







前言
今天我要给大家揭秘一个超级有趣的‘声音魔法’——GPT-SoVITS!这款由花儿不哭大佬精心打造的语音克隆工具,在GitHub上已经收获了超35K颗星星,绝对算得上是声音界的明星产品了。你可能要问:这东西会不会很难用啊?错啦!GPT-SoVITS V2版不仅支持中、日、英、韩、粤五种语言,还增加了许多实用功能,比如语速调节和无参考文本模式。最棒的是,它为Windows用户准备了整合包,下载解压就能轻松上手。不过,假如你只有一台性能强劲的电脑,并且希望在外出时也能随心所欲地使用这个项目怎么办?别急!有了cpolar这位‘内网穿越大师’的帮助,这一切都不再是难题。下面就跟着我一起来解锁这项酷炫技能吧!
1.GPT-SoVITS V2下载
本例演示环境为Windows11专业版,8G显卡,16G内存。
首先,我们需要在下面的地址下载GPT-SoVITS V2的Windows整合包:
https://www.yuque.com/baicaigongchang1145haoyuangong/ib3g1e/dkxgpiy9zb96hob4#KTvnO
大佬提供了多种下载方式:
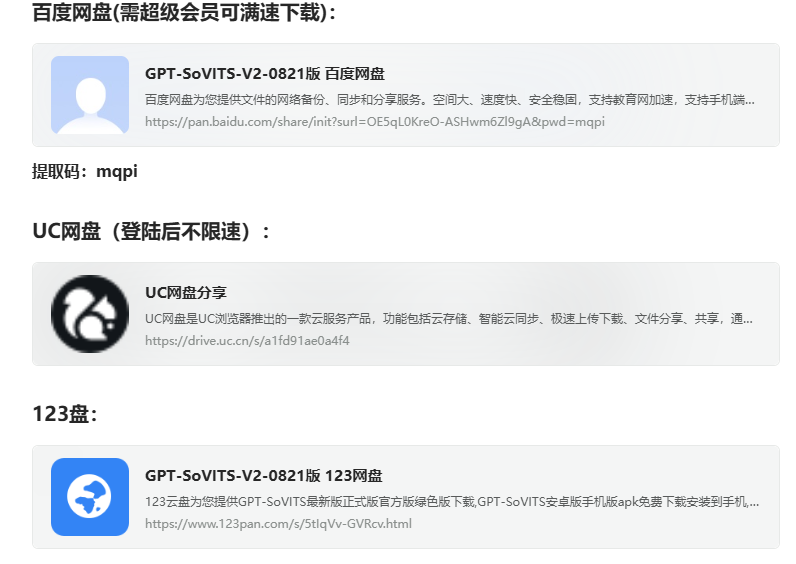
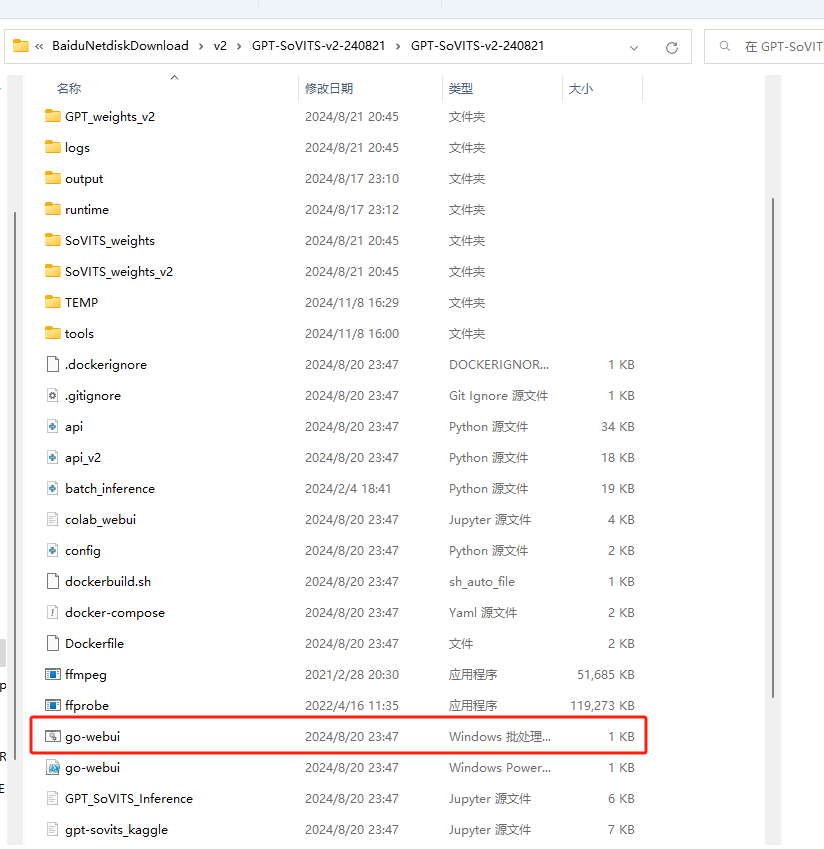
我这里下载的是V2版本,下载好后,解压缩后得到GPT-SoVITS-v2-240821文件夹。
2.本地运行GPT-SoVITS V2
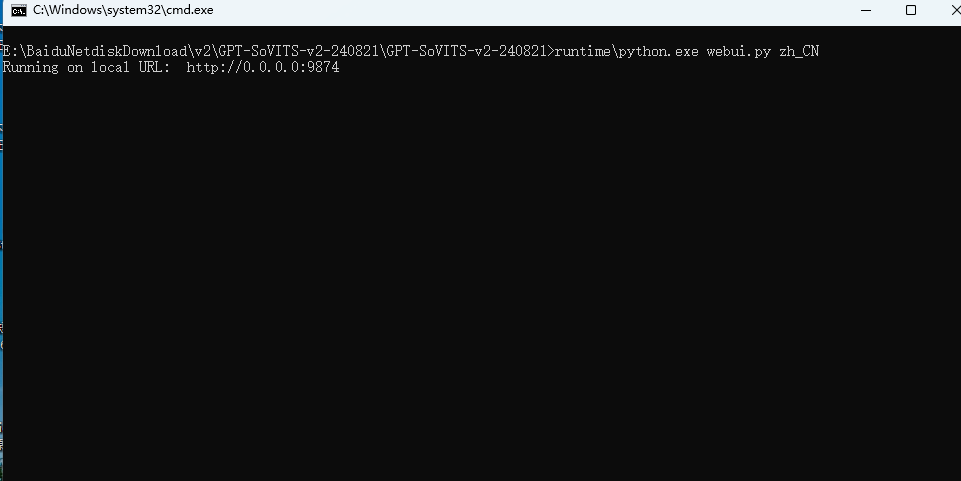
打开 GPT-SoVITS-v2-240821 文件夹,双击名为go-webui的bat格式文件即可启动服务:
服务启动后会弹出一个cmd终端窗口,然后会在浏览器中打开GPT-SoVITS V2的webui网页页面,我们接下来可以在这里制作AI音频,但要注意不要关掉cmd终端窗口,因为它才是服务的本体,网页端只是操作界面。
3.简单使用演示
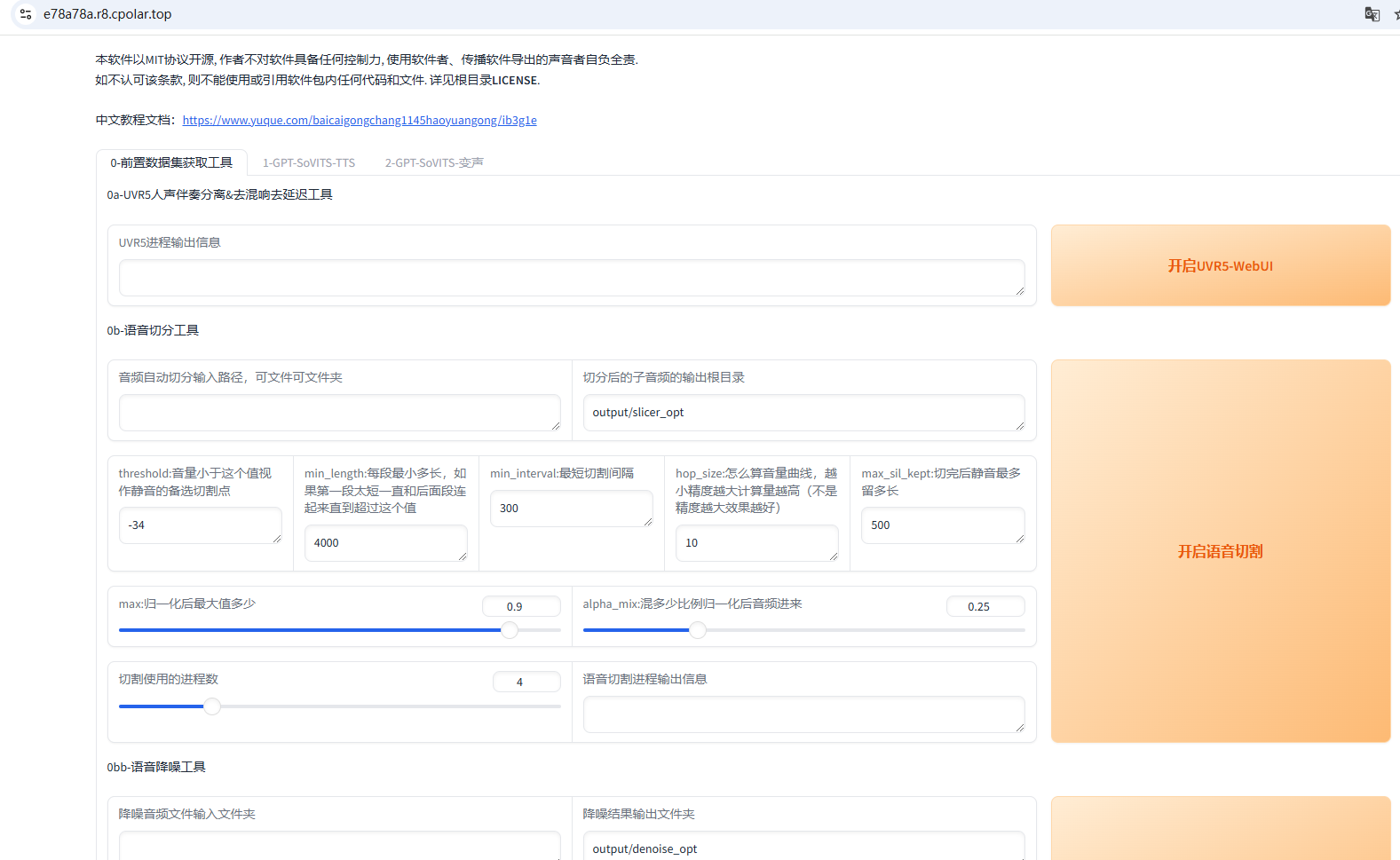
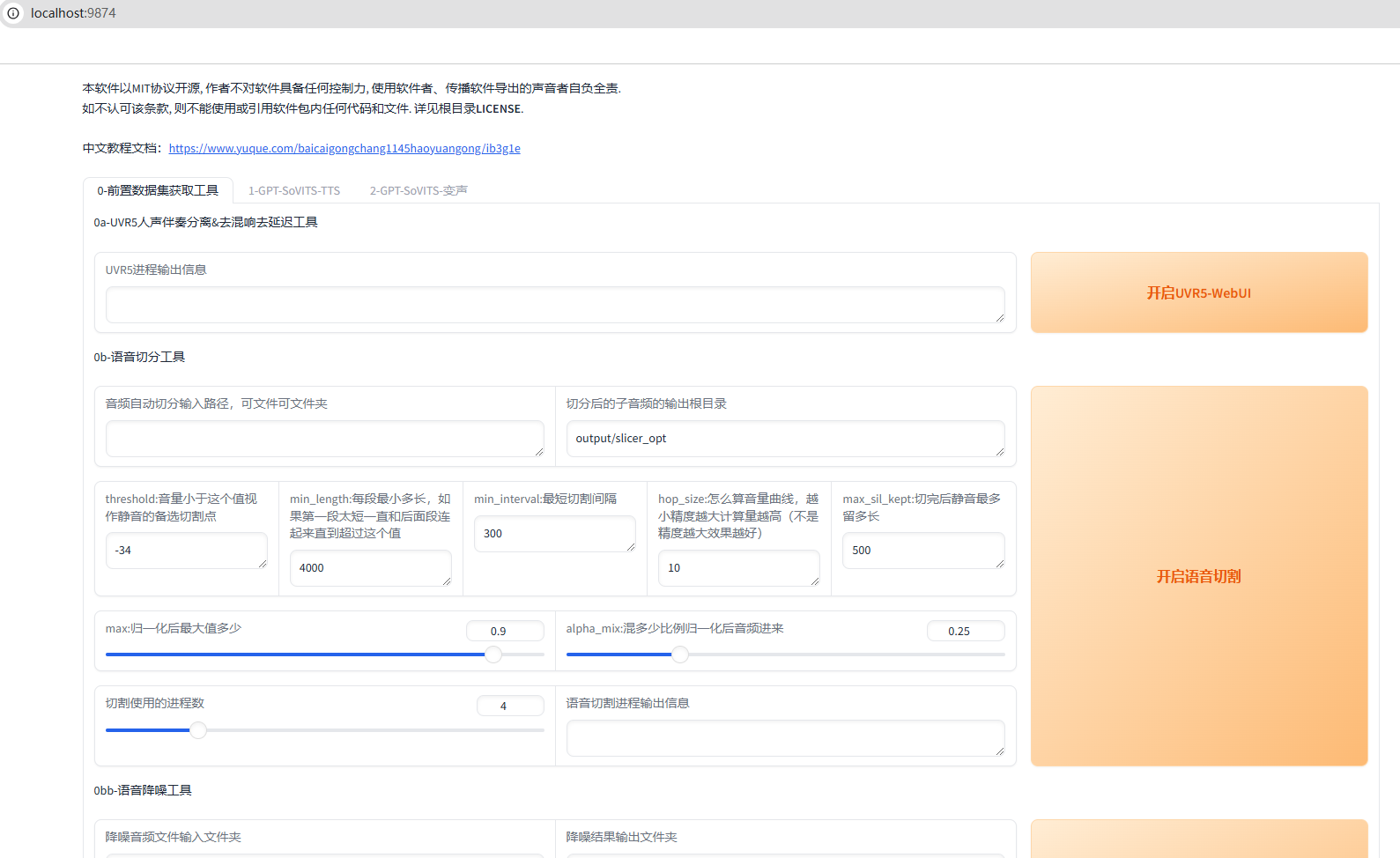
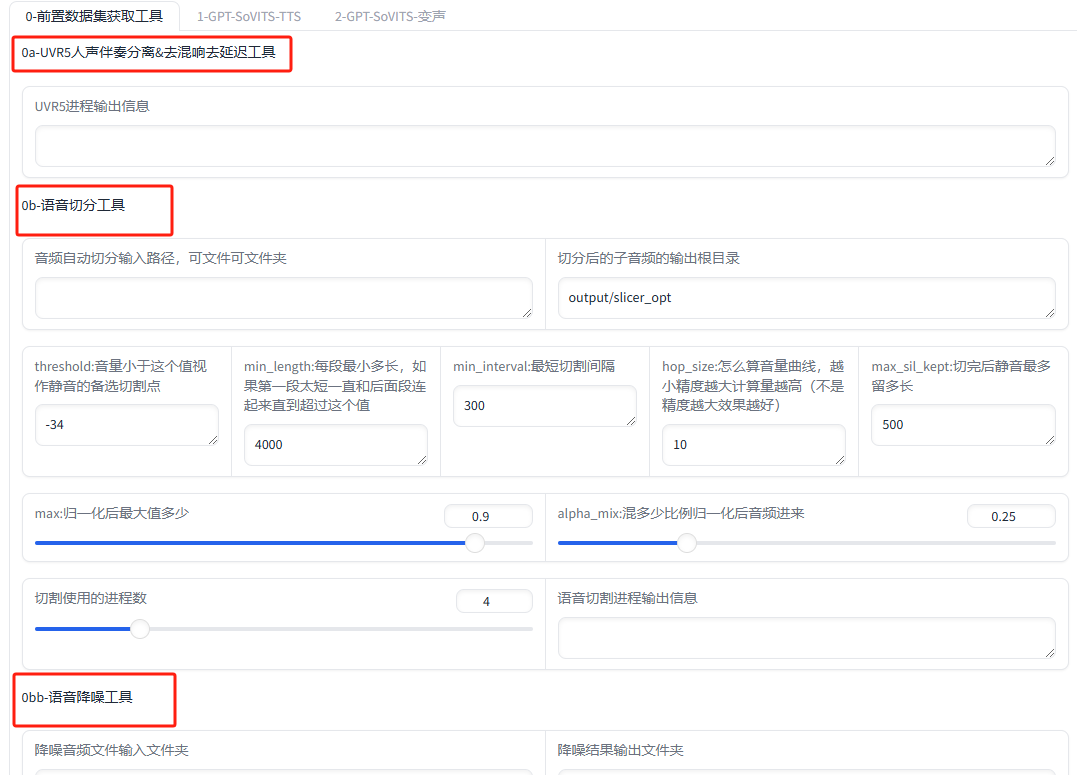
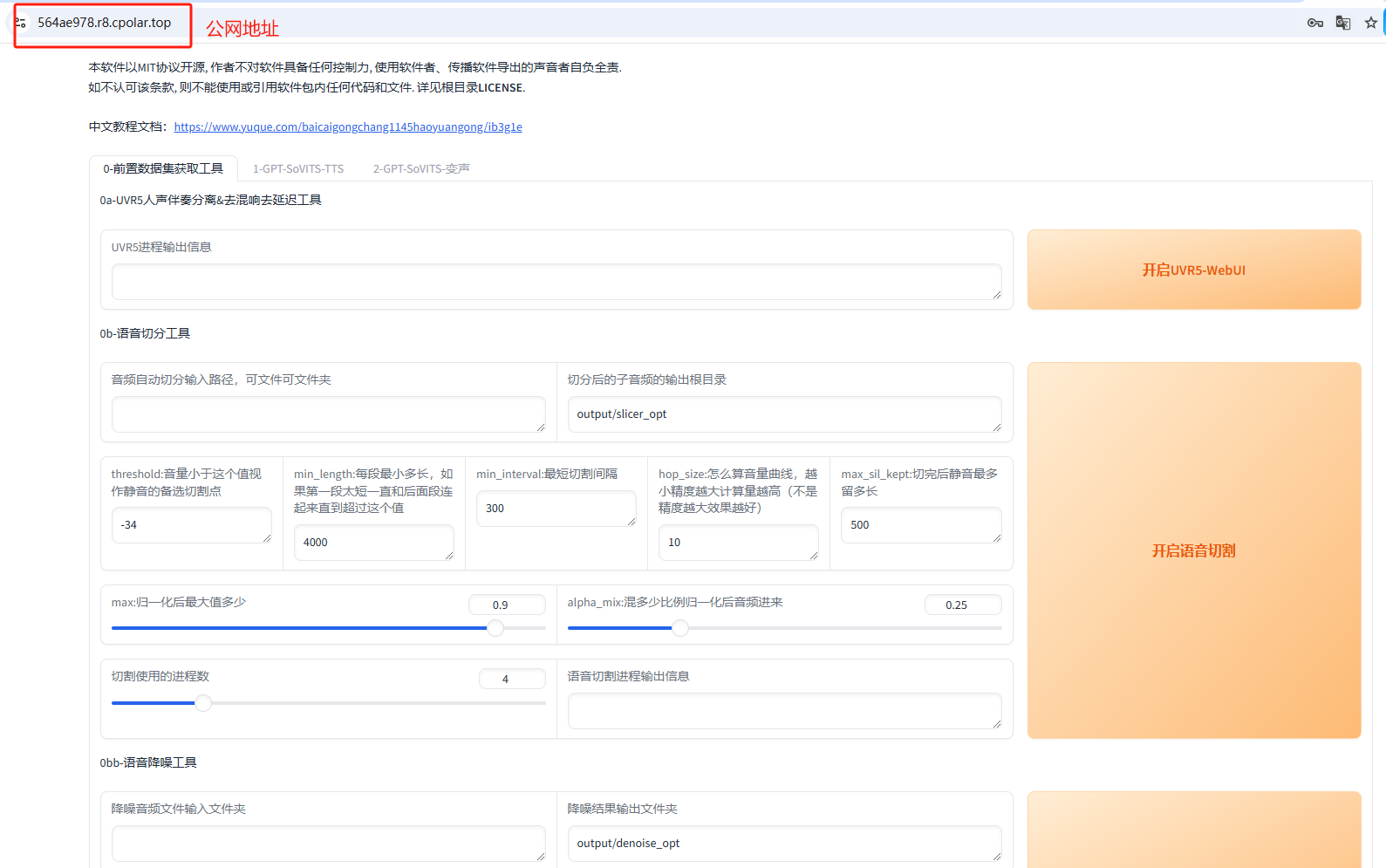
在GPT-SoVITS V2的webui网页页面,我们可以看到默认展示的是0-前置数据集获工具界面,旁边是1-GPT-SoVITS-TTS界面和2-GPT-SoVITS-变声界面
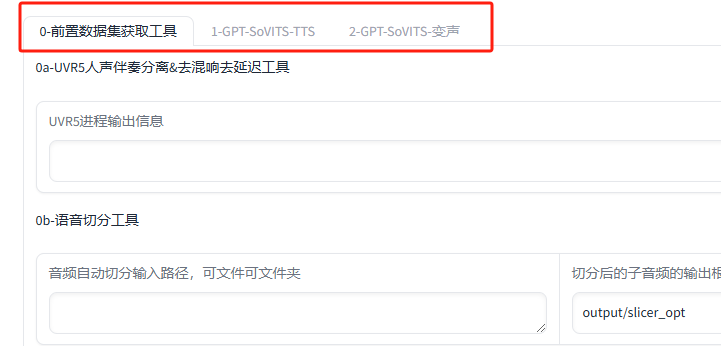
我们可以在0-前置数据集获工具界面进行人声伴奏分离&去混响去延迟,语音切分、降噪等操作,来对要使用的语音进行训练,生成效果更逼真的语音模型。
而如果想马上快速体验一下TTS语音克隆,我们可以点击旁边的1-GPT-SoVITS-TTS界面,选择下面的1C-推理,点击开启TTS推理WebUI:
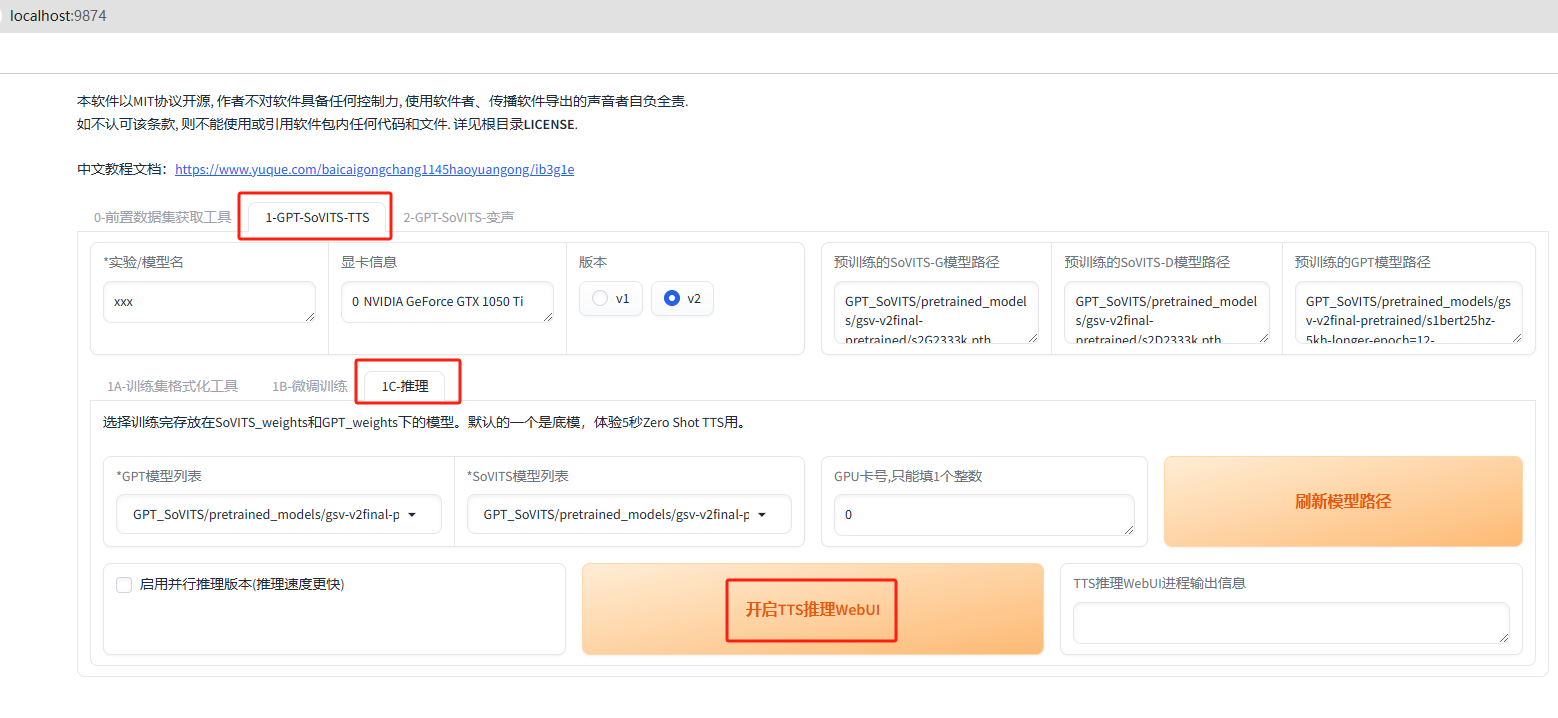
稍等一下后,会在浏览器中新打开一个TTS推理网页,我们可以在这里上传原始音频,时长3到10秒即可,超过会报错。然后可以在下方填写想要合成的目标文本和语种模式:
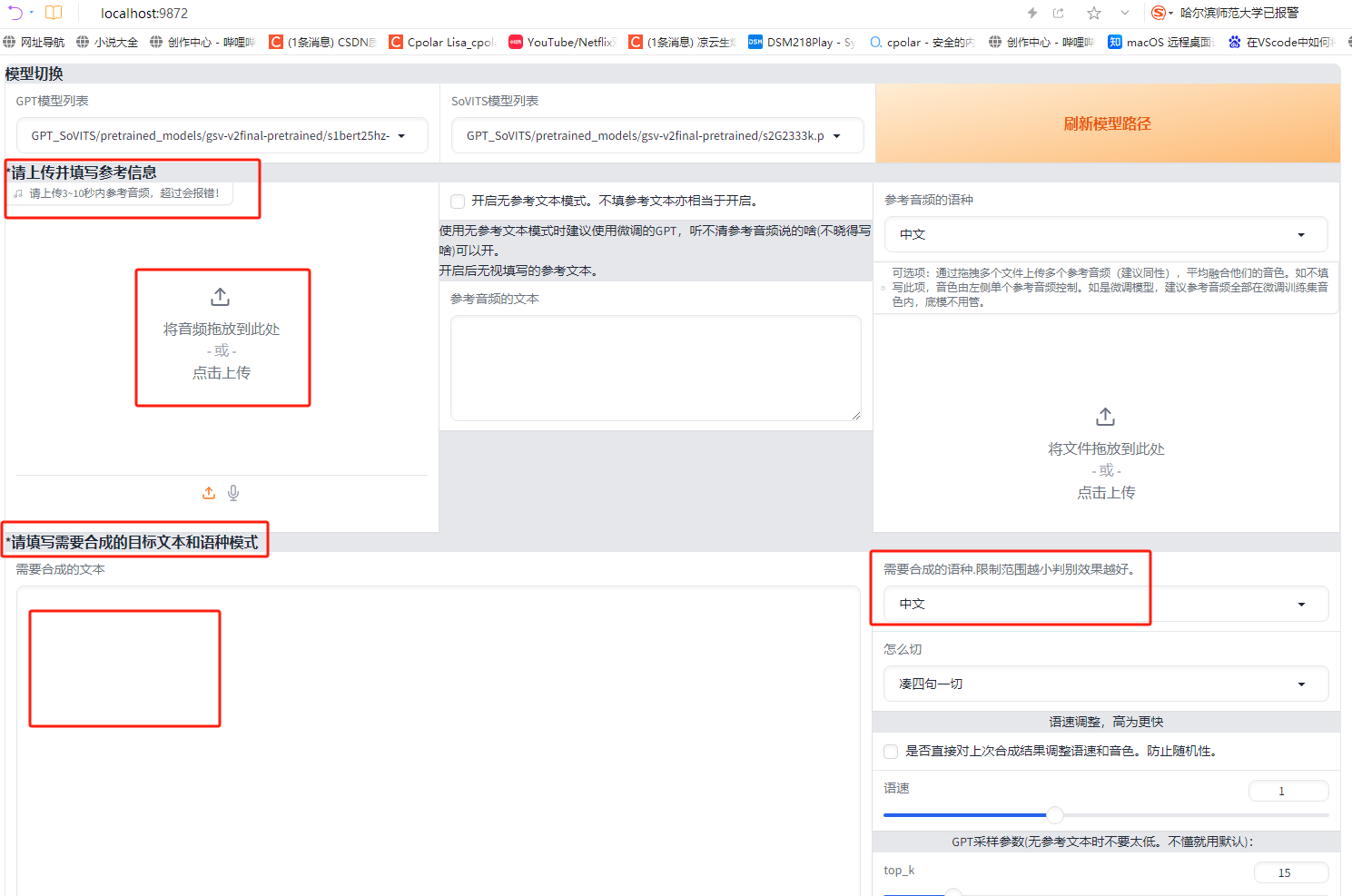
输入好所需信息后,点击合成语音按钮,服务端进行处理,稍后在webui界面即可看到生成的音频:
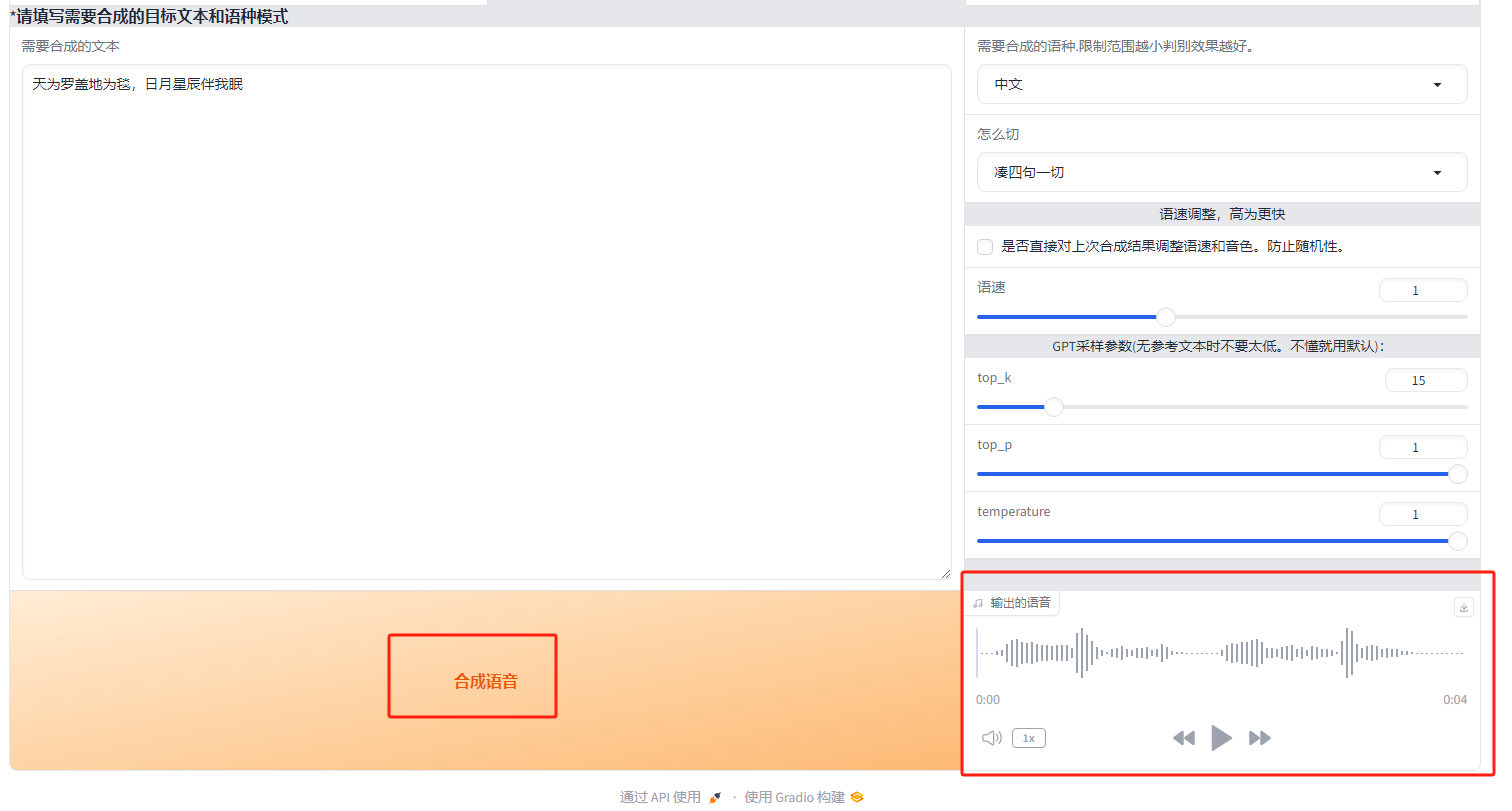
可以点击播放进行试听,点击右上角的下载标志即可将生成的AI音频下载到本地。
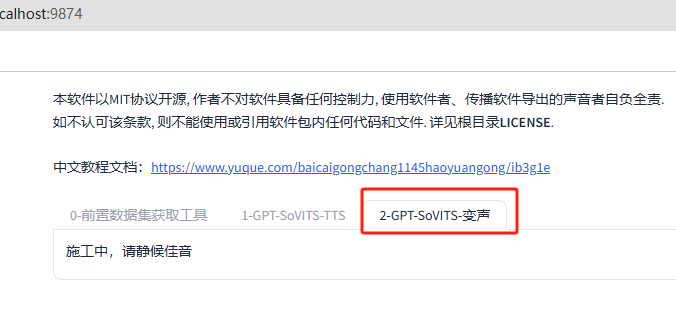
而刚才提到的2-GPT-SoVITS-变声功能目前还没有推出,可以期待一下作者大佬下次的更新。
4.安装内网穿透工具
此时,我们已经成功在Windows电脑中本地部署了GPT-SoVITS V2,但就像开篇时说的那样,我们在这台配置高的电脑上部署了服务后,只能在同一个局域网内使用,有一定局限性。如果想外出时也能远程访问家中部署的GPT-SoVITS或是其他服务,应该怎么办呢?
很简单,只要在电脑中再安装一个cpolar内网穿透工具就能轻松实现远程访问内网主机中部署的服务了,接下来介绍一下如何安装cpolar内网穿透。
首先进入cpolar官网,点击免费使用注册一个账号,并下载最新版本的Cpolar。
cpolar官网地址: https://www.cpolar.com
登录成功后,点击下载Cpolar到本地并安装(一路默认安装即可)本教程选择下载Windows版本。
Cpolar安装成功后,在浏览器上访问http://localhost:9200,使用cpolar账号登录,登录后即可看到Cpolar web 配置界面,结下来在web 管理界面配置即可。
4.1 创建远程连接公网地址
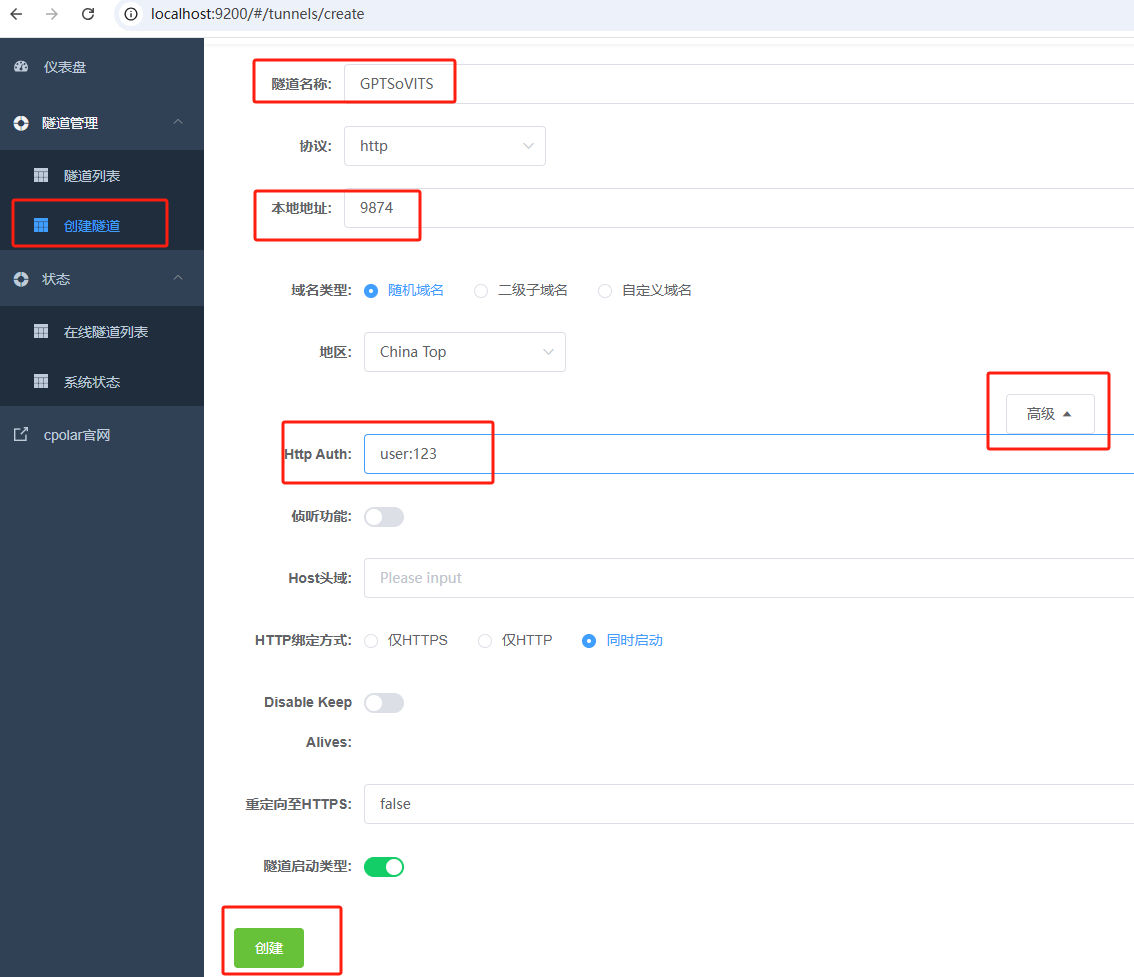
登录cpolar web UI管理界面后,点击左侧仪表盘的隧道管理——创建隧道:
- 隧道名称:可自定义,本例使用了: GPTSoVITS 注意不要与已有的隧道名称重复
- 协议:http
- 本地地址:9874
- 域名类型:随机域名
- 地区:选择China Top
- 高级:Http Auth:user:123(本例中用户名user 密码123)
点击保存
创建成功后,打开左侧在线隧道列表,可以看到刚刚通过创建隧道生成了两个公网地址,接下来就可以在其他电脑(异地)上,使用任意一个地址在浏览器中访问即可。
如下图所示,输入设置的用户名及密码(也可以不设置高级,就无需用户名密码直接登入,安全起见,建议配置高级)
登录后可以看到成功实现使用公网地址异地远程访问本地部署的GPT-SoVITS V2语音克隆工具的webui界面!
小结
为了方便演示,我们在上边的操作过程中使用了cpolar生成的HTTP公网地址隧道,其公网地址是随机生成的。这种随机地址的优势在于建立速度快,可以立即使用,然而,它的缺点是网址是随机生成,这个地址在24小时内会发生随机变化,更适合于临时使用。
如果有长期远程访问本地部署的语音克隆软件或者其他本地部署的服务的需求,但又不想每天重新配置公网地址,还想地址好看又好记,那我推荐大家选择使用固定的二级子域名方式来远程访问,带宽会更快,使用cpolar在其他用途还可以保留多个子域名,支持多个cpolar在线进程。
5. 固定远程访问公网地址
由于以上使用cpolar所创建的隧道使用的是随机公网地址,24小时内会随机变化,不利于长期远程访问。因此我们可以为其配置二级子域名,该地址为固定地址,不会随机变化。
登录cpolar官网,点击左侧的预留,选择保留二级子域名,地区选择china vip,然后设置一个二级子域名名称,填写备注信息,点击保留。
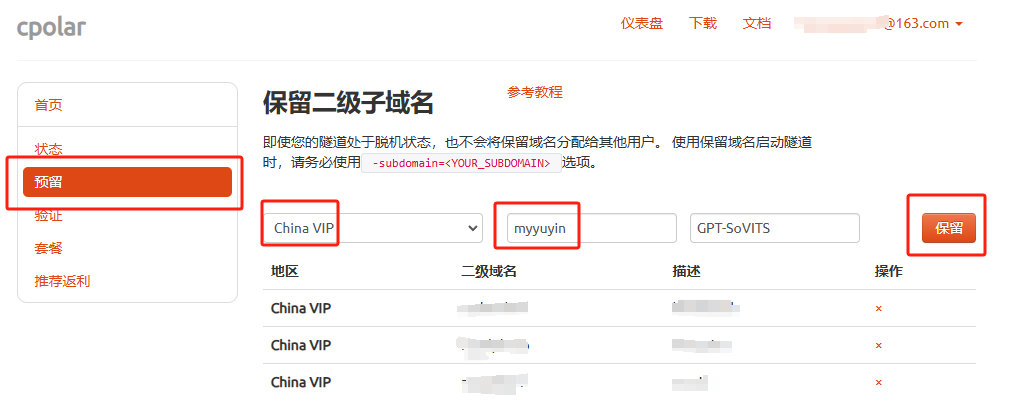
保留成功后复制保留的二级子域名地址:myyuyin
登录cpolar web UI管理界面,点击左侧仪表盘的隧道管理——隧道列表,找到所要配置的隧道,点击右侧的编辑。
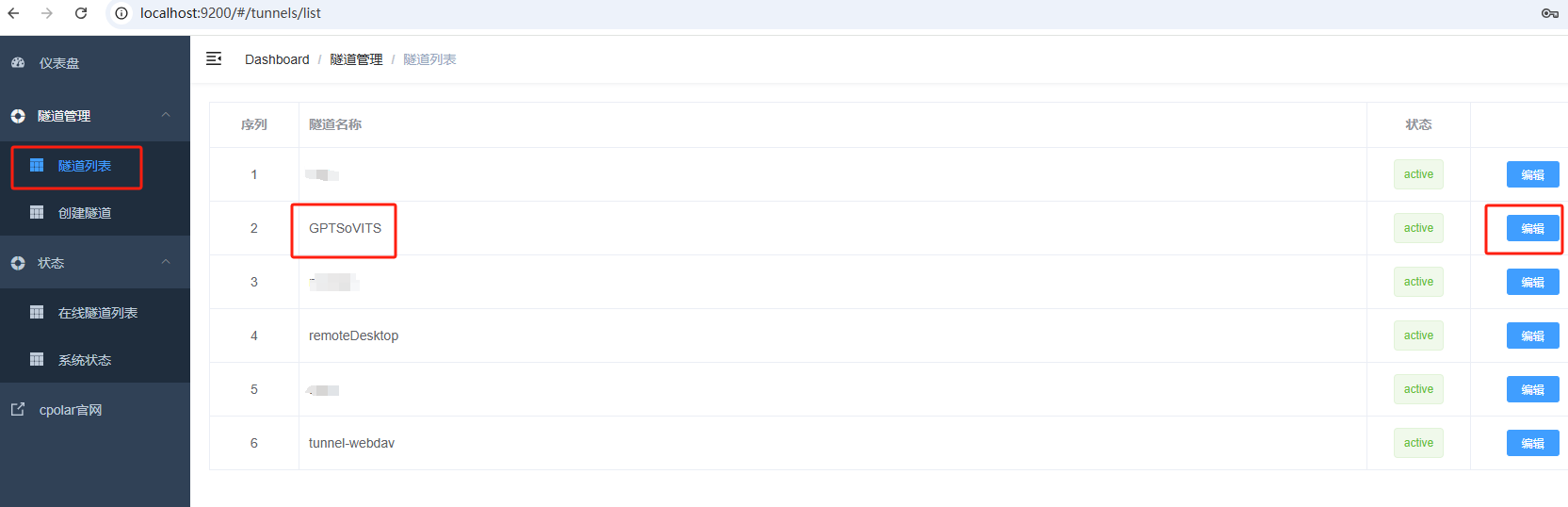
修改隧道信息,将保留成功的二级子域名配置到隧道中
- 域名类型:选择二级子域名
- Sub Domain:填写保留成功的二级子域名
- 地区: China VIP
点击更新
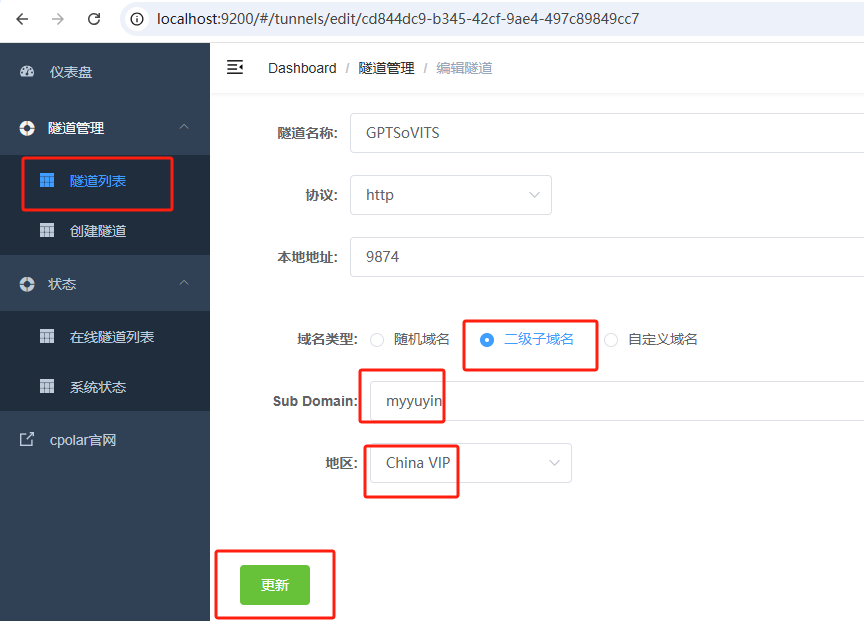
更新完成后,打开在线隧道列表,此时可以看到随机的公网地址已经发生变化,地址名称也变成了保留和固定的二级子域名名称。
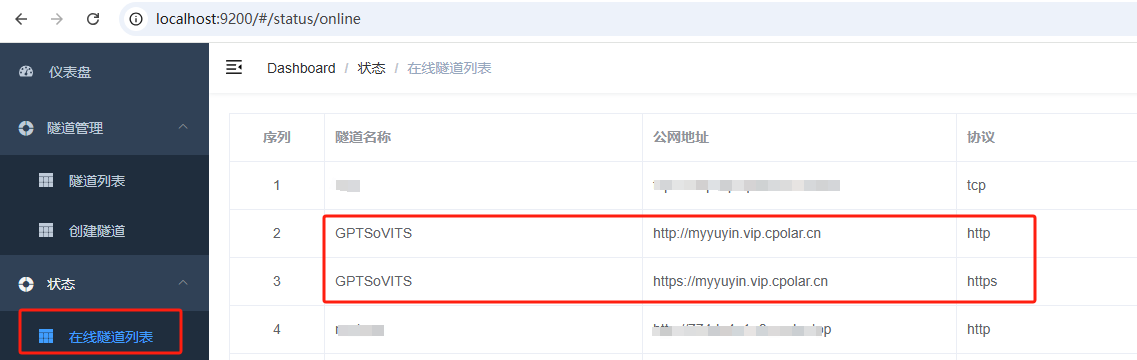
最后,我们使用固定的公网地址在浏览器打开可以看到访问成功,这样一个永久不会变化的公网网址就设置好了:
怎么样,是不是觉得GPT-SoVITS和cpolar的组合简直不要太厉害呢?无论你是想要制作爆笑视频、动感音乐还是其他创意作品,这对搭档都能让你的声音变得五花八门,充满魅力。如果你也被这个项目所吸引,别忘了到GitHub上给花儿不哭大佬送上你的小星星哦!当然了,我们也非常期待你在评论区晒出自己的使用心得和创作成果,让我们一起开启这场声音的奇幻之旅吧!


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











