




 该文章介绍了如何在SparkSQL中使用窗口函数lead来获取每个商品的下一个日期,然后通过自定义函数或split结合explode方法生成日期序列,以填补日期间的空白,确保每天都有商品价格记录。
该文章介绍了如何在SparkSQL中使用窗口函数lead来获取每个商品的下一个日期,然后通过自定义函数或split结合explode方法生成日期序列,以填补日期间的空白,确保每天都有商品价格记录。
问题:
补充缺失日期,其他数值,按照上一个有值的数据补充
表结构
sku_name string 商品名称
dt 日期
sku_amount 商品价格
表数据
sc.makeRDD(Seq(
("iphone", "2023-02-03", 100),
("iphone", "2023-02-05", 300),
("iphone", "2023-02-08", 150),
("mac", "2023-02-01", 200),
("mac", "2023-02-02", 400),
("mac", "2023-02-06", 700),
("airpods", "2023-02-02", 300),
("airpods", "2023-02-04", 200),
("airpods", "2023-02-07", 100),
("airpods", "2023-02-11", 400)
)).toDF("sku_name", "dt", "sku_amount").createOrReplaceTempView("product")期望输出
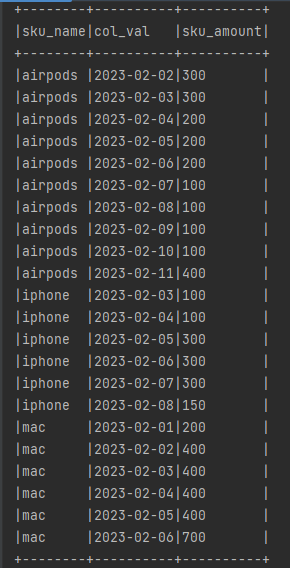
思路
1:利用窗口函数lead,补充同一组的下一个日期
2:根据当前的日期和和补充的下一个日期,利用space/split等函数构建posexplde数据展开
3:利用date_add函数和posexplode函数展开的索引获取相应日期,且把本行的amount数据补充上
spark.sql(
"""
|select
| sku_name,
| date_add(dt,col_idx) dt,
| sku_amount
|from
|(
| select
| sku_name,
| dt,
| sku_amount,
| lead(dt,1,dt) over(partition by sku_name order by dt) next_dt
| from
| product ) tmp
| lateral view posexplode (
| split (space( datediff(next_dt, dt)), ' (?!$)')
|) tbl_idx AS col_idx,col_val;
|""".stripMargin).show(100, false)拓展
基于以上思路,有时候使用posexplode,space有时候不好理解,简单补充一下思路
利用窗口函数lead,补充同一组的下一个日期
直接使用自定义函数,将dt到next_dt函数补齐就好
def splitDateFun(startDay:String,endDay:String) = {
//含头不含尾的buffer
val buffer = new ArrayBuffer[String]()
val sdf = new SimpleDateFormat("yyyy-MM-dd")
val startDate = sdf.parse(startDay)
val endDate = sdf.parse(endDay)
val calBegin = Calendar.getInstance()
calBegin.setTime(startDate)
buffer += startDay
while (endDate.after(calBegin.getTime)){
calBegin.add(Calendar.DAY_OF_MONTH,1)
val curr = sdf.format(calBegin.getTime)
if(!curr.equals(endDay)){
buffer += curr
}
}
buffer
}
spark.udf.register("spalitdatefun",splitDateFun _)
spark.sql(
"""
|select
|sku_name,
|col_val,
|sku_amount
|from
|(
| select
| sku_name,
| dt,
| sku_amount,
| lead(dt,1,dt) over(partition by sku_name order by dt) next_dt
| from
| product ) tmp
| lateral view explode (
| spalitdatefun(dt,next_dt)
|) tbl_idx AS col_val;
|""".stripMargin).show(100, false)完整代码
import org.apache.spark.sql.SparkSession
import java.text.SimpleDateFormat
import java.util.Calendar
import scala.collection.mutable.ArrayBuffer
object Test1 {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName("SparkSessionTest")
.master("local")
.getOrCreate()
val sc = spark.sparkContext
import spark.implicits._
sc.makeRDD(Seq(
("iphone", "2023-02-03", 100),
("iphone", "2023-02-05", 300),
("iphone", "2023-02-08", 150),
("mac", "2023-02-01", 200),
("mac", "2023-02-02", 400),
("mac", "2023-02-06", 700),
("airpods", "2023-02-02", 300),
("airpods", "2023-02-04", 200),
("airpods", "2023-02-07", 100),
("airpods", "2023-02-11", 400)
)).toDF("sku_name", "dt", "sku_amount").createOrReplaceTempView("product")
spark.sql(
"""
|select
| sku_name,
| date_add(dt,col_idx) dt,
| sku_amount
|from
|(
| select
| sku_name,
| dt,
| sku_amount,
| lead(dt,1,dt) over(partition by sku_name order by dt) next_dt
| from
| product ) tmp
| lateral view posexplode (
| split (space( datediff(next_dt, dt)), ' (?!$)')
|) tbl_idx AS col_idx,col_val;
|""".stripMargin).show(100, false)
spark.udf.register("spalitdatefun",splitDateFun _)
spark.sql(
"""
|select
|sku_name,
|col_val,
|sku_amount
|from
|(
| select
| sku_name,
| dt,
| sku_amount,
| lead(dt,1,dt) over(partition by sku_name order by dt) next_dt
| from
| product ) tmp
| lateral view explode (
| spalitdatefun(dt,next_dt)
|) tbl_idx AS col_val;
|""".stripMargin).show(100, false)
sc.stop()
spark.stop()
}
def splitDateFun(startDay:String,endDay:String) = {
//含头不含尾的buffer
val buffer = new ArrayBuffer[String]()
val sdf = new SimpleDateFormat("yyyy-MM-dd")
val startDate = sdf.parse(startDay)
val endDate = sdf.parse(endDay)
val calBegin = Calendar.getInstance()
calBegin.setTime(startDate)
buffer += startDay
while (endDate.after(calBegin.getTime)){
calBegin.add(Calendar.DAY_OF_MONTH,1)
val curr = sdf.format(calBegin.getTime)
if(!curr.equals(endDay)){
buffer += curr
}
}
buffer
}
}
















 4305
4305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









