







文章目录
- 两个数组的 dp
- LCR 095. [最长公共子序列](https://leetcode.cn/problems/qJnOS7/description/)
- 1035. [不相交的线](https://leetcode.cn/problems/uncrossed-lines/submissions/610488024/)
- LCR 097. [不同的子序列](https://leetcode.cn/problems/distinct-subsequences/description/)
- 44. [通配符匹配](https://leetcode.cn/problems/wildcard-matching/description/)
- 10. [正则表达式匹配](https://leetcode.cn/problems/regular-expression-matching/description/)-待解决
- LCR 096. [交错字符串](https://leetcode.cn/problems/IY6buf/)
- 712. [两个字符串的最小ASCII删除和](https://leetcode.cn/problems/minimum-ascii-delete-sum-for-two-strings/description/)
- 718. [最长重复子数组](https://leetcode.cn/problems/maximum-length-of-repeated-subarray/description/)
两个数组的 dp
LCR 095. 最长公共子序列
给定两个字符串 text1 和 text2,返回这两个字符串的最长 公共子序列 的长度。如果不存在 公共子序列 ,返回 0 。
一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。
- 例如,`"ace"` 是 `"abcde"` 的子序列,但 `"aec"` 不是 `"abcde"` 的子序列。
两个字符串的 公共子序列 是这两个字符串所共同拥有的子序列。
示例 1:
**输入:**text1 = "abcde", text2 = "ace"
**输出:**3
**解释:**最长公共子序列是 "ace" ,它的长度为 3 。
示例 2:
**输入:**text1 = "abc", text2 = "abc"
**输出:**3
**解释:**最长公共子序列是 "abc" ,它的长度为 3 。
示例 3:
**输入:**text1 = "abc", text2 = "def"
**输出:**0
**解释:**两个字符串没有公共子序列,返回 0 。
思路
两个数组动态规划我们需要研究第一个数组 [0, i] 区间和第二个数组 [0, j] 区间,所以设dp[i][j]表示字符串text1的前i个字符(即 text1[0] 到 text1[i - 1])和字符串text2的前j个字符(即 text2[0] 到 text2[j - 1])的最长公共子序列的长度,
- 如果
text1的第i个字符(即text1[i - 1])和text2的第j个字符(即text2[j - 1])相等,text1[i-1] == text2[j-1],则dp[i][j] = dp[i - 1][j - 1] + 1,表示当前字符相等,最长公共子序列长度在之前的基础上加 1。 - 例如:
text1 = "abc",text2 = "adc"。计算dp[2][2]时,即考虑text1的前两个字符"ab"和text2的前两个字符"ad",此时text1[1] != text2[1](b和d不相等),所以dp[2][2] = max(dp[1][2], dp[2][1])。计算dp[3][3]时,即考虑text1的前三个字符"abc"和text2的前三个字符"adc",此时text1[2] == text2[2](c和c相等),之前dp[2][2]表示的是"ab"和"ad"的最长公共子序列长度,现在因为text1的第三个字符和text2的第三个字符相等,所以可以把这个相等的字符'c'加入到之前的最长公共子序列中,那么dp[3][3] = dp[2][2] + 1。 - 如果
text1的第i个字符(即text1[i - 1])和text2的第j个字符(即text2[j - 1])不相等,text1[i - 1] != text2[j - 1],则dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]),表示当前字符不相等,不考虑text1的第i个字符或者不考虑text2的第j个字符。
代码
class Solution {
public:
// 计算两个字符串 text1 和 text2 的最长公共子序列的长度
int longestCommonSubsequence(string text1, string text2) {
// 获取 text1 的长度
int n = text1.size();
// 获取 text2 的长度
int m = text2.size();
// 创建二维数组 dp 用于记录中间结果
// dp[i][j] 表示 text1 的前 i 个字符和 text2 的前 j 个字符的最长公共子序列的长度
// 初始值都设为 0,因为当 i 或 j 为 0 时(表示其中一个字符串为空),最长公共子序列长度为 0
vector<vector<int>> dp(n + 1, vector<int>(m + 1, 0));
// 遍历 text1 的每个字符
for (int i = 1; i <= n; ++i) {
// 遍历 text2 的每个字符
for (int j = 1; j <= m; ++j) {
// 如果 text1 的第 i 个字符(索引为 i - 1)和 text2 的第 j 个字符(索引为 j - 1)相等
if (text1[i - 1] == text2[j - 1]) {
// 那么当前的最长公共子序列长度等于去掉这两个相等字符后子串的最长公共子序列长度加 1
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
// 如果当前两个字符不相等
// 则最长公共子序列长度为以下两种情况中的最大值:
// 1. 不考虑 text1 的第 i 个字符时的最长公共子序列长度,即 dp[i - 1][j]
// 2. 不考虑 text2 的第 j 个字符时的最长公共子序列长度,即 dp[i][j - 1]
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
// 返回 text1 的前 n 个字符和 text2 的前 m 个字符的最长公共子序列长度
return dp[n][m];
}
};
1035. 不相交的线
在两条独立的水平线上按给定的顺序写下 nums1 和 nums2 中的整数。
现在,可以绘制一些连接两个数字 nums1[i] 和 nums2[j] 的直线,这些直线需要同时满足:
- `nums1[i] == nums2[j]`
- 且绘制的直线不与任何其他连线(非水平线)相交。
请注意,连线即使在端点也不能相交:每个数字只能属于一条连线。
以这种方法绘制线条,并返回可以绘制的最大连线数。
示例 1:
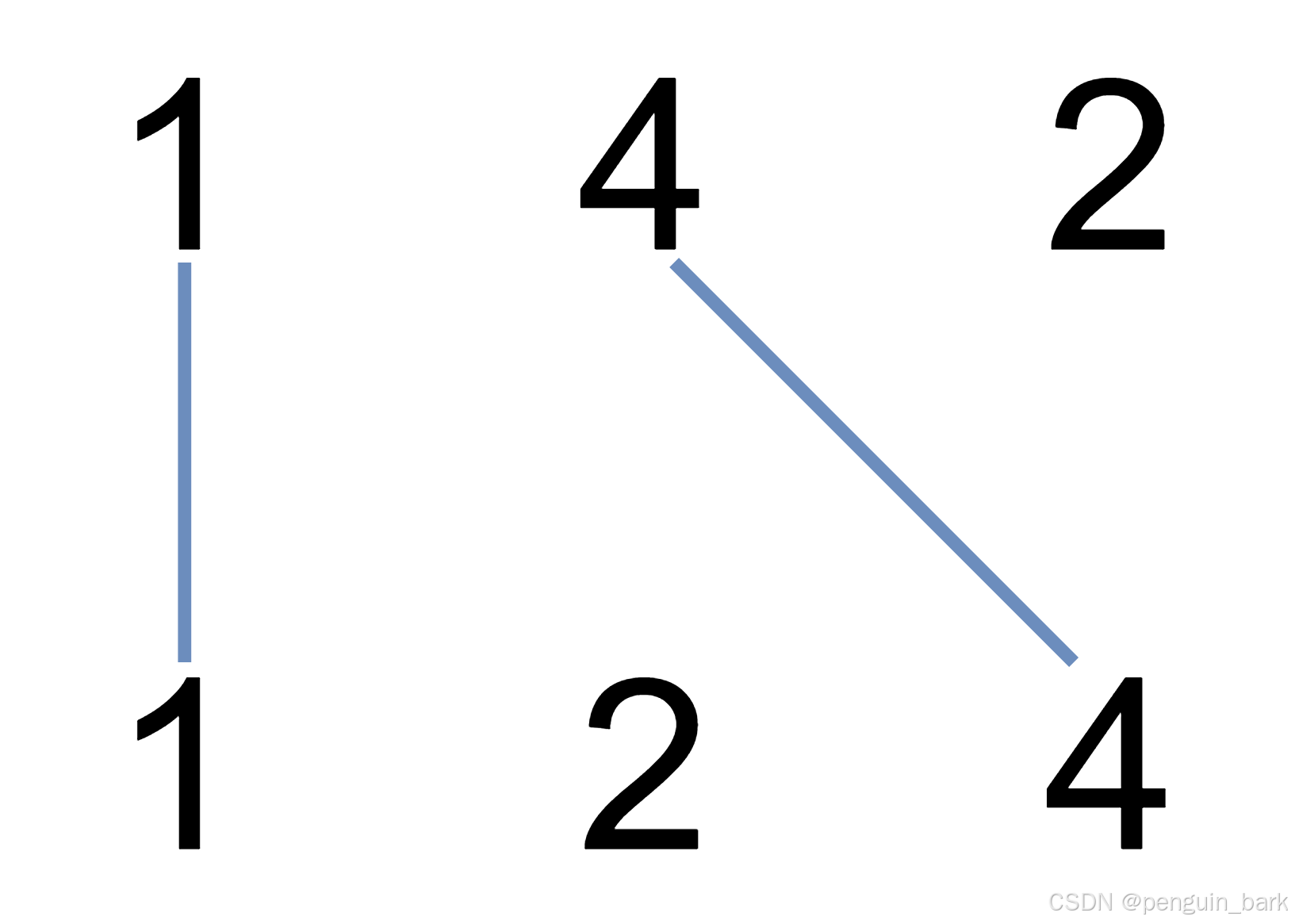
**输入:**nums1 = [1,4,2], nums2 = [1,2,4]
**输出:**2
**解释:**可以画出两条不交叉的线,如上图所示。
但无法画出第三条不相交的直线,因为从 nums1[1]=4 到 nums2[2]=4 的直线将与从 nums1[2]=2 到 nums2[1]=2 的直线相交。
示例 2:
**输入:**nums1 = [2,5,1,2,5], nums2 = [10,5,2,1,5,2]
**输出:**3
示例 3:
**输入:**nums1 = [1,3,7,1,7,5], nums2 = [1,9,2,5,1]
**输出:**2
思路
本质和上面题目一样
代码
class Solution {
public:
int maxUncrossedLines(vector<int>& text1, vector<int>& text2) {
// 获取 text1 的长度
int n = text1.size();
// 获取 text2 的长度
int m = text2.size();
// 创建二维数组 dp 用于记录中间结果
// dp[i][j] 表示 text1 的前 i 个字符和 text2 的前 j 个字符的最长公共子序列的长度
// 初始值都设为 0,因为当 i 或 j 为 0 时(表示其中一个字符串为空),最长公共子序列长度为 0
vector<vector<int>> dp(n + 1, vector<int>(m + 1, 0));
// 遍历 text1 的每个字符
for (int i = 1; i <= n; ++i) {
// 遍历 text2 的每个字符
for (int j = 1; j <= m; ++j) {
// 如果 text1 的第 i 个字符(索引为 i - 1)和 text2 的第 j 个字符(索引为 j - 1)相等
if (text1[i - 1] == text2[j - 1]) {
// 那么当前的最长公共子序列长度等于去掉这两个相等字符后子串的最长公共子序列长度加 1
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
// 如果当前两个字符不相等
// 则最长公共子序列长度为以下两种情况中的最大值:
// 1. 不考虑 text1 的第 i 个字符时的最长公共子序列长度,即 dp[i - 1][j]
// 2. 不考虑 text2 的第 j 个字符时的最长公共子序列长度,即 dp[i][j - 1]
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
// 返回 text1 的前 n 个字符和 text2 的前 m 个字符的最长公共子序列长度
return dp[n][m];
}
};
LCR 097. 不同的子序列
给定一个字符串 s 和一个字符串 t ,计算在 s 的子序列中 t 出现的个数。
字符串的一个 子序列 是指,通过删除一些(也可以不删除)字符且不干扰剩余字符相对位置所组成的新字符串。(例如,"ACE" 是 "ABCDE" 的一个子序列,而 "AEC" 不是)
题目数据保证答案符合 32 位带符号整数范围。
示例 1:
**输入:**s = "rabbbit", t = "rabbit"
**输出:**3
**解释:**
如下图所示, 有 3 种可以从 s 中得到 "rabbit" 的方案。
**rabb**b**it**
**ra**b**bbit**
**rab**b**bit**
示例 2:
**输入:**s = "babgbag", t = "bag"
**输出:**5
**解释:**
如下图所示, 有 5 种可以从 s 中得到 "bag" 的方案。
**ba**b**g**bag
**ba**bgba**g**
**b**abgb**ag**
ba**b**gb**ag**
babg**bag**
思路
设 dp[i][j] 表示 s 的前 i 个字符中包含 t 的前 j 个字符的子序列的个数。i 的取值范围是 0 到 n(n 是 s 的长度),j 的取值范围是 0 到 m(m 是 t 的长度)
-
当
j = 0时:此时t是一个空字符串。因为任何字符串都至少包含一个空字符串作为子序列(即不选取任何字符),所以对于任意的i(0 <= i <= m),都有dp[i][0] = 1。 -
当
i = 0且j > 0的情况:当i = 0时,字符串s为空串。而空串无法包含任何非空的子序列,所以对于任意的j(1 ≤ j ≤ m),都有dp[0][j] = 0,当然这在初始化就完成了。 -
如果 s 的第 i 个字符(索引为 i - 1)和 t 的第 j 个字符(索引为 j - 1)相等,也就是
s[i-1] == t[j-1],可以用s[i - 1]来匹配t[j - 1],需要看s的前i - 1个字符构成的子串中t的前j - 1个字符构成的子串出现的子序列数量,即dp[i - 1][j - 1]- 例如:假设
s = "babgbag",t = "bag",我们来计算dp[7][3],s的第 7 个字符'g'(即s[6])和t的第 3 个字符'g'(即t[2])相等,s[6] == t[2],因为第 7 个'g'已经确定用来匹配t的第 3 个'g'了,那么我们就只需要看s的前 6 个字符"babgba"中包含t的前 2 个字符"ba"的子序列个数,也就是dp[6][2]中。
- 例如:假设
-
不使用
s[i - 1]这个字符:此时就相当于只考虑s的前i - 1个字符构成的子串中t的前j个字符构成的子串出现的子序列数量,即dp[i - 1][j]。- 例如:假设
s = "ABCDE",t = "ACE",我们要计算dp[5][3],也就是s的前 5 个字符"ABCDE"中包含t的前 3 个字符"ACE"的子序列个数。考虑s的第 5 个字符'E'(即s[4])时,决定不使用这个'E'来参与构成t的子序列。那么此时,要计算"ABCDE"中"ACE"的子序列个数,其实和计算"ABCD"中"ACE"的子序列个数是一样的,因为'E'不参与,对结果没有影响。"ABCD"中"ACE"的子序列个数在之前计算dp数组时已经得到,存储在dp[4][3]中,虽然ABCD中不包含ACE,但是dp[4][3]可以是0.
- 例如:假设
-
如果当前字符不相等,退回到上面这种情况
unsigned long long 类型来避免整数溢出问题。
代码
class Solution {
public:
// 计算字符串 s 的子序列中字符串 t 出现的个数
int numDistinct(string s, string t) {
// 获取字符串 s 的长度
int n = s.size();
// 获取字符串 t 的长度
int m = t.size();
// 创建二维数组 dp,dp[i][j] 表示 s 的前 i 个字符的子序列中 t 的前 j 个字符出现的个数
vector<vector<unsigned long long>> dp(n + 1, vector<unsigned long long>(m + 1, 0));
// 初始化:当 t 为空字符串时,s 的任意子串都包含空字符串,所以子序列个数为 1
for (int i = 0; i <= n; ++i) {
dp[i][0] = 1;
}
// 填充 dp 数组
for (int i = 1; i <= n; ++i) {
for (int j = 1; j <= m; ++j) {
// 如果 s 的第 i 个字符(索引为 i - 1)和 t 的第 j 个字符(索引为 j - 1)相等
if (s[i - 1] == t[j - 1]) {
// 有两种情况:
// 1. 使用 s 的第 i 个字符来匹配 t 的第 j 个字符,此时个数为 dp[i - 1][j - 1]
// 2. 不使用 s 的第 i 个字符来匹配 t 的第 j 个字符,此时个数为 dp[i - 1][j]
// 总的个数为这两种情况之和
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
} else {
// 如果当前字符不相等,只能不使用 s 的第 i 个字符来匹配 t 的第 j 个字符
// 所以个数和 s 的前 i - 1 个字符的情况相同
dp[i][j] = dp[i - 1][j];
}
}
}
// 返回最终结果,即 s 的前 n 个字符的子序列中 t 的前 m 个字符出现的个数
return dp[n][m];
}
};
44. 通配符匹配
给你一个输入字符串 (s) 和一个字符模式 (p) ,请你实现一个支持 '?' 和 '*' 匹配规则的通配符匹配:
`'?'` 可以匹配任何单个字符。
`'*'` 可以匹配任意字符序列(包括空字符序列)。
判定匹配成功的充要条件是:字符模式必须能够 完全匹配 输入字符串(而不是部分匹配)。
示例 1:
**输入:**s = "aa", p = "a"
**输出:**false
**解释:**"a" 无法匹配 "aa" 整个字符串。
示例 2:
**输入:**s = "aa", p = "*"
**输出:**true
**解释:**'*' 可以匹配任意字符串。
示例 3:
**输入:**s = "cb", p = "?a"
**输出:**false
**解释:**'?' 可以匹配 'c', 但第二个 'a' 无法匹配 'b'。
思路
-
dp[i][j]表示字符串s的前i个字符和模式p的前j个字符是否能匹配,其中dp[i][j]为true表示可以匹配,false表示不能匹配 -
dp[0][0]:当s和p都为空字符串时,显然是匹配的,所以dp[0][0] = true。 -
dp[i][0](i > 0):当模式s不为空时,p为空字符串,无法匹配,所以dp[i][0] = false。 -
dp[0][j](j > 0):当字符串s为空字符串时,只有当模式p全是'*'时才能匹配,因为'*'可以匹配空字符串。所以如果p[j - 1]是'*',则dp[0][j] = dp[0][j - 1],否则当 p 中有一个不是'*',dp[ 0 ] [ j ] = false`。 -
当
p[j - 1]是普通字符时,s[i - 1]等于p[j - 1],那么dp[i][j]的值取决于s的前i - 1个字符和p的前j - 1个字符是否匹配,即dp[i][j] = dp[i - 1][j - 1]; -
当
p[j - 1]是'?'时,'?'可以匹配任何单个字符,所以dp[i][j]的值也取决于s的前i - 1个字符和p的前j - 1个字符是否匹配,即dp[i][j] = dp[i - 1][j - 1]。 -
当
p[j - 1]是'\*'时,'*'匹配空字符串,此时dp[i][j] = dp[i][j - 1]。'*'匹配一个或多个字符,此时dp[i][j] = dp[i - 1][j]。- 两种情况都要只要有一个满足就行
代码
class Solution {
public:
// 判断字符串 s 是否能和模式 p 匹配
bool isMatch(string s, string p) {
// 获取字符串 s 的长度
int m = s.length();
// 获取模式 p 的长度
int n = p.length();
// 创建二维布尔数组 dp,dp[i][j] 表示 s 的前 i 个字符和 p 的前 j 个字符是否匹配
vector<vector<bool>> dp(m + 1, vector<bool>(n + 1, false));
// 初始化:当 s 和 p 都为空字符串时,它们是匹配的
dp[0][0] = true;
// 处理 s 为空字符串,p 不为空的情况
for (int j = 1; j <= n; ++j) {
// 如果 p 的第 j 个字符是 '*',则 dp[0][j] 的值取决于 dp[0][j - 1]
if (p[j - 1] == '*') {
dp[0][j] = dp[0][j - 1];
}
}
// 填充 dp 数组
for (int i = 1; i <= m; ++i) {
for (int j = 1; j <= n; ++j) {
// 如果 p 的第 j 个字符和 s 的第 i 个字符相等,或者 p 的第 j 个字符是 '?'
if (p[j - 1] == s[i - 1] || p[j - 1] == '?') {
// 则 dp[i][j] 的值取决于 dp[i - 1][j - 1]
dp[i][j] = dp[i - 1][j - 1];
}
// 如果 p 的第 j 个字符是 '*'
else if (p[j - 1] == '*') {
// 有两种情况:'*' 匹配空字符串或一个及以上字符
// dp[i][j - 1] 表示 '*' 匹配空字符串
// dp[i - 1][j] 表示 '*' 匹配一个及以上字符
dp[i][j] = dp[i][j - 1] || dp[i - 1][j];
}
}
}
// 返回 s 的全部字符和 p 的全部字符是否匹配的结果
return dp[m][n];
}
};
10. 正则表达式匹配-待解决
给你一个字符串 s 和一个字符规律 p,请你来实现一个支持 '.' 和 '*' 的正则表达式匹配。
- `'.'` 匹配任意单个字符
- `'*'` 匹配零个或多个前面的那一个元素
所谓匹配,是要涵盖 **整个 **字符串 s 的,而不是部分字符串。
示例 1:
**输入:**s = "aa", p = "a"
**输出:**false
**解释:**"a" 无法匹配 "aa" 整个字符串。
示例 2:
**输入:**s = "aa", p = "a*"
**输出:**true
**解释:**因为 '*' 代表可以匹配零个或多个前面的那一个元素, 在这里前面的元素就是 'a'。因此,字符串 "aa" 可被视为 'a' 重复了一次。
示例 3:
**输入:**s = "ab", p = ".*"
**输出:**true
**解释:**".*" 表示可匹配零个或多个('*')任意字符('.')。
思路
1. 状态定义
设 dp[i][j] 表示字符串 s 的前 i 个字符和模式 p 的前 j 个字符是否能匹配,dp[i][j] 为 true 表示可以匹配,false 表示不能匹配。其中 i 取值范围是 0 到 s.length(),j 取值范围是 0 到 p.length()。
2. 初始化
dp[0][0]:当s和p都为空字符串时,显然是匹配的,所以dp[0][0] = true。dp[i][0](i > 0):当模式p为空字符串,而s不为空时,无法匹配,所以dp[i][0] = false。dp[0][j](j > 0):当字符串s为空字符串时,只有当模式p形如a*b*c*这种形式(即偶数位置为*)时才能匹配。因为*可以让其前面的字符出现零次,所以可以消除掉前面的字符。
3. 状态转移方程
-
当
p[j - 1]不是'*'时:
- 如果
s[i - 1]等于p[j - 1]或者p[j - 1]是'.',那么dp[i][j]的值取决于s的前i - 1个字符和p的前j - 1个字符是否匹配,即dp[i][j] = dp[i - 1][j - 1]。 - 否则
dp[i][j] = false。
- 如果
-
当
p[j - 1]是'*'时:
'\*'让前面的字符出现零次:此时dp[i][j] = dp[i][j - 2],因为可以把p[j - 2]和p[j - 1](即x*)这部分直接忽略。'\*'让前面的字符出现至少一次:要求s[i - 1]等于p[j - 2]或者p[j - 2]是'.',并且dp[i][j] = dp[i - 1][j],表示用s的前i - 1个字符和p的前j个字符匹配,然后p[j - 2]对应的字符再在s中多匹配一个s[i - 1]。
综合这两种情况,dp[i][j] = dp[i][j - 2] || ( (s[i - 1] == p[j - 2] || p[j - 2] == '.') && dp[i - 1][j] )。
4. 最终结果
最终 dp[s.length()][p.length()] 表示字符串 s 和模式 p 是否能匹配。
代码
class Solution {
public:
bool isMatch(string s, string p) {
int m = s.length();
int n = p.length();
vector<vector<bool>> dp(m + 1, vector<bool>(n + 1, false));
dp[0][0] = true;
for (int j = 1; j <= n; j++) {
if (p[j - 1] == '*' && dp[0][j - 2]) {
dp[0][j] = true;
}
}
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (p[j - 1] != '*') {
dp[i][j] = (s[i - 1] == p[j - 1] || p[j - 1] == '.') && dp[i - 1][j - 1];
} else {
dp[i][j] = dp[i][j - 2] || ( (s[i - 1] == p[j - 2] || p[j - 2] == '.') && dp[i - 1][j] );
}
}
}
return dp[m][n];
}
};
LCR 096. 交错字符串
给定三个字符串 s1、s2、s3,请判断 s3 能不能由 s1 和 s2 交织(交错) 组成。
两个字符串 s 和 t 交织 的定义与过程如下,其中每个字符串都会被分割成若干 非空 子字符串:
- `s = s1 + s2 + ... + sn`
- `t = t1 + t2 + ... + tm`
- `|n - m| <= 1`
- 交织 是 `s1 + t1 + s2 + t2 + s3 + t3 + ...` 或者 `t1 + s1 + t2 + s2 + t3 + s3 + ...`
提示:a + b 意味着字符串 a 和 b 连接。
示例 1:
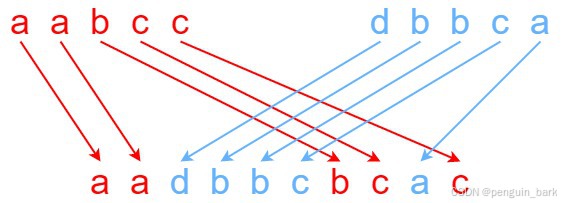
**输入:**s1 = "aabcc", s2 = "dbbca", s3 = "aadbbcbcac"
**输出:**true
示例 2:
**输入:**s1 = "aabcc", s2 = "dbbca", s3 = "aadbbbaccc"
**输出:**false
示例 3:
**输入:**s1 = "", s2 = "", s3 = ""
**输出:**true
思路
-
dp[i][j]表示s1的前i个字符和s2的前j个字符是否能交错组成s3的前i + j个字符。其中i的取值范围是0到s1.length(),j的取值范围是0到s2.length()。 -
dp[0][0]:当s1和s2都为空字符串时,显然可以组成空字符串s3,所以dp[0][0] = true。 -
dp[i][0]:当s2为空字符串时,s1的前i个字符必须和s3的前i个字符完全相同,dp[i][0]才为true,即dp[i][0] = dp[i - 1][0] && s1[i - 1] == s3[i - 1]。 -
dp[0][j]:当s1为空字符串时,s2的前j个字符必须和s3的前j个字符完全相同,dp[0][j]才为true,即dp[0][j] = dp[0][j - 1] && s2[j - 1] == s3[j - 1]。 -
从s1中拿元素,
-
假设
s1 = "abc",s2 = "def",s3 = "adbcef"。我们要判断dp[2][1],也就是s1 的前 2 个字符“ab"和s2的前 1 个字符"d"能否交错组成s3的前 3 个字符"adb”`。当我们考虑
s1的第 2 个字符(索引为i - 1 = 1),即s1[1] = 'b',s3的第i + j个字符(索引为i + j - 1 = 2),即s3[2] = 'b',此时s1[1] == s3[2]。接下来,我们需要看
s1的前i - 1 = 1个字符"a"和s2的前j = 1个字符"d"能否交错组成s3的前i + j - 1 = 2个字符"ad",这个情况已经在dp[1][1]中计算过了。如果dp[1][1]为true,那么就说明s1的前 2 个字符和s2的前 1 个字符能交错组成s3的前 3 个字符,即dp[2][1]为true。
-
-
从s2中拿元素,
-
dp[1][2],也就是s1的前 1 个字符"a"和s2的前 2 个字符"de"能否交错组成s3的前 3 个字符"adb"。当我们考虑
s2的第 2 个字符(索引为j - 1 = 1),即s2[1] = 'e',s3的第i + j个字符(索引为i + j - 1 = 2),即s3[2] = 'b',这里s2[1] != s3[2],所以这种情况不满足。假设
s3 = "adebc",我们再看dp[1][2],此时s2[1] = 'e',s3[2] = 'e',满足s2[1] == s3[2]。然后我们要检查
s1的前i = 1个字符"a"和s2的前j - 1 = 1个字符"d"能否交错组成s3的前i + j - 1 = 2个字符"ad",这个情况存储在dp[1][1]中。如果dp[1][1]为true,那么dp[1][2]为true。
-
代码
class Solution {
public:
bool isInterleave(string s1, string s2, string s3) {
int n = s1.length();
int m = s2.length();
int k = s3.length();
// 如果 s1 和 s2 的长度之和不等于 s3 的长度,直接返回 false
if (m + n != k) {
return false;
}
// 创建二维布尔数组 dp 并初始化
vector<vector<bool>> dp(n + 1, vector<bool>(m + 1, false));
dp[0][0] = true;
// 初始化第一列
for (int i = 1; i <= n; ++i) {
dp[i][0] = dp[i - 1][0] && s1[i - 1] == s3[i - 1];
}
// 初始化第一行
for (int j = 1; j <= m; ++j) {
dp[0][j] = dp[0][j - 1] && s2[j - 1] == s3[j - 1];
}
// 填充 dp 数组
for (int i = 1; i <= n; ++i) {
for (int j = 1; j <= m; ++j) {
if (s1[i - 1] == s3[i + j - 1] && dp[i - 1][j]) {
dp[i][j] = true;
}
if (s2[j - 1] == s3[i + j - 1] && dp[i][j - 1]) {
dp[i][j] = true;
}
}
}
return dp[n][m];
}
};
712. 两个字符串的最小ASCII删除和
给定两个字符串s1 和 s2,返回 使两个字符串相等所需删除字符的 **ASCII **值的最小和 。
示例 1:
**输入:** s1 = "sea", s2 = "eat"
**输出:** 231
**解释:** 在 "sea" 中删除 "s" 并将 "s" 的值(115)加入总和。
在 "eat" 中删除 "t" 并将 116 加入总和。
结束时,两个字符串相等,115 + 116 = 231 就是符合条件的最小和。
示例 2:
**输入:** s1 = "delete", s2 = "leet"
**输出:** 403
**解释:** 在 "delete" 中删除 "dee" 字符串变成 "let",
将 100[d]+101[e]+101[e] 加入总和。在 "leet" 中删除 "e" 将 101[e] 加入总和。
结束时,两个字符串都等于 "let",结果即为 100+101+101+101 = 403 。
如果改为将两个字符串转换为 "lee" 或 "eet",我们会得到 433 或 417 的结果,比答案更大。
思路
正难则反:求两个字符串的最⼩ ASCII 删除和,其实就是找到两个字符串中所有的公共⼦序列⾥⾯, ASCII 最⼤和。
因此,我们的思路就是按照「最⻓公共⼦序列」的分析⽅式来分析。
static_cast<int> 显式地将一种数据类型转换为 int 数据类型
-
dp[i][j]表示字符串s1的前i个字符和字符串s2的前j个字符的公共子序列的最大 ASCII 值之和 -
如果
s1[i - 1] == s2[j - 1]:说明当前字符可以作为公共子序列的一部分,那么dp[i][j]就等于s1的前i - 1个字符和s2的前j - 1个字符的公共子序列的最大 ASCII 值之和,再加上当前相等字符的 ASCII 值,即dp[i][j] = dp[i - 1][j - 1] + static_cast<int>(s1[i - 1])。 -
如果
s1[i - 1] != s2[j - 1]:此时需要比较两种情况:
- 不考虑
s1的第i个字符,即dp[i][j] = dp[i - 1][j]。 - 不考虑
s2的第j个字符,即dp[i][j] = dp[i][j - 1]。
取这两种情况中的最大值,即dp[i][j] = std::max(dp[i - 1][j], dp[i][j - 1])。
- 不考虑
用 totalSum 减去 dp[m][n] 的两倍(因为公共子序列的 ASCII 值在 totalSum 中被算了两次
代码
class Solution {
public:
int minimumDeleteSum(string s1, string s2) {
int n = s1.size();
int m = s2.size();
int sum = 0;
for(int i=0; i<n; ++i){
sum+=static_cast<int>(s1[i]);
}
for(int j=0; j<m; ++j){
sum+=static_cast<int>(s2[j]);
}
vector<vector<int>>dp(n+1, vector<int>(m+1, 0));
for(int i=1; i<=n; ++i){
for(int j=1; j<=m; ++j){
if(s1[i-1] == s2[j-1]){
dp[i][j] = dp[i-1][j-1]+static_cast<int>(s1[i-1]);
}else{
dp[i][j] = max(dp[i-1][j], dp[i][j-1]);
}
}
}
return sum-2*dp[n][m];
}
};
718. 最长重复子数组
给两个整数数组 nums1 和 nums2 ,返回 两个数组中 公共的 、长度最长的子数组的长度 。
示例 1:
**输入:**nums1 = [1,2,3,2,1], nums2 = [3,2,1,4,7]
**输出:**3
**解释:**长度最长的公共子数组是 [3,2,1] 。
示例 2:
**输入:**nums1 = [0,0,0,0,0], nums2 = [0,0,0,0,0]
**输出:**5
思路
dp[i][j]表示以nums1的前i个数字结尾和以nums2的前j个数字结尾的公共子数组的最长长度- 如果
nums1[i - 1] == nums2[j - 1],即dp[i][j] = dp[i - 1][j - 1] + 1。- 例如:假设
nums1 = [1, 2, 3, 2, 1],nums2 = [3, 2, 1, 4, 7],计算dp[3][1]时,以nums1[2]结尾的子数组是[1, 2, 3],以nums2[0]结尾的子数组是[3]。因为当前字符3相等,所以以nums1[2]结尾和以nums2[0]结尾的公共子数组的最长长度,就取决于以nums1[1]结尾和以nums2[-1](这里我们关注逻辑,实际代码不会有负数索引)结尾的公共子数组的最长长度。在dp数组中,就是dp[i - 1][j - 1],也就是dp[2][0],它的值为0。那么dp[3][1]就等于dp[2][0] + 1 = 0 + 1 = 1。,
- 例如:假设
- 如果
nums1[i - 1] != nums2[j - 1],那么以nums1[i - 1]结尾和以nums2[j - 1]结尾的公共子数组的最长长度为0,即dp[i][j] = 0。 - 填充
dp数组的过程中,记录下dp[i][j]的最大值,这个最大值就是两个数组中公共的、长度最长的子数组的长度
代码
class Solution {
public:
int findLength(vector<int>& nums1, vector<int>& nums2) {
int n = nums1.size();
int m = nums2.size();
vector<vector<int>>dp(n+1, vector<int>(m+1, 0));
int ret = 0;
for(int i=1; i<=n; ++i){
for(int j=1; j<=m; ++j){
if(nums1[i-1] ==nums2[j-1]){
dp[i][j] = dp[i-1][j-1]+1;
ret = max(ret, dp[i][j]);
}else{
dp[i][j]=0;
}
}
}
return ret;
}
};



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











