









字典树
插入 Insert
就是树结构,前缀相同的情况下,insert进来的新的单词只需要在以后的单词后边加上除去前缀不同剩下的部分,如果到一个完整的残次单词(比如图中带星星的节点就会有一个值,类似于哈希表,如果需要查找某个单词的话,就从根节点开始遍历,如果最后能够有值返还的话说明树中存在这个单词,为True)。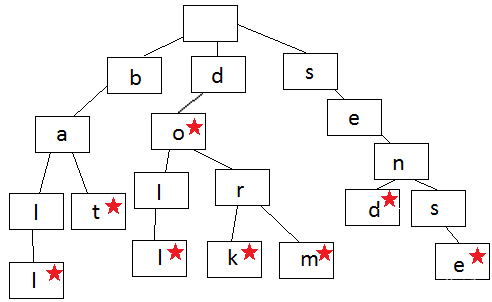
Delect 删除
删除的话,如果是叶子结点,就会删除到分支,没有分支就整一个单词全部删除,包括存储的值
如果是存储的值的根节点,比如图中的do,就把o的值删除
Python思想
可以用{长度:单词}的字典类型来代替树结构,因为python dict的底层逻辑就是红黑树类的结构,
- 插入的时候就检查是否有相同长度的,如果不相同,说明是一个新的,直接Dict[len(word)] = String
- 查找是否有相同前缀的话 其实就是遍历字典的vlaue,考察string.startswith()的用法。
Leetcode 208
以上其实就是LeetCode208 题目的解法
class Trie(object):
def __init__(self):
self.root = {}
def insert(self, word):
node = self.root
for i in range(len(word)):
if word[i] not in node:
node[word[i]] = {}
if i == len(word)-1 :
node['end'] = True
else:
node = node[word[i]]
def search(self, word):
i = 0
node = self.root
for c in word:
if c in node:
if 'end' in node and i== len(word)-1:
return True
node = node[c]
i += 1
return False #返回True
def startsWith(self, prefix):
node = self.root
for c in prefix:
if c not in node:
return False
node = node[c]
return True
Leetcode 720
longest word in Ditionary 字典中最长的单词
给出一个字符串数组 words 组成的一本英语词典。返回 words 中最长的一个单词,该单词是由 words 词典中其他单词逐步添加一个字母组成
这里面的逐步添加限制了我们每成功添加一个单词之后都需要标记一个星号,如果没有这个星号的话,我们需要直接返还一个False,这个是跟208题很大的区别,208是只有在结尾的需要才需要查询一个值,所以在插入和查询的时候都会有些许差别,
from typing import List
class Solution:
def longestWord(self, words: List[str]) -> str:
trie = Trie()
for word in words:
trie.insert(word)
ans = ""
for word in words:
if (len(word) > len(ans) #如果更长
or (len(word) == len(ans) and word < ans) ) and trie.search(word): #同样长并且字典序小 以上两点满足一点并且能找得到这个字典序小的单词
ans = word #替换目标值
return ans
class Trie(object):
def __init__(self):
self.root = {'end':True}
def insert(self, word):
node = self.root
for c in word:
if c not in node:
node[c] = {}
node = node[c]
node['end'] = True
def search(self, word):
node = self.root
for c in word:
if c not in node or 'end' not in node:
return False
node = node[c]
return 'end' in node
def startsWith(self, prefix):
node = self.root
for c in prefix:
if c not in node:
return False
node = node[c]
return True
words = ["a", "banana", "app", "appl", "ap", "apply", "apple"]
result = Solution()
result.longestWord(words)
Leetcode 692
前K个 高频的单词,这个和字典树720题的情况又不太一样,因为我们需要自己去记录每个数出现的频次,并对键值对的值做排序,排序之后会根据字典序的顺序排列在字典里面,所以这个时候我们需要用到栈的方法把它加入一个栈里边,然后再对比我们需求的数量出栈,这个方法可能比较浪费内存,因为需要用到一个全局的字典和一个排序后的字典,还需要一个local的栈给我们进出以保证是按照字典序输出,时间复杂度上因为我们用到了排序需要O(n)的复杂度,再加上进出栈复杂度会比比较高,但也是我想得出来的一个能够符合题目的解法了。
字典value排序demo
def dictionairy():
# 声明字典
key_value ={}
# 初始化
key_value['a'] = 56
key_value['b'] = 2
key_value['c'] = 12
key_value['d'] = 24
key_value['e'] = 18
key_value['f'] = 18
key_value['h'] = 323
print ("按值(value)排序:")
print(sorted(key_value.items(), key = lambda kv:(kv[1], kv[0])))
if __name__== "__main__":
dictionairy()
力扣解法
class Solution(object):
def __init__(self):
self.dic = {}
self.lis = []
def insert(self, word: str) -> None:
if word not in self.lis:
self.lis.append(word)
self.dic[word] = 1
else :
self.dic[word] += 1
def search(self, word: str) -> bool:
if len(word) not in self.dic:return False
alist = self.dic.get(len(word))
if word in alist:return True
return False
def startsWith(self, prefix: str) -> bool:
for key,val in self.dic.items():
for x in val:
if x.startswith(prefix):
return True
return False
def topKFrequent(self, words: List[str], k: int) -> List[str]:
ans = []
tmplist = []
for word in words:
self.insert(word)
ans_list = sorted(self.dic.items(), key = lambda kv:(kv[1], kv[0]))
i = 1
y = 0
while(i<=k):
TmpWord = ans_list[len(ans_list)-1][0]
TmpValue = ans_list[len(ans_list)-1][1]
PreValue = ans_list[len(ans_list)-2][1]
#若存在相同的出现的次数,但是字母不同,按照字典序排序
if (TmpValue == PreValue):
while (ans_list[len(ans_list)-1][1] == TmpValue):
y += 1
tmplist.append(ans_list.pop())
if (len(ans_list)==0): break
if (y-(k-i+1)>0): #存在y个相同,但目标只需要k-i+1个
y = k - i + 1
for num in range(y):
ans.append(tmplist.pop()[0])
i += 1
y = 0
else :
ans.append(ans_list.pop()[0])
i += 1
return ans


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









