




朋友们、伙计们,我们又见面了,本期来给大家解读一下有关哈希和哈希桶的知识点,如果看完之后对你有一定的启发,那么请留下你的三连,祝大家心想事成!
C 语 言 专 栏:C语言:从入门到精通
数据结构专栏:数据结构
个 人 主 页 :stackY、
C + + 专 栏 :C++
Linux 专 栏 :Linux

目录
1. 哈希概念
顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素时,必须要经过关键码的多次比较。顺序查找时间复杂度为O(N),平衡树中为树的高度,即
,搜索的效率取决于搜索过程中元素的比较次数。
理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素。
如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立一 一映射的关系,那么在查找时通过该函数可以很快找到该元素。
2. 哈希表的插入
1. 直接定址法
根据所要插入的关键值在哈希表中所对应的存储位置建立起的一种一 一映射关系。
这种方法所适合的场景:数据范围集中,数据量较小。与存储位置的关系是一对一的关系,不存在哈希冲突。
2. 除留余数法
用所要插入的元素和哈希表的大小进行取模操作,这样就可以将大范围的数据缩小,根据对应关系存储在哈希表中。
这种方法所适合的场景:数据范围不集中,且数据量较多。
与存储位置的关系是多对一的关系,并且存在哈希冲突。
2.1 哈希冲突
我们经常使用除留余数法,但是会面临哈希冲突,那么什么是哈希冲突呢?
不同的关键值通过映射关系所得到的存储位置是一样的,这种情况被叫做哈希冲突或者哈希碰撞。
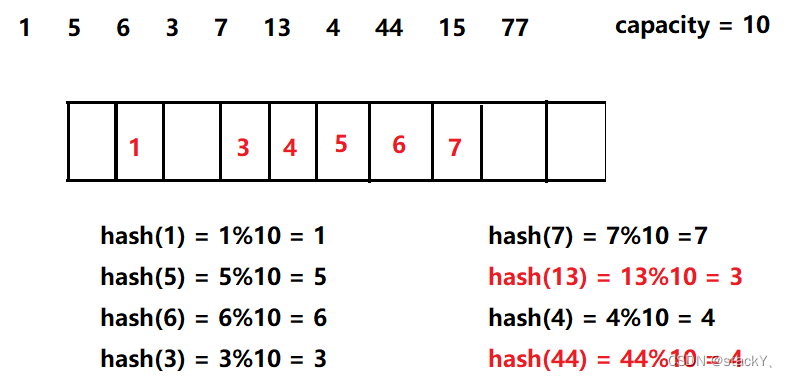
2.2 哈希冲突的解决
2.2.1 闭散列(开放定址法)
闭散列:也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去。
那如何寻找下一个空位置呢?
1. 线性探测从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
hashi + i (i >= 0)
2. 二次探测
从发生冲突的位置开始,依次向后探测,探测的距离是i的平方,直到寻找到下一个空位置为止。
hashi + i^2 (i >= 0)
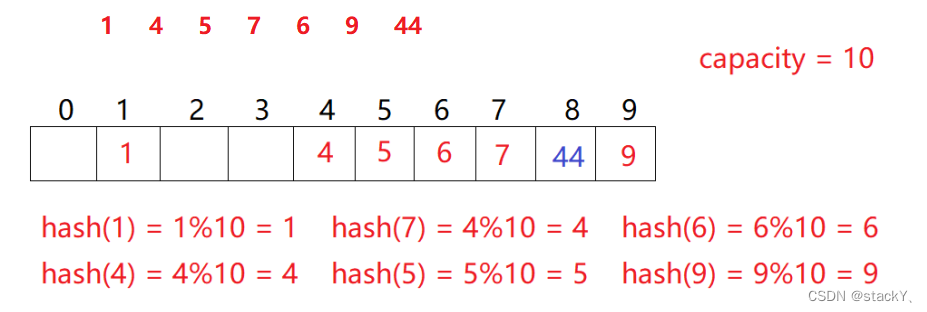
2.2.2 开散列 (哈希桶/拉链法)
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地
址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链
接起来,各链表的头结点存储在哈希表中。从上图可以看出,开散列中每个桶中放的都是发生哈希冲突的元素。
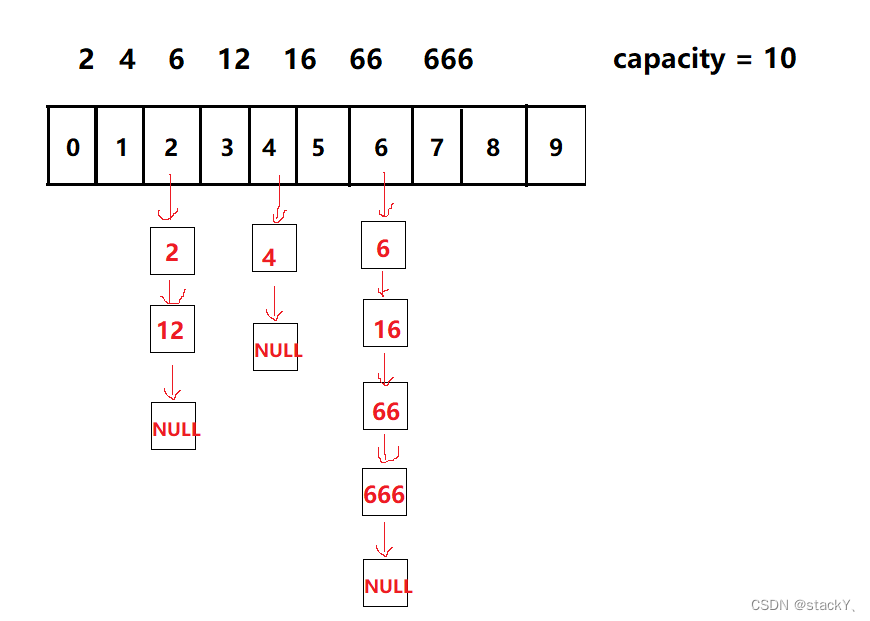
2.3 闭散列的代码实现
1. 基本构造
为了区分哈希表中的每一个位置值的情况,所以可以设置一个枚举状态值,这个节点的状态值包含:空、存在、删除。
我们采用Key_Value结构来实现哈希表
namespace open_address { //哈希节点状态 enum Status { EMPTY, //空 EXIST, //存在 DELETE //删除 }; //哈希节点 template<class K, class V> struct HashData { pair<K, V> _kv; Status _s; //哈希节点的状态 }; //哈希表 template<class K, class V> class HashTable { public: //构造 HashTable() { _tables.resize(10); //初始化先给10个空间 } private: vector<HashData<K, V>> _tables; // size_t _n = 0; //存储关键字的个数 }; }2. 查找
通过传递关键之key进行查找,返回该关键值的指针,查找的逻辑首先得用key与存储位置的映射关系进行查找,如果查找到了空还没有找到对应的关键值,那么就返回空,映射关系我们采用的是除留余数法。
那么为什么找到空就结束了呢?首先我们根据除留余数法找到key存储的位置,那么这个位置有可能是被哈希冲突所占用的位置,那么本该存储在这个位置的值就需要继续向后面找空位置填充上去,那么key这个值的前面的位置的状态都是存在,所以可以一直向后面找,直到为空就停止。
//查找 HashData<K, V>* Find(const K& key) { size_t hashi = key % _tables.size(); //找对应位置 //不为空继续查找 while (_tables[hashi]._s != EMPTY) { if (_tables[hashi]._s == EXIST &&_tables[hashi]._kv.first == key) //_kv.first存在且等于key表示找到了 { return &_tables[hashi]; } ++hashi; hashi %= _tables.size(); } return NULL; }3. 插入
插入首先需要查找要插入的key有没有在表中存在,若不存在既可以插入,若存在则不能插入。
插入我们采用除留余数法,用key与表的大小取模得到的映射关系,如果映射到的的位置的状态是存在,那么就需要继续向后面找空余的位置,如果映射到的位置的状态是删除或者空,那么就可以插入,如果映射到的位置后面的空间已满,那么就与表的大小取模,从最前面开始找空余位置。
//插入 bool Insert(const pair<K, V>& kv) { //先查找 if (Find(kv.first)) return false; //线性探测 size_t hashi = kv.first % _tables.size(); //找到对应的映射 while (_tables[hashi]._s == EXIST) { hashi++; //找到后面空着的位置 hashi %= _tables.size(); //形成一个圈 } _tables[hashi]._kv = kv; //插入 _tables[hashi]._s = EXIST; //修改状态 ++_n; //关键字个数++ return true; }
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2274
2274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











