






- 安装anaconda,python,PyCharm
- 下载yolov5压缩包,解压到d盘 地址:GitCode - 全球开发者的开源社区,开源代码托管平台
- Win+r,运行:
conda create -n yolov5 python=3.8#第一步创建虚拟环境,yolov5是自拟的环境名,可以更改
activate yolov5 #创建yolo环境
conda install pytorch torchvision torchaudio cpuonly -c pytorch#安装cpu版本的pytorch
- 安装yolov5所需库
需要通过anaconda prompt 进入yolov5环境中,按照下图cd到yolov5根目录下。


#进入yolov5的根目录(最内部的一个同名文件夹yolov5-master)后,安装所需库。
- Pycharm打开yolov5(可直接将最外部的同名文件夹yolov5-master拖入PyCharm打开),
如果你的pycharm终端路径前有(ps),则说明终端使用的powershell.
修改shell路径和默认标签页名称:
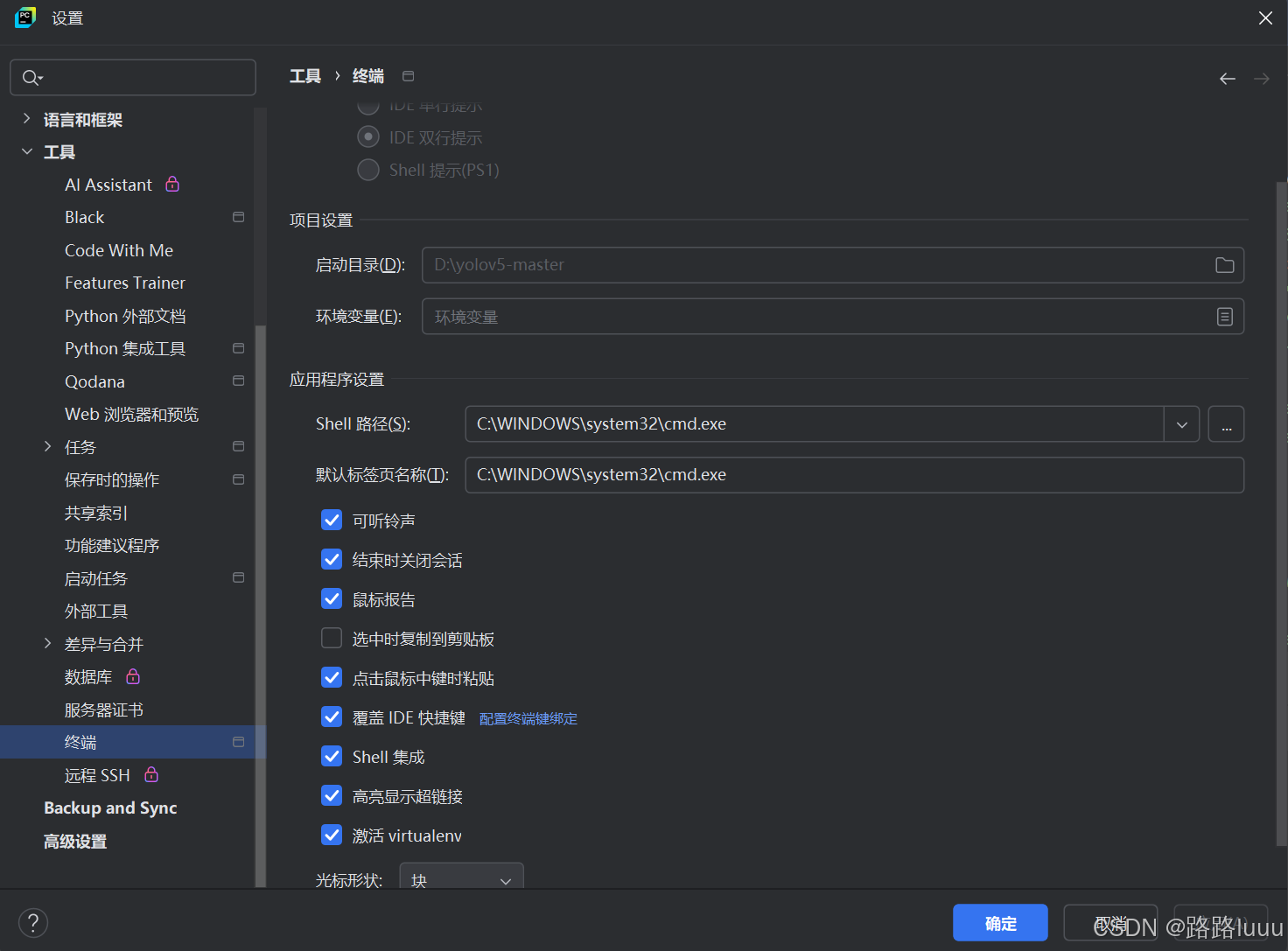
-
ps就会消失,若仍未消失,可以尝试右击yolov5文件在终端打开。
- 配置环境:
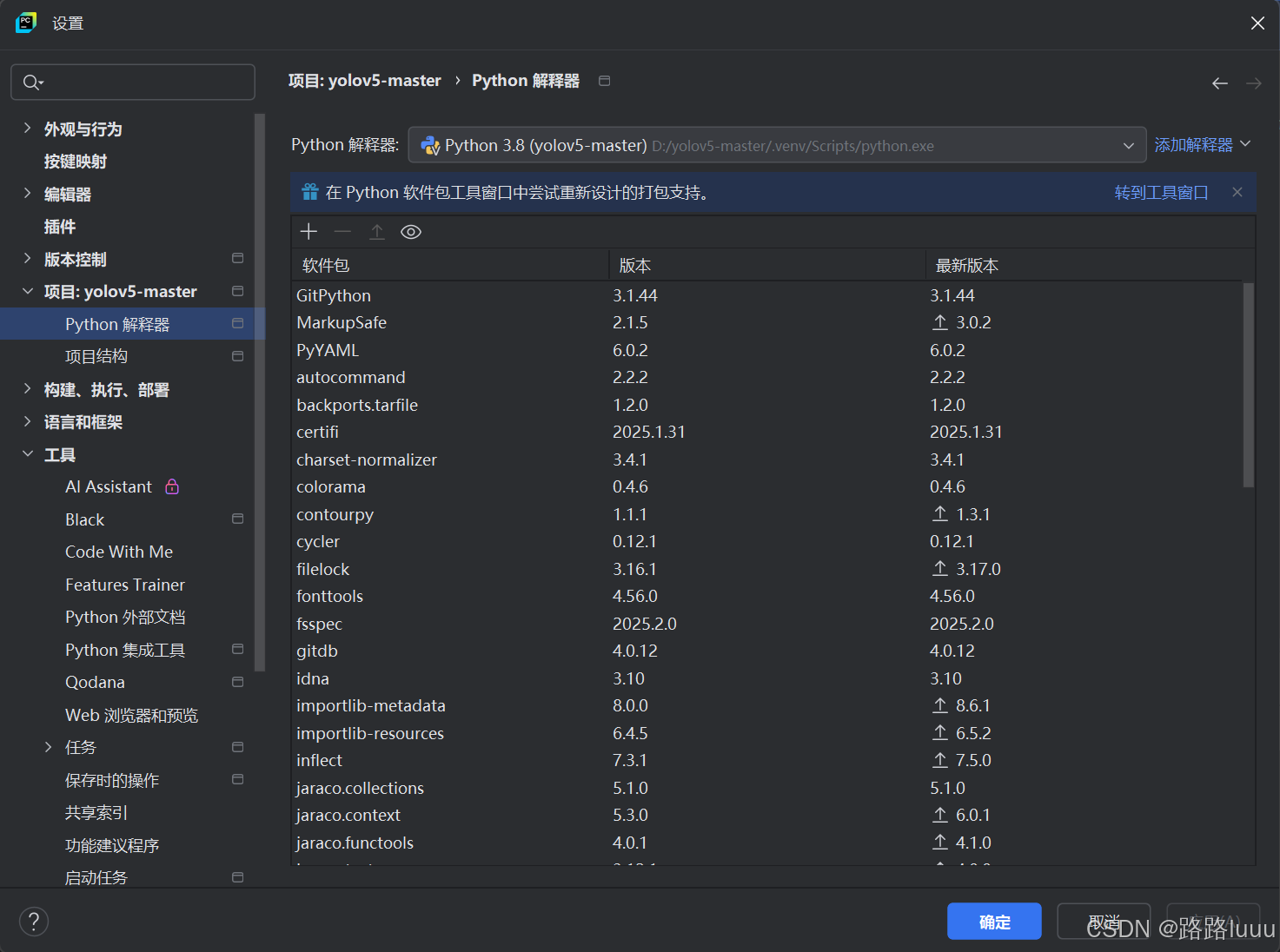
- 进入yolov5源码页面:https://github.com/ultralytics/yolov5?tab=readme-ov-file
选择yolov5s.pt,点击蓝字下载,并将其复制在yolov5的根目录(最内部的一个同名文件夹yolov5-master)里。
- 在yolov5的根目录(最内部的一个同名文件夹yolov5-master)里找到detect.py文件,用PyCharm打开,点击右上角绿色小三角运行代码。
- 被识别图片存储地址:D:\yolov5-master\yolov5-master\data\images
运行后识别结果存储地址:D:\yolov5-master\yolov5-master\runs\detect
运行结果:

(这基本上是我跟几个csdn大佬教程做下来的,经常因为某些步骤和我情况不符无法进行,形成了一个最终成功的步骤版本,记录一下。详细步骤图文站内大佬们都有。)

















 3330
3330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









