






 本文详细介绍了Word2Vec的skip-gram和CBOW模型,包括负采样策略,以及在推荐系统中的应用,如listing embedding。讨论了其优缺点,涉及词向量动态调整和Elmo等深度学习方法。
本文详细介绍了Word2Vec的skip-gram和CBOW模型,包括负采样策略,以及在推荐系统中的应用,如listing embedding。讨论了其优缺点,涉及词向量动态调整和Elmo等深度学习方法。
Word2Vec 简介
知识点
- 两种方法skip-gram和CBOW
- Skip-gram:中心词预测上下文。
目标函数:
t e x t = w 1 w 2 … w N text = w_1w_2\dots w_{N} text=w1w2…wN
arg max θ Π w ∈ t e x t Π c ∈ c ( w ) log P ( c ∣ w ; θ ) = arg max θ Π w ∈ t e x t Π c ∈ c ( w ) log e u c ⋅ v w ∑ e u c ⋅ v w = arg max θ Π w ∈ t e x t Π c ∈ c ( w ) u c ⋅ v w − log ∑ e u c ⋅ v w \begin{aligned} &\underset{\theta}{\arg \max}\underset{w\in text}{\Pi}\underset{c\in c(w)}{\Pi}\log P(c|w;\theta)\\ &=\underset{\theta}{\arg \max}\underset{w\in text}{\Pi}\underset{c\in c(w)}{\Pi}\log\frac{e^{u_{c}\cdot v_{w}}}{\sum e^{u_{c}\cdot v_{w}}}\\ &=\underset{\theta}{\arg \max}\underset{w\in text}{\Pi}\underset{c\in c(w)}{\Pi} u_{c}\cdot v_{w}-\log \sum e^{u_{c}\cdot v_{w}} \end{aligned} θargmaxw∈textΠc∈c(w)ΠlogP(c∣w;θ)=θargmaxw∈textΠc∈c(w)Πlog∑euc⋅vweuc⋅vw=θargmaxw∈textΠc∈c(w)Πuc⋅vw−log∑euc⋅vw
其中u为上下文矩阵,v为中心词向量。 - Negative Sampling
arg max θ Π ( w , c ) ∈ D P ( D = 1 ∣ w , c ; θ ) Π ( w , c ) ∈ D ~ P ( D = 0 ∣ w , c ; θ ) \underset{\theta}{\arg \max}\underset{(w,c)\in D}{\Pi}P(D=1|w,c;\theta)\underset{(w,c)\in \widetilde{D}}{\Pi}P(D=0|w,c;\theta) θargmax(w,c)∈DΠP(D=1∣w,c;θ)(w,c)∈D ΠP(D=0∣w,c;θ)
其中 D D D为正样本, D ~ \widetilde{D} D 为负样本。
时间复杂度比较高。使用随机梯度下降法求解。 - 总结:
使用skip-gram和negative sampling的方法。
-
(
w
(
中
心
词
)
,
c
(
上
下
文
)
)
∈
D
(w(中心词),c(上下文)) \in D
(w(中心词),c(上下文))∈D正样本集合。N(w):针对中心词w,进行负采样。使用随机梯度下降法求解。
u c = u c + η ⋅ ∂ l ( θ ) ∂ u c u c ′ = u c ′ + η ⋅ ∂ l ( θ ) ∂ u c ′ c ′ ∈ N ( w ) v w = v w + η ⋅ ∂ l ( θ ) ∂ v w \begin{aligned} u_{c} = u_{c} + \eta \cdot \frac{\partial l(\theta)}{\partial u_{c}}\\ u_{c'} = u_{c'} + \eta \cdot \frac{\partial l(\theta)}{\partial u_{c'}} \quad c' \in N(w)\\ v_{w} = v_{w} + \eta \cdot \frac{\partial l(\theta)}{\partial v_{w}}\\ \end{aligned}\\ uc=uc+η⋅∂uc∂l(θ)uc′=uc′+η⋅∂uc′∂l(θ)c′∈N(w)vw=vw+η⋅∂vw∂l(θ)
- 评估词向量。
- 将词向量映射到二维空间,使用TSNE进行可视化。
- 计算相似性和相关性。余弦相似度。
- 类比的方式。
如:
北京 :上海 类比 Washington : NewYork
首先计算北京上海两个词之间的距离。然后寻找与washington词的距离最近的词库中的某词,如果是newyork则比较理想,若不是则不理想。
- word2vec在推荐系统中的应用
- listing embedding的思想,把产品转换成向量。使用skip-gram的方法,做出了一些改进。
- 优缺点
- 优点:效果不错,工业界应用比较广泛。
- 缺点:
- 不考虑上下文。
- 窗口长度有限。
- 无法考虑全局。
- 无法有效学习低频词的向量。
- 未登录词(out of vocabulary)。
- learning with subword
如果测试集出现新词,不在我们的词库里。
- 场景:某些语言(具备一定的形态特征ing, ed)
- 直接忽略掉
- 将单词按照n-gram拆开,得到词向量。n可取3-6, 如reading:
^re+rea+ead+adi+din+ing+read+eadi+adin+ding+…+readin+eading
- 问题
- 当同样的词出现在不同的语境里表示是否应该一样。
- potential solution:根据单词的上下文动态调整。
E ( w o r d ) + Δ ( w o r d ) = E ′ ( w o r d ) E(word) +\Delta (word) =E'(word) E(word)+Δ(word)=E′(word)
- Elmo(Embeddings from Language Models)
- NNLM
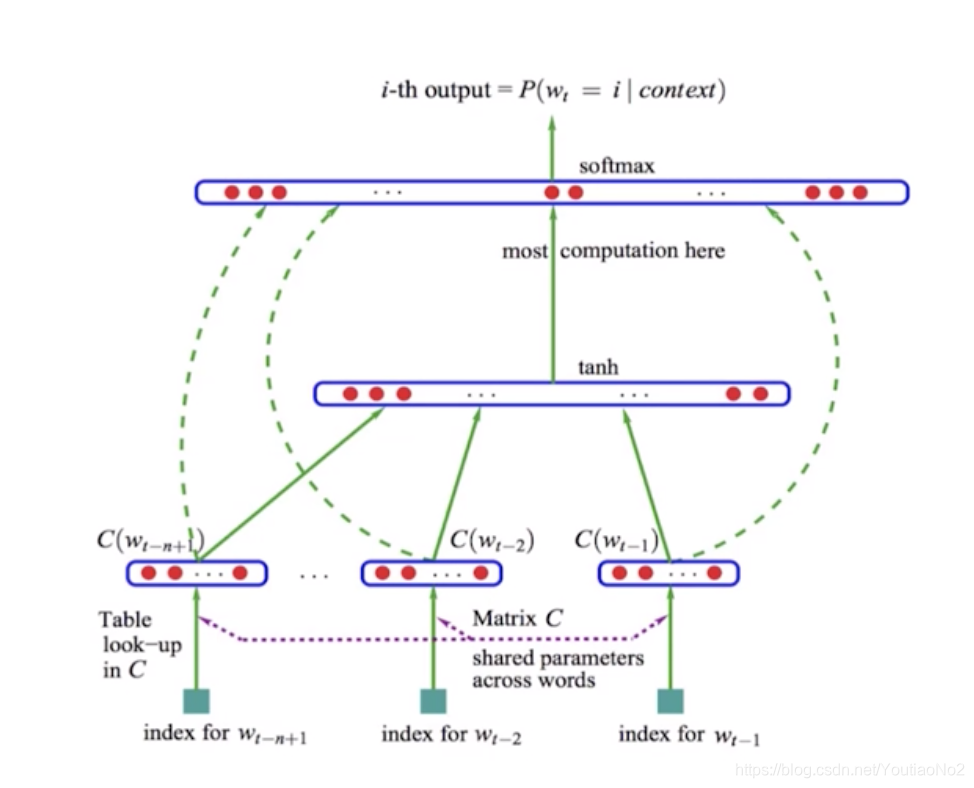
- 使用了语言模型的框架,使用了深度学习。
layer1 : Word features
layer2 : Syntactic features
layer3 : Semantic features
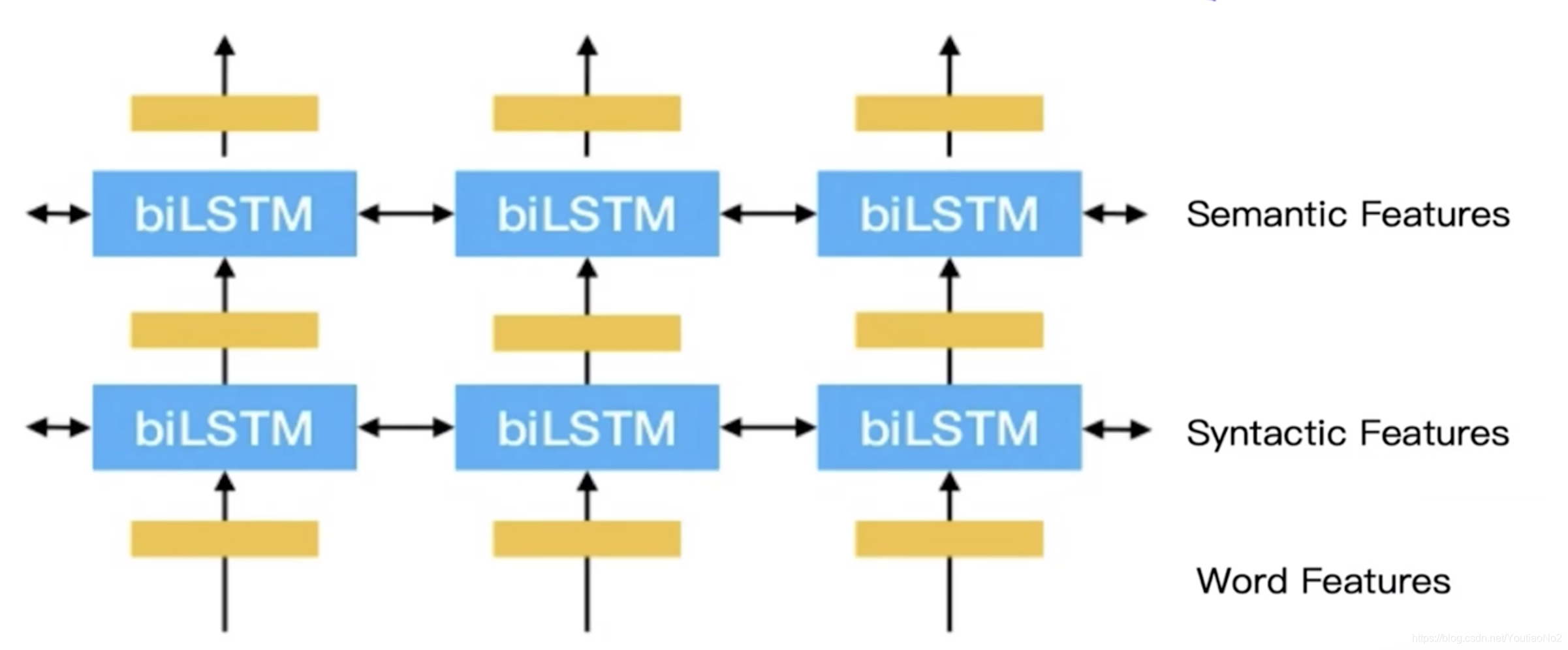
E ( w o r d ) = α 1 E ( w o r d ) + α 2 E ( w o r d ) ( 1 ) + α 3 E ( w o r d ) 2 E(word) = \alpha_1E(word)+\alpha_2E(word)^{(1)}+\alpha_3E(word)^{2} E(word)=α1E(word)+α2E(word)(1)+α3E(word)2
其中, α 1 + α 2 + α 3 = 1 \alpha_1+\alpha_2+\alpha_3=1 α1+α2+α3=1。
- 词向量表示方法
- onehot representation
- boolean
- tf-idf
- distributed representation
- global 矩阵分解法。
- local 训练时每次看的都是一定的,有窗口。
- 基于非语言模型
- skip-gram
- cbow
- glove
- 基于语言模型
- 考虑上下文
- Elmo
- Bert
- 不考虑上下文 NNLM
- 考虑上下文
- 基于非语言模型

















 1581
1581

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









