




文章目录
一、决策流介绍
在上一篇文章中,我们实现了一个完整的规则集解析过程,实现了规则引擎。具体请参考上一篇文章:智能风控决策引擎系统可落地实现方案(一):DSL。
实际风控需求通常不会只有一组规则,会对不同的规则、规则集进行编排,还会出现分支流程,子流程,形成一个更复杂风控流程,我们叫决策流,决策流的解析就是实现一个流程引擎。
流程引擎也叫工作流引擎,有很多开源实现,比较出名的是java的Activiti,jBPM5。这里我们从业务需求分析,抽象建模并自己实现流程解析过程。
二、决策流抽象建模
工作中,为了让风控分析师更方便的配置决策流,还需要配套一个可视化交互后台,所有节点以组件拖拉拽的方式提供服务,这里分享一个开源前端库。
先看一个决策流长什么样?
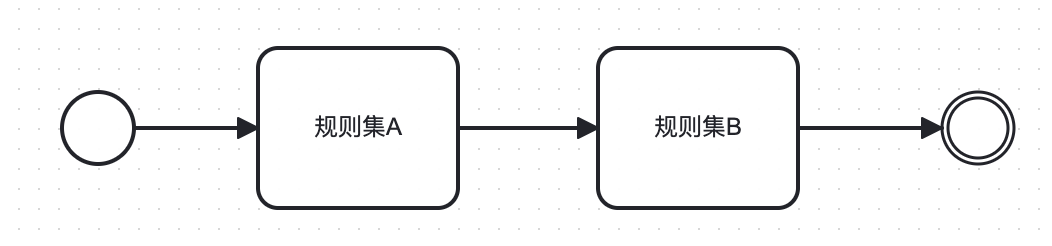
这是一个比较简单的决策流,它由两个规则集顺序编排,并有起始和结束,是符合BPMN规范的。
BPMN是什么?Business Process Diagram(BPM)是指一个业务流程图,“N”是Notation符号,BPMN业务流程建模符号,是由OMG组织维护的一套业务流程建模标准。这里我们关注和使用其中流对象(Flow)相关定义及元素。具体如下图:
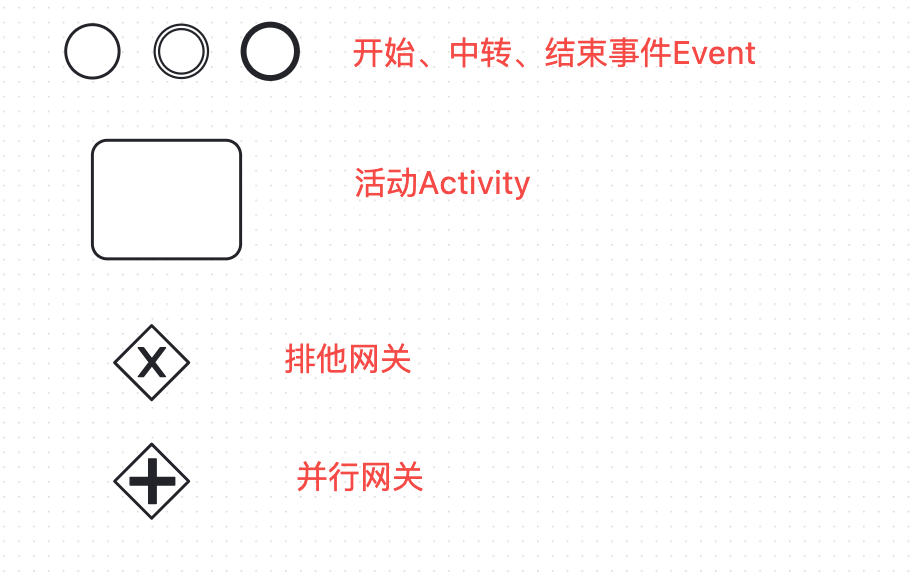
1. 简单决策流实现
流对象中,选取事件Event中开始Start Event作为决策流的开始节点,结束End Event作为决策流的结束节点,一个规则集作为一个活动Activity,后面决策树、决策矩阵等决策节点也是活动Activity的一种类型,流向Flow(箭头)作为决策流的编排执行顺序,由此一个简单的决策流就用BPMN规范做了抽象。
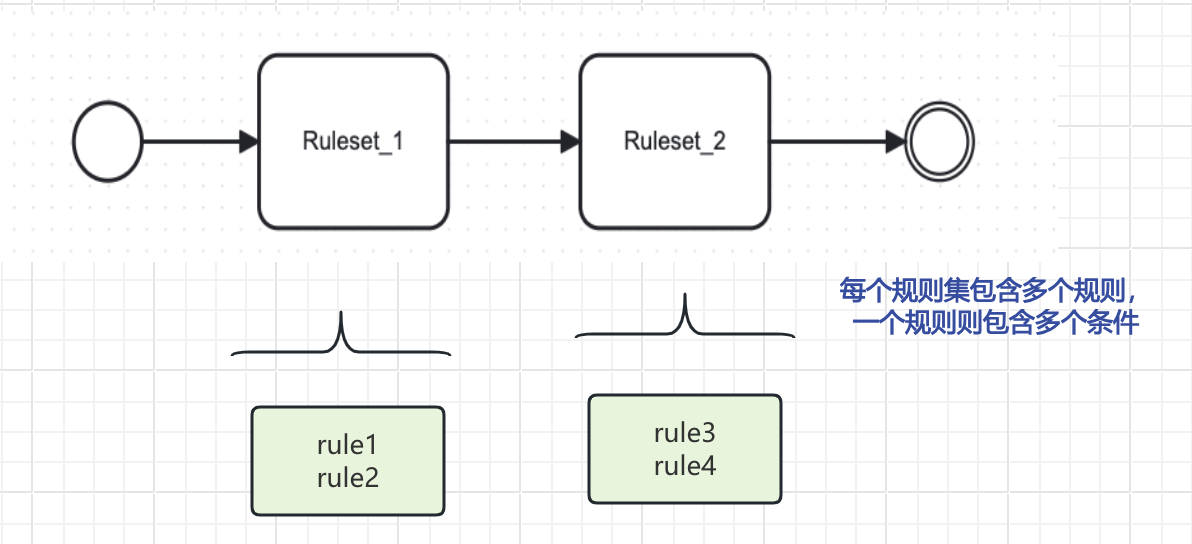
数据结构上,决策流节点使用单向线性链表,每个节点持有下一节点指针。
代码实现上,使用pipline架构作为流程解析,前一个节点解析结果(out/sink)作为下一个节点的输入(in/source),每个节点封装解析算法(parse),节点的执行结果统一存储在上下文中,直到全部节点执行完成或中断退出。
用DSL表述,将决策流抽象成Workflow结构体,由多个Node组成,具体yaml语法表达如下:
workflow:
- node:
node_name: start_1
category: start
next_node_name: ruleset_1
next_category: ruleset
- node:
node_name: ruleset_1
category: ruleset
next_node_name: ruleset_2
next_category: ruleset
- node:
node_name: ruleset_2
category: ruleset
next_node_name: end_1
next_category: end
- node:
node_name: end_1
category: end
next_node_name: ""
next_category: ""
Node结构体如下:
type Node struct {
NodeName string `yaml:"node_name"`
Category string `yaml:"category"`
NextNodeName string `yaml:"next_node_name"`
NextCategory string `yaml:"next_category"`
}
其中NodeName和NextNodeName应该在一个执行流中唯一,从而精确找到对应节点
规则集DSL抽象和上一篇一样,将多个Ruleset组成Rulesets数组,用ruleset_name进行区分。
rulesets:
- ruleset_name: ruleset_1
ruleset_category: internal
rules:
#...
- ruleset_name: ruleset_2
ruleset_category: external
rules:
#...
此时完整DSL结构体,包括Workflow代表Node节点数组,Rulesets代表规则集Ruleset数组。因为Node只是记录了当前节点可能是ruleset类型以及ruleset的name,详细信息没有记录。所以Dsl中使用Rulesets记录了当前Workflow中用到的所有ruleset,方便通过Node中的name索引出ruleset并使用。
type Dsl struct {
Workflow []Node `yaml:"workflow,flow"`
Rulesets []Ruleset `yaml:"rulesets,flow"`
}
决策流解析过程:
-
先找到
start节点,执行解析 -
循环节点下一指针,执行每个节点
parse()直到下一指针为空或中断退出 -
返回决策结果
//define result struct
type DslResult struct {
NextNodeName string
NextCategory string
Decision interface{}
Track []string
}
//dsl flow parse
func (dsl *Dsl) Parse() DslResult {
log.Println("dsl parse start...")
if len(dsl.Workflow) == 0 {
panic("dsl workflow is empty")
}
var result = new(DslResult)
//from start node
firstNode := dsl.FindStartNode()
dsl.gotoNextNode(firstNode.NodeName, firstNode.Category, result)
//loop parse node and go to next node
for !isBreakDecision(result.Decision) && result.NextNodeName != "" {
dsl.gotoNextNode(result.NextNodeName, result.NextCategory, result)
}
log.Println("dsl parse end.")
return result
}
//parse node and find next
func (dsl *Dsl) gotoNextNode(nodeName string, category string, result *DslResult) {
//find current node from workflow
node := dsl.FindNode(nodeName)
if node == "" {
return
}
result.Track = append(result.Track, nodeName)
//default
result.NextNodeName = node.NextNodeName
result.NextCategory = node.NextCategory
result.Decision = nil
//parse different category node
switch category {
case configs.START:
return
case configs.RULESET:
ruleset := dsl.FindRuleset(node.NodeName)
result.Decision = ruleset.parse()
case configs.END:
result.NextNodeName = ""
result.NextCategory = ""
}
}
2.增加决策流分支
分支流程需要增加网关Gateway节点,网关又分为并行网关、排它网关、包容网关,而排它网关更符合风控场景业务语义,即一个决策流只能走一个分支。
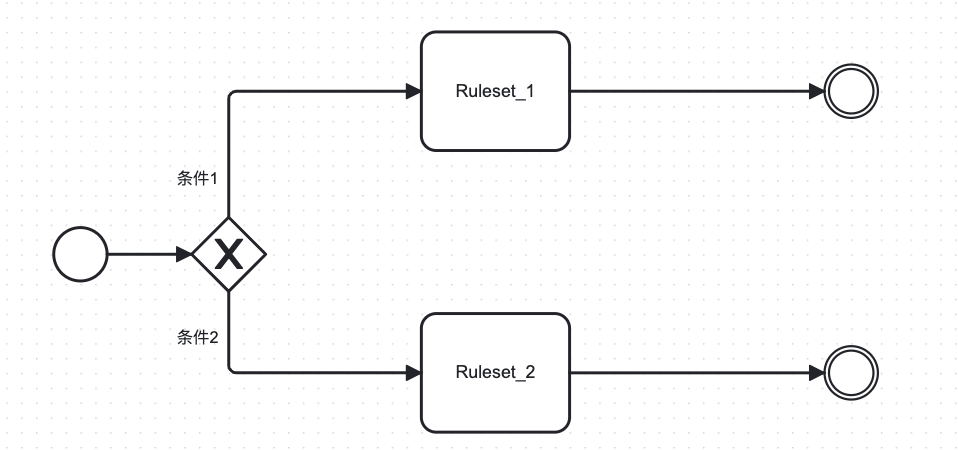
决策流满足条件1时走第一条分支,经过Ruleset_1,满足条件2时走Ruleset_2的分支。
2.1 数据结构选择
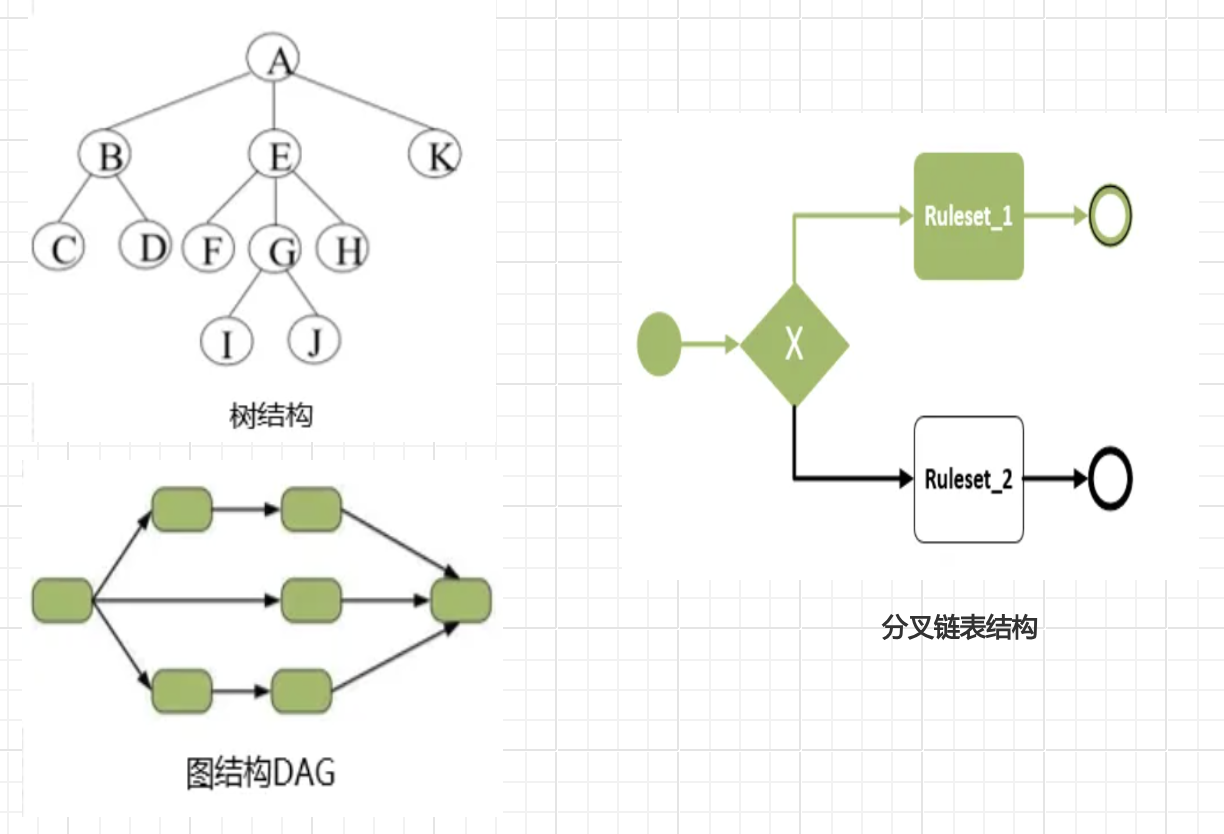
增加了分支流程,线性链表结构是否仍适用?树结构,图结构,链表结构如何选择?
首选考虑树结构,可能是N叉树,也可能是无分支的线性结构,且是有向的,因此树结构并不合适。
进一步考虑有向图结构(如有向无环图DAG),图的解析主要是进行深度或广度遍历,可以执行每条分支流程,因此图的遍历更适合做并行网关(实际上工作中DAG最常用,互斥和并行都可以做,只是并行时Node能通过的分支有多个罢了),而决策流是排它网关语义,同时有且只有一个分支满足执行条件,使用图结构并不合适,一次决策的执行流程,更像一个链式流程,更适合分叉链表结构。
2.2 条件网关实现【本质就是一个分流节点】
条件网关功能:满足某个分支线上的条件即走该分支。
条件网关解析:循环执行每个分支的条件表达式,并选择结果为true的第一个分支,决策结果即为决策流下一步要走的分支名。这里也注意,一般情况不允许配置两个分支条件有重合,可以同时满足的情况。
//conditinal gateway node
type Conditional struct {
ConditionalName string `yaml:"conditional_name"`
Depends []string `yaml:"depends"`
Branchs []Branch `yaml:"branchs,flow"`
}
//branch in conditional
type Branch struct {
BranchName string `yaml:"branch_name"`
Conditions []Condition `yaml:"conditions"`
Logic string `yaml:"logic"`
Decision string `yaml:"decision"`
}
//conditional gateway parse
func (conditional *Conditional) parse() string {
depends := internal.GetFeatures(conditional.Depends) //need to check
for _, branch := range conditional.Branchs { //loop all the branch
var conditionRs = make([]bool, 0)
for _, condition := range branch.Conditions {
if data, ok := depends[condition.Feature]; ok {
rs, _ := operator.Compare(condition.Operator, data, condition.Value)
conditionRs = append(conditionRs, rs)
} else { //get feature fail
continue //can modify according scene
}
}
logicRs, _ := operator.Boolean(conditionRs, branch.Logic)
if logicRs { //if true, choose the branch and break
return branch.Decision
} else {
continue
}
}
return "" //can't find any branch
}
现在把条件网关加入workflow,即构造了完整DSL语法。
workflow:
- node:
node_name: start_1
category: start
next_node_name: conditional_1
next_category: conditional
- node:
node_name: conditional_1
category: conditional
next_node_name: "" # 网关节点的下一节点是在执行网关的parse方法时决定的
next_category: ""
- node:
node_name: ruleset_1
node_category: ruleset
next_node_name: end_1
next_category: end
- node:
node_name: ruleset_2
node_category: ruleset
next_node_name: end_2
next_category: end
- node:
node_name: end_1
node_category: end
next_node_name: ""
next_category: ""
- node:
node_name: end_2
node_category: end
next_node_name: ""
next_category: ""
决策流执行过程需要加上对条件网关conditional的执行解析。
func (dsl *Dsl) gotoNextNode(nodeName string, category string, result *DslResult) {
//...
switch category {
//...
case configs.CONDITIONAL:
conditional := dsl.FindConditional(node.NodeName)
rs := conditional.parse()
if rs == nil { //not match any branch, error
result.NextNodeName = ""
log.Println(node.NodeName, "not match any branch")
} else {
result.NextNodeName = rs.(string)
result.NextCategory = dsl.FindNode(rs.(string)).Category
}
}
}
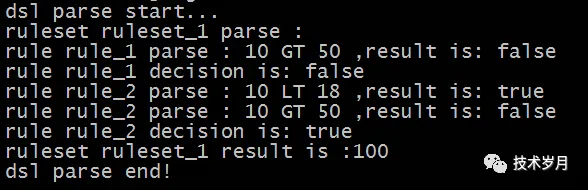
最后决策流执行情况如下:

3. AB概率分流网关实现
风控工作中,需要不断对规则策略和模型进行迭代优化,新的规则模型效果需要经过实验证明,与原规则模型进行效果比对,选择较优的规则模型使用,这种叫冠军/挑战者试验,原规则模型分支叫冠军,新增分支叫挑战者,也有叫A/B Test。
这里使用分流网关来实现ABTest,决策流配置如下:

abtests:
- abtest:
abtest_name: abtest_1
branchs:
- branch:
branch_name: branch_1
percent: 45
decision: ruleset_1
- branch:
branch_name: branch_2
percent: 55
decision: ruleset_2
代码实现上,45%的流量分给第一分支,55%流量分给第二分支,这里实现一个0-99随机数,获取结果大于45,走分支2,否则走分支1。
rand.Seed(time.Now().UnixNano())
rs := rand.Intn(99)
具体实现上仍有几个问题需要考虑:
-
流量配比可能为小数。
-
流量配比之和应该为
100,可在发布时校验。 -
随机种子的设置,如果希望随机数与用户
id和实验名相关,需要取其hash来设置种子seed。 -
实验及分流可用
redis/mysql固化,下一次直接使用(有些业务场景需求)。
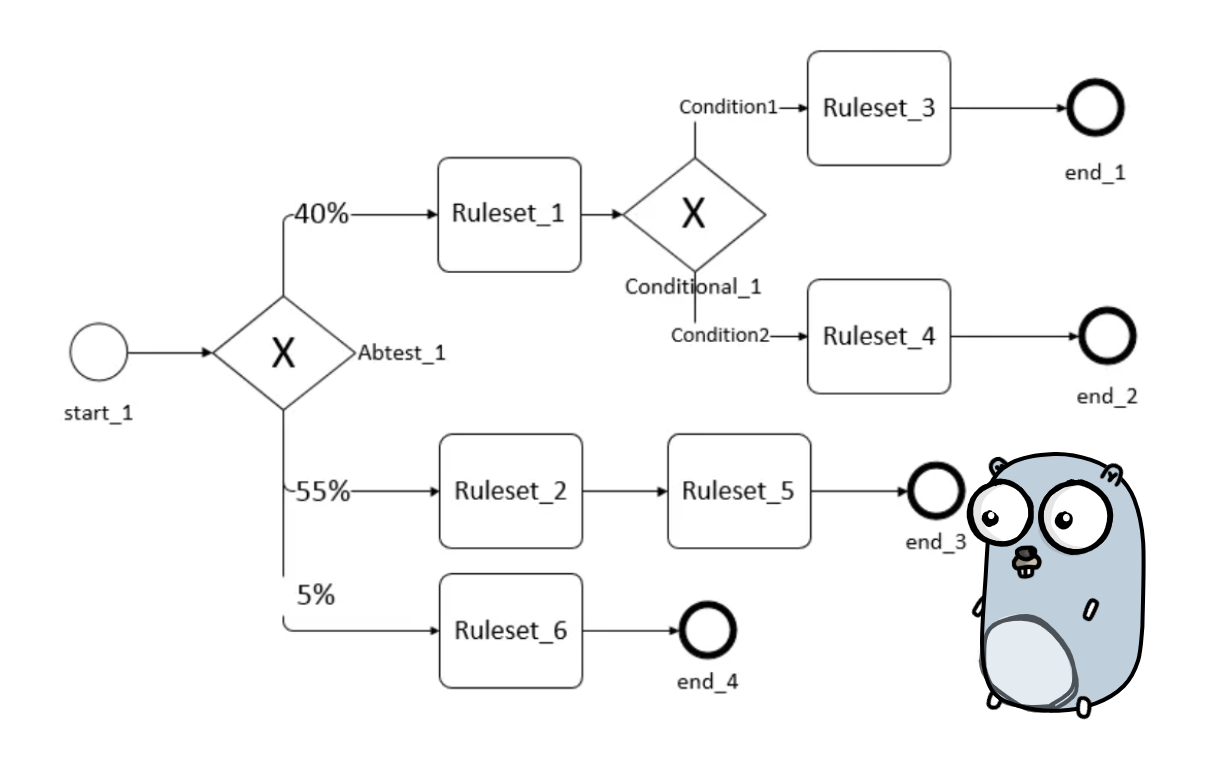
4. 复杂决策流实现
目前实现了开始、结束、规则集、条件分流网关、AB概率分流网关,通过组合几种节点,即可实现了大多数风控场景下的决策流配置。
三、问题与思考
1. 配置决策流是否汇合
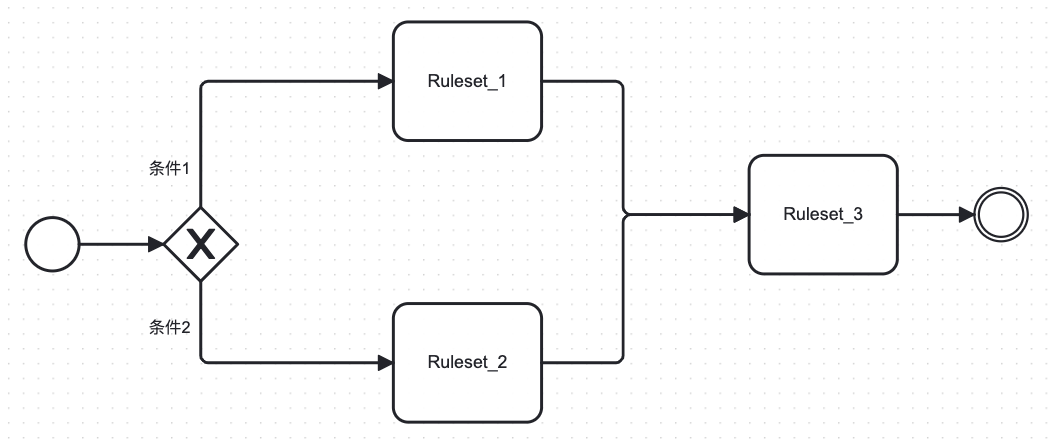
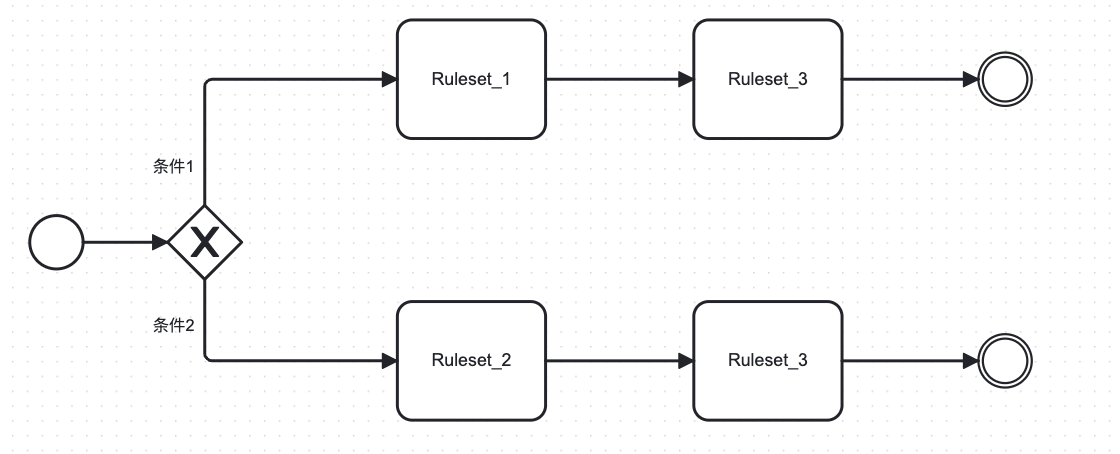
其中条件1和条件2分别表示的是Conditional结构体
第一种配置会省事一些,第二种对分支表述会更清晰些,如果针对更复杂的流,有汇合逻辑会更复杂且易出错。
在实际执行解析过程中,由于链式解析,之前的代码可支持上述两种方式都正常解析。Workflow配置一个end节点还是两个end节点,之前是按两个结束节点表述,这里可改成一个end节点:
workflow:
#...
- node:
node_name: ruleset_3
node_category: ruleset
next_node_name: end_1
next_category: end
- node:
node_name: ruleset_4
node_category: ruleset
next_node_name: end_1
next_category: end
- node:
node_name: end_1
node_category: end
next_node_name: ""
next_category: ""
2.决策流管理后台
工作中,为了让风控分析师更方便的配置决策流,还需要配套一个可视化交互后台,所有节点以组件拖拉拽的方式提供服务,这里分享一个开源前端库。
通过该组件,可以生成一个XML格式文件,我们对其进行解析,然后转化为我们需要的Yaml格式DSL文件。
3.获取依赖特征数据
决策流执行和规则执行都离不开特征数据的支持,而特征数据何时加载会对解析效率有不同影响。一般有两种方式:
-
决策流执行前将数据全部获取
-
边解析决策流边加载特征
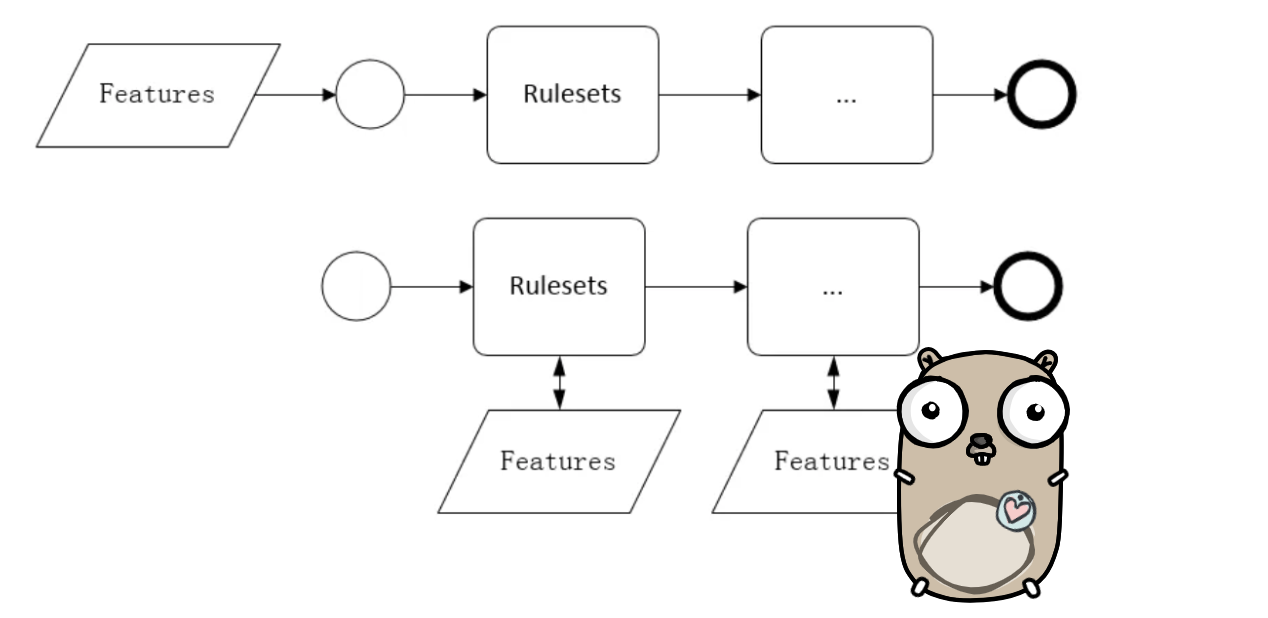
一些商业决策引擎就需要先将所有数据特征加工好,统一推给决策引擎,决策引擎给出决策结果。这种方式主要缺点:决策请求数据不同,可能执行第一个规则(集)即命中拒绝中断,剩余规则(集)依赖的特征就没必要加载,如果这部分特征来自三方收费数据源,会导致数据成本浪费,所以按需加载更符合一般业务场景。
实际风控场景,会拆分内部数据规则集和外部数据规则集,决策先使用内部数据规则集,如命中拒绝即退出不再执行外部数据规则集。更精细化控制,可将外部数据规则集中每条规则做优先级排序,规则集执行策略按命中即退出模式,这样可进一步控制外部数据成本。
4.关于决策流退出
决策流以pipline方式依次执行,引起决策流退出的情况可能有如下几种:
决策流执行到end节点,正常结束退出。
决策流执行规则集结果为拒绝,根据业务语义中断退出(isBreakDecision代码进行控制),这里是隐式的进行了退出,也有配置结束节点显示退出的做法,但每个规则集配置一个并不方便。
决策流执行条件网关未匹配到任何分支,或决策流在获取依赖特征时因系统问题导致失败,这时候触发异常退出情况,需要进行监控和报警处理。
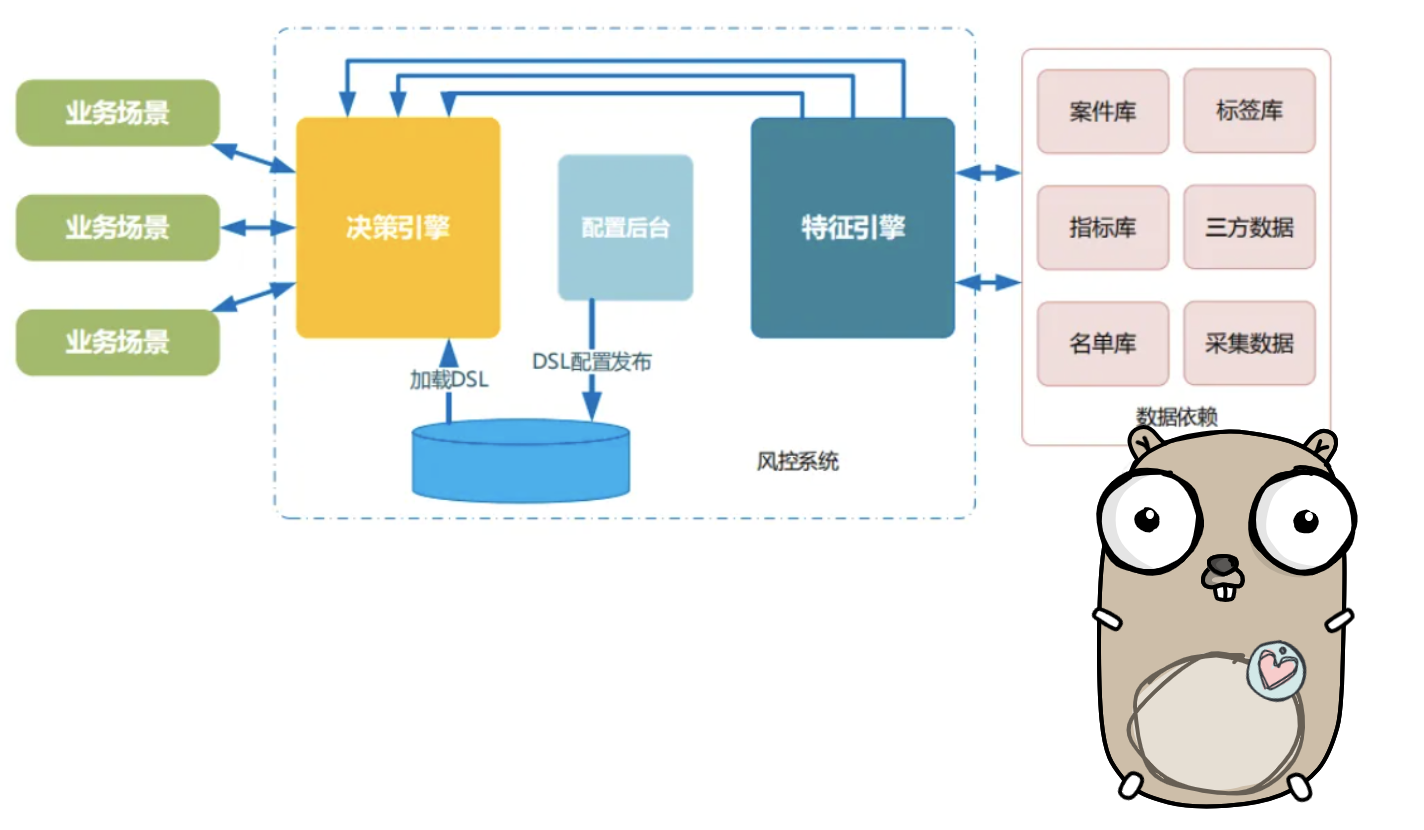
5.架构部署
将决策引擎部署成一个web服务,使用gin或net/http即可轻松搭建一个api服务,业务场景在需要风控时调用决策引擎系统,获取决策结果数据。
决策引擎在启动时加载DSL到内存,当有变更发布时更新内存DSL,关于如何热发布后续文章会进一步分析。
数据返回一般可以包括:
结果数据,拒绝还是通过;过程数据,命中规则、规则集情况,执行路径,执行分支,以及每个特征值情况,用于后期分析使用。
结果数据可落地mysql数据库,较大的数据源数据可存储hbase,或通过log、kafka等方式异步存储。
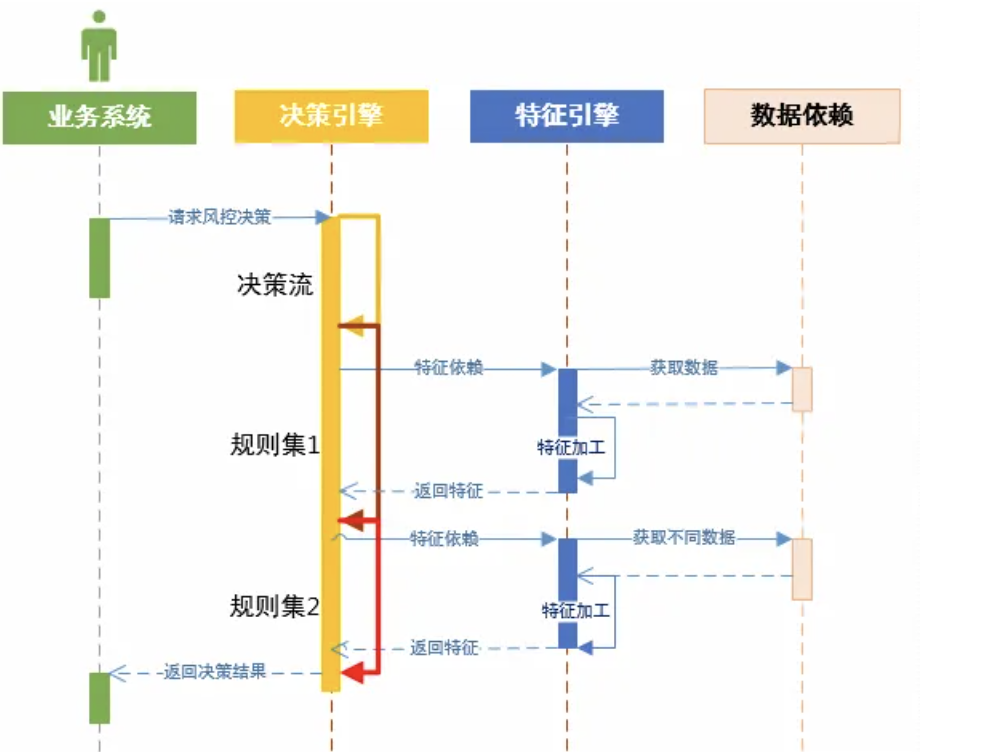
决策引擎依赖的特征数据可从特征引擎获取,特征引擎进行数据库、数据源的对接以及特征衍生加工,有些公司会进一步拆分成(前置)数据平台和特征加工平台两个系统。
具体架构图如下:
执行引擎流程时序图:
6.引入模型及模型引擎
使用规则策略做风控,通常只能决策是否通过,适用于反欺诈,而综合评估用户风险等级,对用户进行信用评级,通过风险定价可进一步提升风控能力。随着大数据技术的发展,对数据的深度挖掘并建立机器学习、深度学习模型,成为更重要的风控手段。通过模型结果,可更精细化的进行风险评估。下一篇,我们将介绍模型相关开发和技术实现。
原文地址:https://mp.weixin.qq.com/s?__biz=MzIyMzMxNjYwNw==&mid=2247483770&idx=1&sn=3166a6617ddb6b628261b8b7ff84cfac&chksm=e8215e6adf56d77cb76de41b63e63759221932f030e315acebbc4025939b2e02b354a9072ecc&cur_album_id=2282168918070968323&scene=189#wechat_redirect

















 916
916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









