






 本文深入解析卷积神经网络(CNN)在图像识别领域的应用,包括CNN的引入原因、工作原理及卷积过程,展示了CNN的架构组成,并通过Kaggle环境下的FashionMNIST数据集示例,介绍了使用TensorFlow构建CNN模型的方法。
本文深入解析卷积神经网络(CNN)在图像识别领域的应用,包括CNN的引入原因、工作原理及卷积过程,展示了CNN的架构组成,并通过Kaggle环境下的FashionMNIST数据集示例,介绍了使用TensorFlow构建CNN模型的方法。
1. CNN介绍
1.1 为什么引入CNN
CNN是一种主要用于图像识别的神经网络深度学习方法,当图片像素过大,例如为3000*3000时(当然这也太大了),在Keras中根本无法使用Dense层直接运算,因此需要引入CNN。简单的说:CNN在工作过程中提取图片边缘信息,丢弃掉剩余信息,使图片信息变小,更便于运算。
1.2 CNN工作方式
计算机通过寻找诸如边缘和曲线之类的低级特点来分类图片, 经过卷积层后构建出更抽象的概念。CNN采用了局部连接和权值共享,保持了网络的深层构架,同时又减少了网络参数,使模型具有较好的泛化能力的同时,又便于训练。
1.3 卷积过程
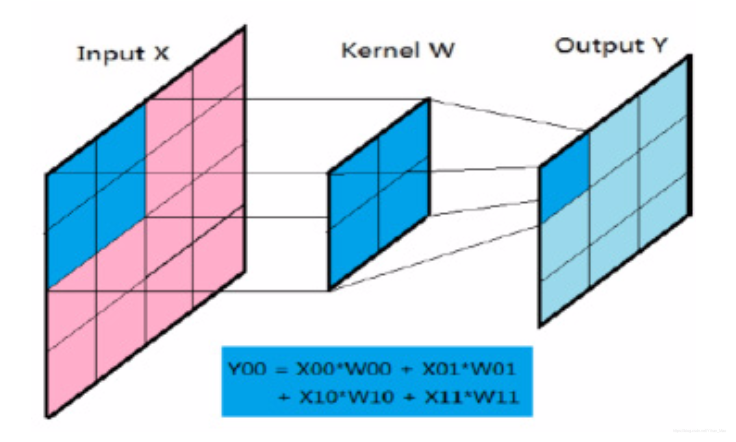
卷积过程有三个二维矩阵参与,它们分别为原图(inputX),卷积核(kernelW)和输出图(outputY)。卷积核覆盖在原图的一个局部面上,局部面对应神经元的输出乘以其对应位置的权重求和后赋值到输出图矩阵的对应位置。卷积核在原图中从左到右,自上而下,根据照卷积核的大小,按照我们设定的步长移动,直至完成整张图的卷积过程。卷积核的本质是神经元之间相互连接的权重,该权重被属于同一特征图的神经元共享。
2. CNN构架
- 卷积层 conv2d
- 非线性变化层 relu/sigmoid/tanh
- 池化层 pooling2d —— 降采样过程
- 全链接层 dense
2.1 构建CNN的Tensorflow API
(1)tf.layers.conv2D() 内置参数介绍
- filter:卷积核个数
- ksize:卷积核大小,一般设置为33或55
- strides:步长,默认为(1,1)。(2,2)表示多跨一步,此时所得图像会变小
- padding :边缘填充,不填充为’valid’,当无法整除卷积核时,图像会变小。
填充为 ‘same’,卷积核无法被整除时,边缘填充0进去。
3. 基于kaggle环境的CNN识别fashion mnist
基于Kaggle环境下
首先测试Kaggle环境下其GPU是否能用
if.test.is_gpu_available
输出为 true 则表示能用
再从Kaggle上加载数据集进来
fashion_mnist=keras.datasets.fashion_mnist
(train_images,train_lables),(test_images,test_labels)=fashion_mnist.load_data()
此时查看图片信息,发现有6000张28*28的训练图,6000张训练标签
扩展图片维度为4维
train_images=np.expand_dims(train_images,-1)
-1表示扩展图片的最后一列
CNN模型搭建
model=tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(32,(3*3),input_shape=train_images.shape[1:],activation='relu')) #图片第0维为张数,所以我们取出去第0维后的所有数据
model.add(tf.keras.layers.MaxPool2D()) #MaxPool可使图片缩小
model.add(tf.keras.layers.Conv2D(64,(3*3),activation='relu')
model.add(tf.keras.layers.GlobalAveragePooling2D()) #给数据做扁平化
model.add(tf.keras.layers.Dense(10,activation='softmax'))
编译、训练
model.compeil(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['acc'])
history=moedel.fit(train_images,train_labels,epochs=30,validation_data=(test_images,test_labels))
绘图
plt.plot(history.epoch.history.history.get('acc'),label='acc')
plt.plot(history.epoch.history.history.get('val_acc'),label='val_acc')
改天再把绘图结果贴出来,这个月翻墙买的流量用完了呜呜呜。。。
其实上述工作完成后,train数据的训练效果肯定是不好的,毕竟网络太简单而数据量又偏大。不过我们的设计网络的原则先设计直到它过拟合,再修改网络解决过拟合直到拟合优良。

















 2371
2371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









