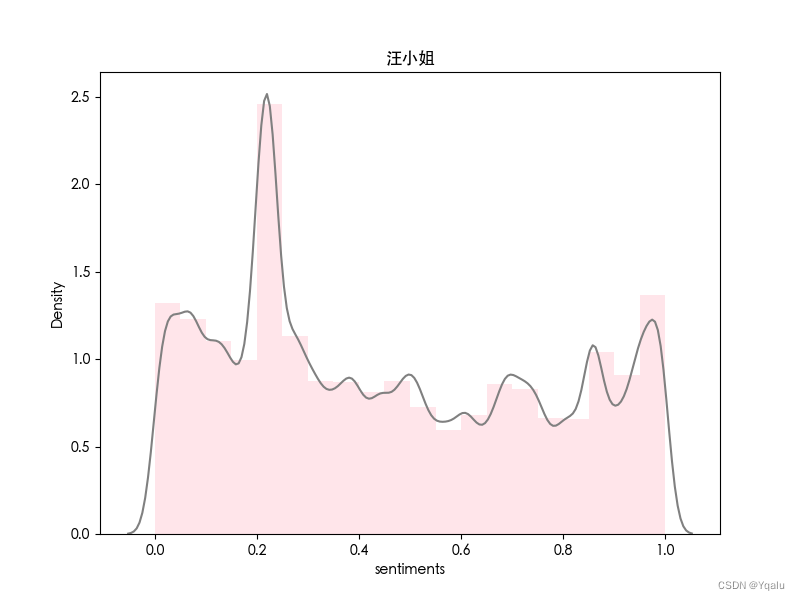 |
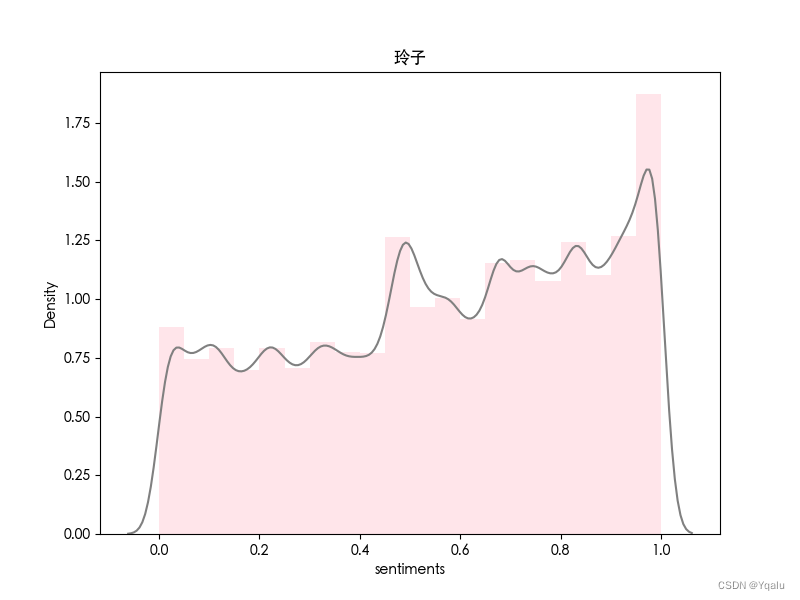 |  |
import pandas as pd
import re
import jieba
import matplotlib.pyplot as plt
import seaborn as sns
from wordcloud import WordCloud
d1='繁花第1集_普通话版.csv'
d2='繁花第2集_普通话版.csv'
d3='繁花第3集_普通话版.csv'
d4='繁花第4集_普通话版.csv'
d5='繁花第5集_普通话版.csv'
d6='繁花第6集_普通话版.csv'
d7='繁花第7集_普通话版.csv'
d8='繁花第8集_普通话版.csv'
d9='繁花第9集_普通话版.csv'
d10='繁花第10集_普通话版.csv'
d11='繁花第11集_普通话版.csv'
d12='繁花第12集_普通话版.csv'
d13='繁花第13集_普通话版.csv'
d14='繁花第14集_普通话版.csv'
d15='繁花第15集_普通话版.csv'
d16='繁花第16集_普通话版.csv'
d17='繁花第17集_普通话版.csv'
d18='繁花第18集_普通话版.csv'
d19='繁花第19集_普通话版.csv'
d20='繁花第20集_普通话版.csv'
d21='繁花第21集_普通话版.csv'
d22='繁花第22集_普通话版.csv'
d23='繁花第23集_普通话版.csv'
d24='繁花第24集_普通话版.csv'
d25='繁花第25集_普通话版.csv'
d26='繁花第26集_普通话版.csv'
d27='繁花第27集_普通话版.csv'
d28='繁花第28集_普通话版.csv'
d29='繁花第29集_普通话版.csv'
d30='繁花第30集_普通话版.csv'
list=[d1,d2,d3,d4,d5,d6,d7,d8,d9,d10,d11,d12,d13,d14,d15,d16,d17,d18,d19,d20,d21,d22,d23,d24,d25,d26,d27,d28,d29,d30]
plt.rcParams['font.sans-serif']='Heiti TC'
plt.rcParams['axes.unicode_minus']=False
data=pd.DataFrame()
for j in range(30):
df=pd.read_csv(list[j])
df['content']=df['content'].astype(str)
c1=df.loc[df['content'].str.contains('胡歌|宝总|阿宝')]
m1=c1['sentiments'].mean()
c2=df.loc[df['content'].str.contains('辛芷蕾|李李')]
m2=c2['sentiments'].mean()
c3=df.loc[df['content'].str.contains('唐嫣|汪小姐|明珠')]
m3=c3['sentiments'].mean()
c4=df.loc[df['content'].str.contains('马伊琍|玲小姐|金玲|玲子')]
m4=c4['sentiments'].mean()
print(m1,m2,m3,m4)
row_data={'阿宝':m1,'李李':m2,'汪小姐':m3,'玲子':m4}
data=data._append(row_data,ignore_index=True)
print(data)
data.to_csv('人物情感分析.csv')reference:

















 2441
2441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









