




文章目录
场景
购物蓝分析(market basket analysis):
在一个数据集中找出项之间的关系
例如,购买手机的顾客,有10%也买手机壳
关联算法
SparkSQL粗分析
大致原理
import org.apache.spark.sql.SparkSession
import org.apache.spark.{
SparkConf, SparkContext}
//创建SparkContext对象
val c0: SparkConf = new SparkConf().setAppName("a0").setMaster("local")
val sc: SparkContext = new SparkContext(c0)
//创建SparkSession对象
val c1: SparkConf = new SparkConf().setAppName("a1").setMaster("local")
val spark: SparkSession = SparkSession.builder().config(c1).getOrCreate()
//隐式转换支持
import spark.implicits._
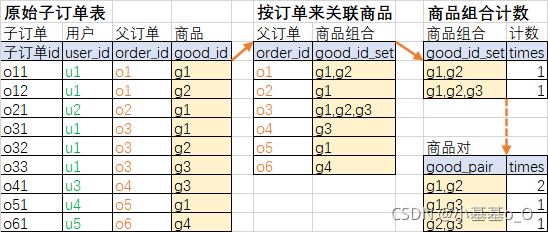
//原始子订单表
sc.makeRDD(Seq(
("u1", "o1", "g1"),
("u1", "o1", "g2"),
("u2", "o2", "g1"),
("u1", "o3", "g1"),
("u1", "o3", "g2"),
("u1", "o3", "g3"),
("u3", "o4", "g3"),
("u4", "o5", "g1"),
("u5", "o6", "g4"),
)).toDF("user_id", "order_id", "good_id").createTempView("t0")
//按订单关联
spark.sql(
"""
|SELECT COLLECT_SET(good_id)good_set FROM t0
|GROUP BY user_id
|HAVING SIZE(good_set) > 1
|""".stripMargin).createTempView("t1")
spark.sql(
"""
|SELECT good_set,count(good_set)c FROM t1
|GROUP BY good_set
|ORDER BY c DESC
|""".stripMargin).show
SQL计算结果略为粗糙
共现频数
大致原理
import org.apache.spark.sql.SparkSession
import org.apache.spark.{
SparkConf, SparkContext}
//创建SparkContext对象
val c0: SparkConf = new SparkConf().setAppName("a0").setMaster("local")
val sc: SparkContext = new SparkContext(c0)
//创建SparkSession对象
val c1: SparkConf = new SparkConf().setAppName("a1").setMaster("local")
val spark: SparkSession = SparkSession.builder().config(c1).getOrCreate()
//隐式转换支持
import spark.implicits._
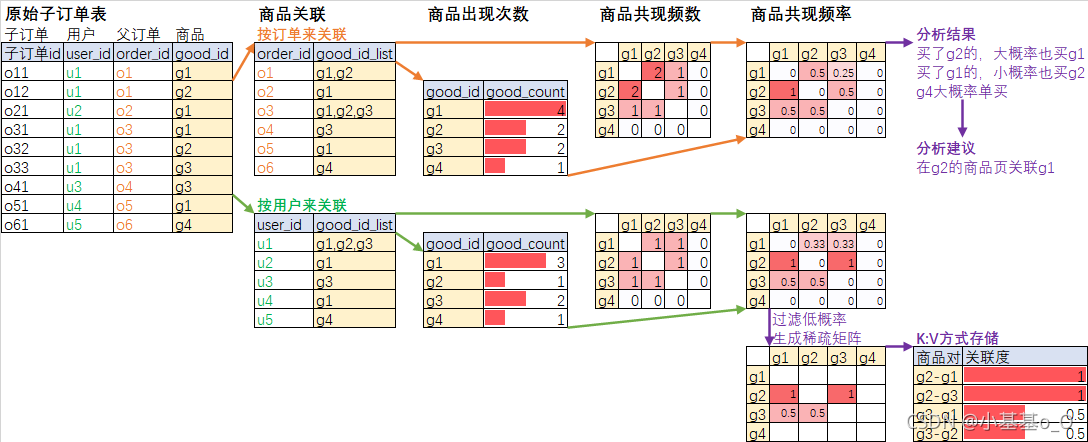
//子订单表(模拟HIVE:SELECT order_id,good_id FROM dwd_order_detail)
sc.makeRDD(Seq(
("o1", "g1"),
("o1", "g2"),
("o2", "g1"),
("o3", "g1"),
("o3", "g2"),
("o3", "g3"),
("o4", "g3"),
("o5", "g1"),
("o6", "g4"),
)).toDF("order_id", "good_id").createTempView("dwd_order_detail")
//按订单关联商品
val df = spark.sql(
"""
|SELECT COLLECT_SET(good_id) FROM dwd_order_detail
|GROUP BY order_id
|""".stripMargin).toDF("items") //下面模型默认输入列名叫items
df.show
/*
+------------+
| items|
+------------+
| [g3]|
| [g4]|
| [g2, g1]|
|[g2, g3, g1]|
| [g1]|
| [g1]|
+------------+
*/
//共现频数模型
import org.apache.spark.ml.fpm.FPGrowth
val fpGrowth = new FPGrowth().setMinSupport(0).setMinConfidence(0)
val model = fpGrowth.fit(df)
println(model)
/*
FPGrowthModel: uid=fpgrowth_352773cafc93, numTrainingRecords=6
*/
//商品共现频数
model.freqItemsets.show
/*
+------------+----+
| items|freq|
+------------+----+
| [g1]| 4|
| [g2]| 2|
| [g2, g1]| 2|
| [g3]| 2|
| [g3, g2]| 1|
|[g3, g2, g1]| 1|
| [g3, g1]| 1|
| [g4]| 1|
+------------+----+
*/
//商品关联规则
model.associationRules.show
/*
+----------+----------+----------+----+
|antecedent|consequent|confidence|lift|
+----------+----------+----------+----+
| [g3, g1]| [g2]| 1.0| 3.0|
| [g2]| [g1]| 1.0| 1.5|
| [g2]| [g3]| 0.5| 1.5|
| [g2, g1]| [g3]| 0.5| 1.5|
| [g3, g2]| [g1]| 1.0| 1.5|
| [g1]| [g2]| 0.5| 1.5|
| [g1]| [g3]| 0.25|0.75|
| [g3]| [g2]| 0.5| 1.5|
| [g3]| [g1]| 0.5|0.75|
+----------+----------+----------+----+
*/
//预测
model.transform(Seq(
"g1",
"g2",
"g3",
"g4",
"g1 g2",
"g1 g3",
"g2 g3",
).map(_.split(" ")).toDF("items")).show
/*
+--------+----------+
| items|prediction|
+- 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1073
1073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











