




 本文详细介绍了Apache Kafka 2.7.0的安装步骤,包括解压、配置、集群分发、启动停止等,并讲解了Kafka的基本概念如生产者、消费者、分区等。此外,还提供了创建、查看、修改和删除主题的命令。最后,更新了Kafka 3.0的集群部署流程,包括环境变量设置、解压、配置和启动操作。
本文详细介绍了Apache Kafka 2.7.0的安装步骤,包括解压、配置、集群分发、启动停止等,并讲解了Kafka的基本概念如生产者、消费者、分区等。此外,还提供了创建、查看、修改和删除主题的命令。最后,更新了Kafka 3.0的集群部署流程,包括环境变量设置、解压、配置和启动操作。
型英帅靓正嘅目录
概述
- Kafka:基于发布/订阅模式的 分布式的 消息队列
- 主用场景:大数据实时处理、流量削峰、实时数仓
- 官方教学:http://kafka.apache.org/documentation/
基础架构
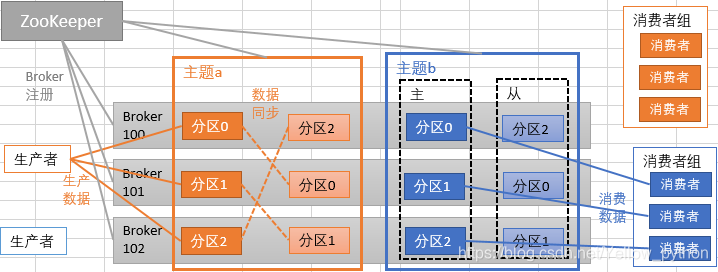
| 英文名 | 译名 | 说明 |
|---|---|---|
| Producer | 生产者 | 生产消息 |
| Consumer | 消费者 | 消费消息 |
| Consumer Group | 消费者组 | 由多个Consumer组成 是逻辑上的一个订阅者 |
| Broker | 经纪人 | 一台kafka服务器就是一个Broker 一个集群由多个Broker组成 一个Broker可以容纳多个topic的partition |
| Topic | 主题 | 可以理解为一个存放消息的逻辑上的队列 一个topic可以分布到多个Broker |
| Partition | 分区 | 一个topic可以分存多个partition 每个partition是一个有序的队列 |
| Replica | 复制品 | 数据副本 |
| Leader | 首领 | 对接生产者和消费者 |
| Follower | 追随者 | 实时同步leader的数据 leader故障时,某follower会成为新的leader |
Kafka2.7.0安装
| 集群规划 | 服务名 | hadoop100 | hadoop101 | hadoop102 |
|---|---|---|---|---|
| ZooKeeper | QuorumPeerMain | 1 | 1 | 1 |
| Kafka | Kafka | 1 | 1 | 1 |
1、解压、改名
tar -zxf kafka_2.13-2.7.0.tgz -C /opt/
cd /opt/
mv kafka_2.13-2.7.0 kafka
ll
2、主要配置
| 版块 | 参数 | 说明 |
|---|---|---|
| 服务器基础 | broker.id | broker 编号,唯一的,每台机都不同 |
| 服务器基础 | delete.topic.enable | 是否允许删主题 (旧版默认false,新版默认true,所以本文不配置) |
| 套接字 | num.network.threads | 处理网络请求的线程数 |
| 套接字 | num.io.threads | 处理磁盘IO的线程数 |
| 套接字 | socket.send.buffer.bytes | 发送套接字的缓冲区字节数 |
| 套接字 | socket.receive.buffer.bytes | 接收套接字的缓冲区字节数 |
| 套接字 | socket.request.max.bytes | 套接字接收请求的最大字节数 |
| 日志 | log.dirs | 日志存放的路径 |
| 日志 | num.partitions | 每个主题的默认分区数 |
| 日志 | num.recovery.threads.per.data.dir | 每个数据目录 启动时日志恢复 和 关闭时刷新 的线程数 |
| 日志保留 | log.retention.hours | 基于时间的日志保留策略(小时) |
| 日志保留 | log.retention.bytes | 基于大小的日志保留策略(字节) |
| 日志存储 | log.segment.bytes | 日志片段最大字节数 |
| 日志保留 | log.retention.check.interval.ms | 检查日志片段的周期(毫秒) |
| ZooKeeper | zookeeper.connect | Zookeeper集群地址(逗号分隔) |
delete.topic.enable旧版有新版没,已经默认允许删主题,所以此处不用配- 本文只配
log.dirs(60行)和zookeeper.connect(123行)
vi $KAFKA_HOME/config/server.properties
log.dirs=/opt/kafka/logs
zookeeper.connect=hadoop100:2181,hadoop101:2181,hadoop102:2181/kafka
mkdir $KAFKA_HOME/logs
细节:
/kafka表示在ZooKeeper集群根目录下创建名为kafka的节点,后续节点会在这个/kafka下创建
3、文件分发
rsync -a $KAFKA_HOME/ hadoop101:$KAFKA_HOME/
rsync -a $KAFKA_HOME/ hadoop102:$KAFKA_HOME/
然后修改每台机(貌似不能直接用
ssh+vi)的broker.id,此处分别设为【100、101、102】
vi $KAFKA_HOME/config/server.properties
4、集群启停
先启动ZooKeeper集群,再启动Kafka集群
kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
ssh hadoop101 "kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties"
ssh hadoop102 "kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties"
kafka-server-stop.sh
ssh hadoop101 "kafka-server-stop.sh"
ssh hadoop102 "kafka-server-stop.sh"
5、群起脚本
https://blog.youkuaiyun.com/Yellow_python/article/details/115862167
Kafka命令
| 参数 | 说明 | 备注 |
|---|---|---|
--topic | 主题名称 | |
--replication-factor | 副本数 | |
--partitions | 分区数 | |
--zookeeper | ZooKeeper集群地址 | 正在弃用 |
--bootstrap-server | 和--zookeeper类似,指Kafka集群地址 | 建议使用 |
1、创建主题
kafka-topics.sh --create \
--zookeeper ZK地址:2181/kafka \
--replication-factor 副本数 \
--partitions 分区数 \
--topic 主题名称
2、查看有哪些主题
kafka-topics.sh --zookeeper ZK地址:2181/kafka --list
3、查看某主题的描述(附图!)
kafka-topics.sh --describe \
--zookeeper ZK地址:2181/kafka \
--topic 主题名称

4、生产和消费
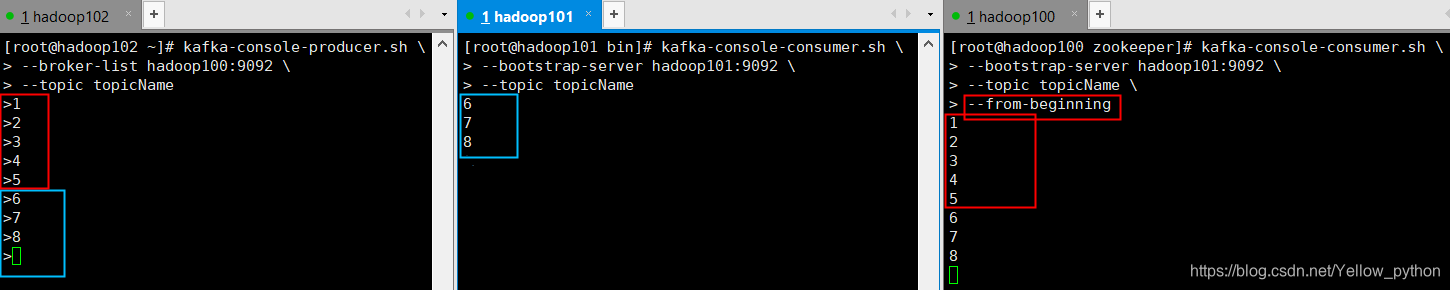
4.1、生产
kafka-console-producer.sh \
--broker-list Kafka地址:9092 \
--topic 主题名称
4.2、消费
--from-beginning会把主题以往所有数据都读取出来--group指定消费者组
kafka-console-consumer.sh \
--bootstrap-server Kafka地址:9092 \
--topic 主题名称 \
--from-beginning \
--group 消费者组名称
5、使 Leader 负载均衡
kafka-preferred-replica-election.sh --zookeeper ZK地址:2181/kafka
6、修改主题(增大分区数)
可以增大分区数,不能减少
kafka-topics.sh --zookeeper ZK地址:2181/kafka --alter --topic 主题名 --partitions 6
7、删除主题
kafka-topics.sh --delete \
--zookeeper ZK地址:2181/kafka \
--topic 主题名
8、消费者组 的查看和删除
查看消费者组
kafka-consumer-groups.sh \
--describe \
--all-groups \
-all-topics \
--bootstrap-server hadoop102:9092
--delete --group删除消费者组
kafka-consumer-groups.sh \
--delete --group G1 \
--bootstrap-server hadoop102:9092
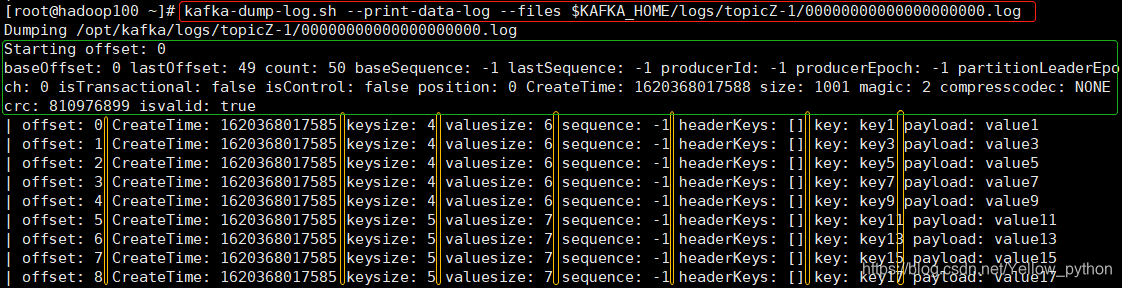
9、查看生产的内容
查看消息内容
kafka-dump-log.sh \
--print-data-log \
--files $KAFKA_HOME/logs/主题名-分区号/片段偏移量.log
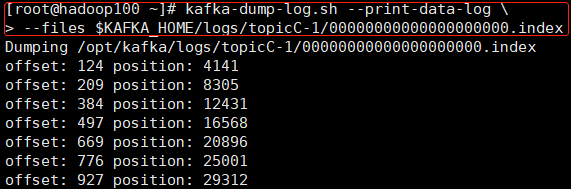
查看索引
kafka-dump-log.sh \
--print-data-log \
--files $KAFKA_HOME/logs/主题名-分区号/片段偏移量.index
查看消息内容
查看索引
新增:Kafka3版本集群部署
1、环境变量
# Kafka
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
2、解压
tar -zxvf kafka_2.12-3.0.0.tgz
mv kafka_2.12-3.0.0 $KAFKA_HOME
3、配置
cd $KAFKA_HOME/config/
vim server.properties
修改内容(其中broker.id每台不一样)
broker.id=0
log.dirs=/opt/module/kafka/datas
zookeeper.connect=hadoop105:2181,hadoop106:2181,hadoop107:2181/kafka
4、分发,分发后修改每台机的broker.id
rsync.py $KAFKA_HOME
5、先启动ZooKeeper集群,然后每台机启动Kafka
kafka-server-start.sh -daemon config/server.properties
6、创建主题
kafka-topics.sh --bootstrap-server hadoop105:9092 \
--create --partitions 3 --replication-factor 1 --topic temp01
7、查看主题列表
kafka-topics.sh --bootstrap-server hadoop105:9092 --list
8、生产
kafka-console-producer.sh --bootstrap-server hadoop105:9092 --topic temp01
9、消费
kafka-console-consumer.sh --bootstrap-server hadoop105:9092 --topic temp01


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











