






一开始我想着使用dfs进行处理(dp的话还是比较难想的)
在进行了记忆化搜索和剪枝之后:
#include<stdio.h>
#include<stdlib.h>
struct node{
int p,t;
}task[10005];
int book[10005];//记忆化搜索
int max=0;
int n,k;
int maxt(int x,int y){
return x>y?x:y;
}
int cmp(const void*a,const void* b){
struct node*ta=(struct node*)a;
struct node*tb=(struct node*)b;
if(ta->p==tb->p)return ta->t-tb->t;//任务时间短的放前面
else return ta->p-tb->p;//任务开始时间小的放前面
}
void dfs(int time,int rest){
int flag=0;
if(time==n+1){
max=maxt(max,rest);
return ;
}
if(rest<=book[time]&&rest>0) return ;//休息时间比之前还要少,直接返回(没必要继续)
book[time]=rest;//更大,进行更新
for(int i=0;i<k;i++){
if(task[i].p<time) continue;//小了,往后搜索
if(task[i].p>time) break;//大了,跳出循环
flag=1;//标记是否有该时间点的任务
dfs(time+task[i].t,rest);//到达下一个可能休息的时间点
}
if(!flag)
dfs(time+1,rest+1);//没任务
return ;
}
int main(){
scanf("%d%d",&n,&k);
for(int i=0;i<k;i++){
scanf("%d%d",&task[i].p,&task[i].t);
}
qsort(task,k,sizeof(struct node),cmp);//排序,方便查找
dfs(1,0);
printf("%d",max);
}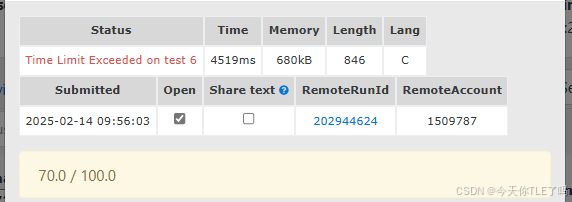
fs的优化对于我来说已经是到头了,但是数据太大,导致dfs时间复杂度增大,无法处理
上DP
定义dp【i】の含义:i时间点到达工作时间末尾能
休息的最长时间(和数字三角形类似进行倒推——“用未来影响过去”)
处理dp【】:
for(int i=n,p=k-1;i>=1;i--){
if(a[p].s!=i){dp[i]=dp[i+1]+1;continue;}//没有任务,休息时间增加,直接进行下一个循环,从后往前推
for(;a[p].s==i;p--){//有任务,从后往前推任务起始时间为i的任务(输入的数据已经是有顺序的了)
dp[i]=max(dp[i],dp[i+a[p].t]);//如果做完任务之后休息时间变长,执行任务
//休息时间和完成任务之后进行的休息时间取较大的值继续往前推
}
}完整代码:
#include<stdio.h>
struct node{
int s,t;
}a[100005];
int max(int x,int y){
return x>y?x:y;
}
int dp[100005];
int main(){
int n,k;
scanf("%d%d",&n,&k);
for(int i=0;i<k;i++){
scanf("%d%d",&a[i].s,&a[i].t);
}
for(int i=n,p=k-1;i>=1;i--){
if(a[p].s!=i){dp[i]=dp[i+1]+1;continue;}//没有任务,从后往前推
for(;a[p].s==i;p--){//有任务,从后往前推任务起始时间为i的任务
dp[i]=max(dp[i],dp[i+a[p].t]);//如果做完任务之后休息时间变长,执行任务
//休息时间和完成任务之后进行的休息时间取较大的值继续往前推
}
}
printf("%d",dp[1]);
}

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









