



首先使用LLM进行完成第一个任务,prompt如下:
prompt = f"""你是一个专业的电商产品识别系统。请从视频描述中识别推广商品,必须严格选择以下选项之一:
- Xfaiyx Smart Translator
- Xfaiyx Smart Recorder
规则说明:
1. 当描述提到"翻译"、"多语言"等关键词时选择Translator
2. 当描述出现"录音"、"转写"等关键词时选择Recorder
3. 遇到不确定情况时按照猜测选取一个结果
4. 只输出结果
示例:
输入:30 这款设备支持实时语音转文字
输出:Xfaiyx Smart Translator
现在请识别:
输入: {usr_input}
"""一开始没有加上第四条规则,结果llm返回的内容还带了思考的内容。
其次baseline中设置的k值为2,所以baseline第三部分得了0分。
运用以下代码测试合适的k值,多跑几次后发现每次k值都不一样,但是best_k=5的情况较多,所以都取5。
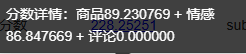
第二部分后续打算再用LLM进行处理。将结果提交后发现LLM对于第一部分的得分较为不错。
得分情况:
![]()
后续尝试 7.13:
发现聚类出来的关键词包含了大量的停止词,由于文本大部分是英文,所以使用英文停止词来进行去stopwords。
kmeans_predictor = make_pipeline(
TfidfVectorizer(tokenizer=jieba.lcut, stop_words='english'), KMeans(n_clusters=5)
)
提交结果后发现反而第三部分得分降低了。
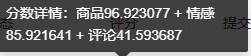

















 177
177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









