







目录
最近尝试部署了基于S3的存算分离集群,现对部署过程进行整理。
存算分离功能从3.0开始支持。
一.存算分离的优势
相对于早期的存算一体架构,存算分离有下面优势:
- 廉价且可无缝扩展的存储,有效降低存储成本。
- 弹性可扩展的计算能力。由于数据不存储在 CN 节点中,因此集群无需进行跨节点数据迁移或 Shuffle 即可完成扩缩容。
- 热数据的本地磁盘缓存,用以提高查询性能。
- 可选异步导入数据至对象存储,提高导入效率。
- 在查询命中缓存的情况下,存算分离集群的查询性能与存算一体集群性能一致。
存算分离的架构如下:
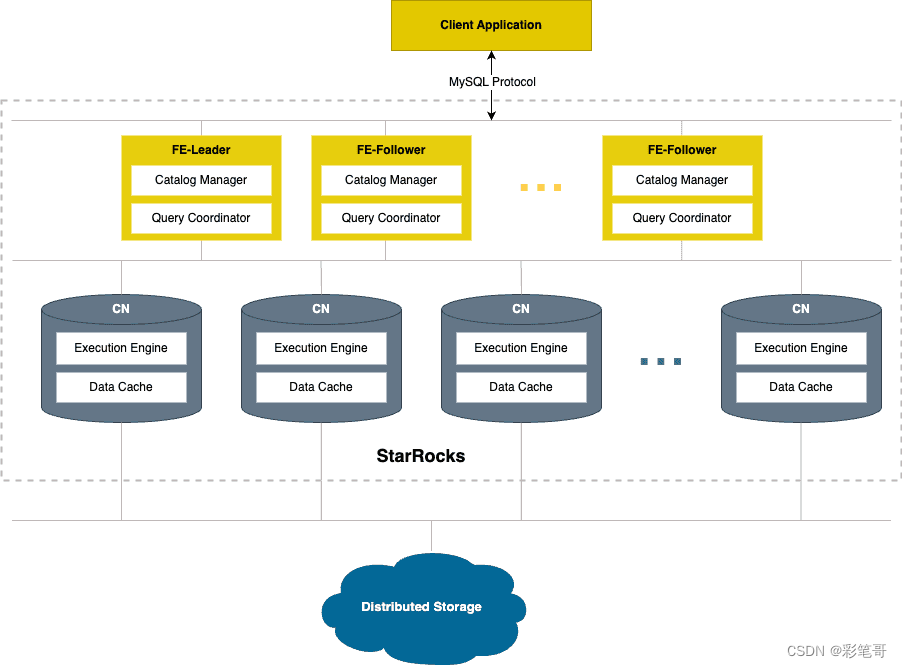
二.存算分离的安装和部署
存算分离的安装部署包扣FE和CN的部署,没有BE的部署,以下部署都以Starrocks的3.1.3版本为例。
集群运行环境的部署与存算一体的部署一样,主要是虚拟内存的关闭,防火墙的关闭等等;
1.S3环境的配置
由于是基于S3的存储部署,需先确保FE和CN对远程的S3环境是可以访问的,如果是AWS S3,可以使用IAM user-based方式通过aws访问S3,具体操作如下;
在安装了aws环境的节点上执行aws configure命令,按照提示配置相应的访问地址和账号密码等信息,通过aws命令查看和操作s3
查看s3目录下的文件:aws s3 --endpoint-url="S3环境的url地址" --no-verify-ssl ls
aws的相关命令很多,可以参考官方通过 AWS CLI 使用 API 级(s3api)命令 - AWS Command Line Interface
2.FE的部署
对于FE的配置,需要在fe.conf中添加以下配置信息
| # 是否存算分离模式 #shared_nothing(一体化存储,默认),shared_data(存算分离) run_mode = shared_data #云原生元数据服务监听端口。默认值:6090。 |


















 201
201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









