




并行思想
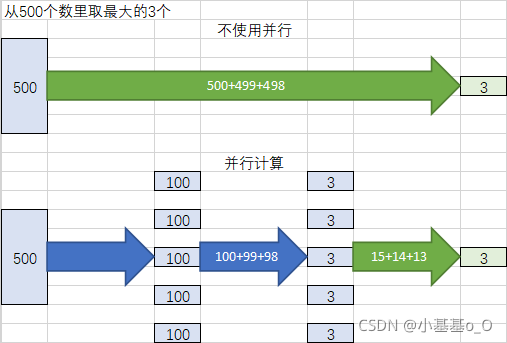
- 不使用并行,时间消耗约1500
- 使用并行,并行度设为5,把500切成5个100
分别从每个100找最大的3个,得到15个
从这15个里找最大的3个
时间消耗约300(≈5倍)
场景
从10亿用户中 获取 消费前5000的 用户ID
| uid | amount |
|---|---|
| 1 | 23.48 |
| 2 | 7888.33 |
| … | |
| 1000000000 | 367.55 |
错误方案
- 全局排序速度较慢
SELECT uid,amount FROM t ORDER BY amount DESC LIMIT 5000;
可行方案
- 按用户ID取余进行分区(此处设
40) - 分区内(并行)排序
- 筛选各分区topN
- 全局排序选取topN
WITH
-- 按用户ID取余进行分区(各分区并行排序)
t1 AS (
SELECT
uid,
amount,
RANK() OVER (PARTITION BY (uid % 40) ORDER BY amount DESC)r
FROM t
),
-- 筛选各分区topN
t2 AS (
SELECT uid,amount FROM t1 WHERE r <= 5000
)
-- 全局排序选取topN
SELECT uid,amount FROM t2 ORDER BY amount DESC LIMIT 5000;


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











