




 该博客介绍了如何利用Spark与Phoenix对HBase进行操作,包括创建Phoenix表用于统计每小时用户数,配置HBase及Spark依赖,通过SparkContext写入数据到HBase,以及使用SparkSession读取并展示数据。源码展示了HBaseConfiguration.create方法创建配置的过程,以及phoenixTableAsDataFrame方法将Phoenix表转换为DataFrame。
该博客介绍了如何利用Spark与Phoenix对HBase进行操作,包括创建Phoenix表用于统计每小时用户数,配置HBase及Spark依赖,通过SparkContext写入数据到HBase,以及使用SparkSession读取并展示数据。源码展示了HBaseConfiguration.create方法创建配置的过程,以及phoenixTableAsDataFrame方法将Phoenix表转换为DataFrame。
Phoenix建表
使用Phoenix对HBase建表,用于统计每小时用户数
create table uv_hour (
uid varchar,
ymdh varchar
constraint primary_key primary key (uid,ymdh)
);
依赖
<properties>
<spark.version>3.0.3</spark.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-spark</artifactId>
<version>5.0.0-HBase-2.0</version>
<exclusions>
<exclusion>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
写
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.hadoop.hbase.HBaseConfiguration // HBase配置
import org.apache.phoenix.spark._ // 隐式转换支持:saveToPhoenix
// 创建SparkContext对象
val conf = new SparkConf().setAppName("A0").setMaster("local[2]")
val sc = new SparkContext(conf)
// 创建RDD
val rdd = sc.makeRDD(Seq(
("u1", "2021-08-08 09"),
("u2", "2021-08-08 09"),
("u1", "2021-08-08 10"),
))
// 存HBase之Phoenix表
rdd.saveToPhoenix(
"UV_HOUR", // 表名
Seq("UID", "YMDH"), // 字段名
HBaseConfiguration.create(), // HBase配置
Some("hadoop102:2181") // ZooKeeper的URL
)
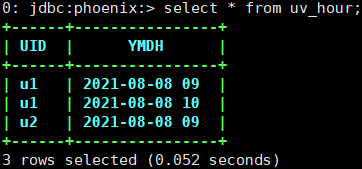
sqlline.py查看测试结果
源码截取:HBaseConfiguration.create
使用create方法创建HBase配置
public staticConfiguration create() {
Configuration conf = new Configuration();
// In case HBaseConfiguration is loaded from a different classloader than
// Configuration, conf needs to be set with appropriate class loader to resolve
// HBase resources.
conf.setClassLoader(HBaseConfiguration.class.getClassLoader());
return addHbaseResources(conf);
}
自动获取hbase-default.xml和hbase-site.xml配置文件信息
public static Configuration addHbaseResources(Configuration conf) {
conf.addResource("hbase-default.xml");
conf.addResource("hbase-site.xml");
checkDefaultsVersion(conf);
return conf;
}
读
import org.apache.spark.sql.SparkSession
import org.apache.phoenix.spark.toSparkSqlContextFunctions
val spark = SparkSession
.builder()
.appName("phoenix-test")
.master("local[2]")
.getOrCreate()
// 读HBase之Phoenix表
spark.sqlContext.phoenixTableAsDataFrame(
table = "UV_HOUR",
columns = Seq("UID", "YMDH"),
predicate = Some("UID='u1'"),
zkUrl = Some("hadoop102:2181"),
).show()
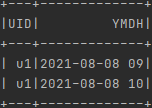
打印结果
源码截取:phoenixTableAsDataFrame
import org.apache.hadoop.conf.Configuration
import org.apache.spark.sql.{DataFrame, SQLContext}
class SparkSqlContextFunctions(@transient val sqlContext: SQLContext) extends Serializable {
/*
This will return a Spark DataFrame, with Phoenix types converted Spark SQL catalyst types
'table' is the corresponding Phoenix table
'columns' is a sequence of of columns to query
'predicate' is a set of statements to go after a WHERE clause, e.g. "TID = 123"
'zkUrl' is an optional Zookeeper URL to use to connect to Phoenix
'conf' is a Hadoop Configuration object. If zkUrl is not set, the "hbase.zookeeper.quorum"
property will be used
*/
def phoenixTableAsDataFrame(table: String, columns: Seq[String],
predicate: Option[String] = None,
zkUrl: Option[String] = None,
tenantId: Option[String] = None,
conf: Configuration = new Configuration): DataFrame = {
// Create the PhoenixRDD and convert it to a DataFrame
new PhoenixRDD(sqlContext.sparkContext, table, columns, predicate, zkUrl, conf, tenantId = tenantId)
.toDataFrame(sqlContext)
}
}


















 1270
1270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











