







引言: 在前几章中,我们已经探讨了 LLM 推理的基本流程、KV 缓存优化以及模型本身的优化策略。然而,随着应用场景的不断拓展,处理越来越长的文本序列成为了一个重要的需求。例如,在文档总结、长篇故事生成、代码库分析等任务中,模型需要处理数千甚至数万个 token。长文本推理带来了新的挑战,主要是内存消耗和计算复杂度的显著增加。本章将深入探讨这些挑战,并介绍一些高级解决方案及其在主流框架中的支持情况。
6.1 长文本推理的内存瓶颈与优化
KV 缓存的内存增长问题与优化策略:
正如第三章所介绍的,KV 缓存用于存储先前计算的 Key 和 Value 向量,以加速解码过程中的注意力计算。然而,对于长文本推理,KV 缓存的大小会随着生成序列的长度线性增长。每个生成的 token 都需要存储其对应的 Key 和 Value 向量,这在处理数千甚至数万 token 的长序列时,会导致巨大的内存消耗,甚至超出 GPU 显存的限制,从而导致推理失败或性能急剧下降。
针对 KV 缓存的内存增长问题,已经出现了一些优化策略:
- KV 缓存压缩: 通过降低 KV 缓存的精度(例如从 FP16 降至 INT8)或使用量化技术来减小其内存占用。这种方法可以在一定程度上减少内存消耗,但可能会导致模型生成质量的轻微下降。
- KV 缓存卸载 (Offloading): 将部分 KV 缓存存储到 CPU 内存或硬盘上,当需要时再加载到 GPU 显存中。这种方法可以处理更长的序列,但由于 CPU 和 GPU 之间的数据传输速度较慢,可能会显著增加推理延迟。
- 窗口注意力 (Windowed Attention): 限制每个 token 只能关注其周围固定窗口大小的 token,从而限制了 KV 缓存的增长。但这可能会损失全局上下文信息,影响需要长距离依赖的任务。
- 稀疏注意力 (Sparse Attention): 如 6.2 节所述,通过只关注重要的 token 来减少 KV 缓存中需要存储的内容。
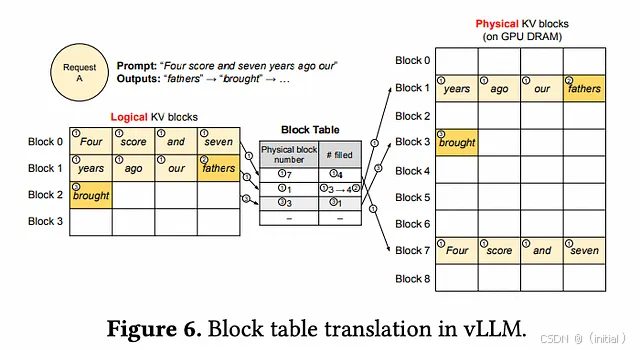
PagedAttention 的深入解析与 vLLM 实践:
传统的 KV 缓存通常为每个序列分配一块连续的内存空间。当一个序列生成完毕或被中断时,这块内存空间可能无法被其他序列完全利用,导致内存碎片化。此外,即使是同一批请求,如果它们的生成长度不同,也会导致 KV 缓存中存在大量的填充 (padding),造成内存浪费。
PagedAttention 的核心思想是将每个序列的 KV 缓存分割成多个固定大小的内存块(pages)。这些内存块在物理上是不连续的,但通过一个逻辑映射表进行管理。当模型生成新的 token 时,只需要分配一个新的内存块,而不需要分配一大块连续的内存空间。
vLLM 实践: vLLM 是一个专门为 LLM 推理设计的高性能框架,它原生支持 PagedAttention。使用 vLLM 进行长文本推理时,PagedAttention 会自动管理 KV 缓存,用户无需显式操作。vLLM 通常可以显著提高长文本推理的吞吐量并降低内存占用。
vLLM 简易使用示例:
虽然详细的使用方法请参考 vLLM 官方文档,但以下是一个非常简化的示例,展示了如何使用 vLLM 加载模型并进行推理:
from vllm import LLM, SamplingParams
# 加载模型
llm = LLM(model="Qwen/Qwen2-7B-Chat") # 替换为您希望使用的模型
# 定义采样参数
sampling_params = SamplingParams(max_tokens=50)
# 输入提示
prompt = "The quick brown fox jumps over the lazy dog."
# 进行推理
outputs = llm.generate(prompt, sampling_params)
# 打印输出
for output in outputs:
print(output.outputs[0].text)
6.2 注意力机制的计算瓶颈与高效变体
Self-Attention 的复杂度分析与优化思路:
Transformer 模型的核心是自注意力(Self-Attention)机制。对于一个长度为 L L L 的输入序列,自注意力机制需要计算每个 token 与所有其他 token 之间的注意力权重。这个过程的计算复杂度是 O ( L 2 d ) O(L^2 d) O(L2d), 其中 d d d 是 hidden dimension 的大小。对于长文本来说, L L L 非常大,导致计算量呈平方级增长,成为推理速度的主要瓶颈。
为了解决自注意力机制的计算瓶颈,研究人员提出了多种优化思路:
- 降低复杂度:设计新的注意力机制,使其计算复杂度低于 O ( L 2 ) O(L^2) O(L2)。
- 近似计算:使用近似方法来估计注意力权重,从而减少计算量。
- 利用稀疏性:只计算部分重要的 token 之间的注意力。
- 硬件加速:利用专门的硬件(如 GPU、TPU)来加速注意力计算。
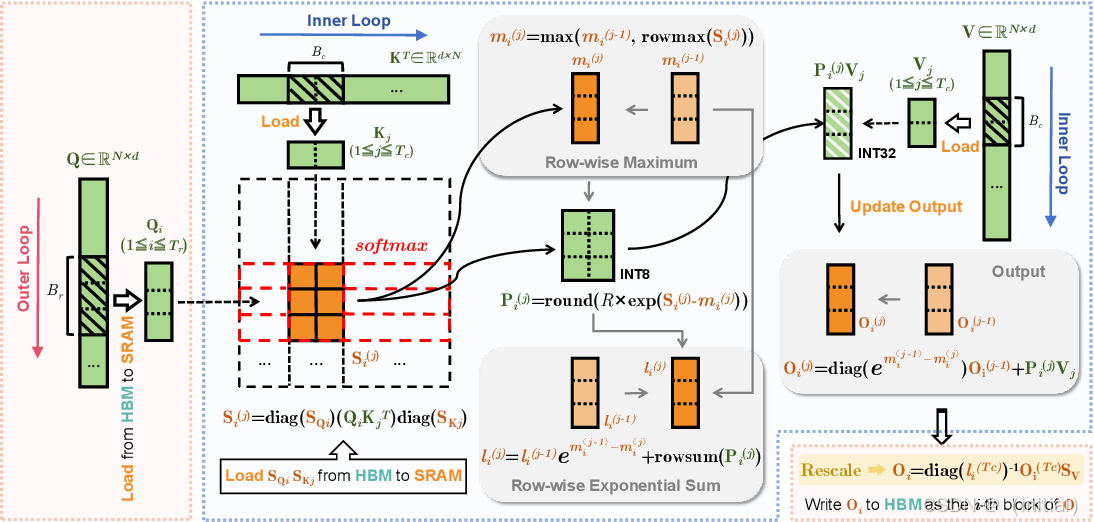
FlashAttention 等高效注意力机制的原理、优势与框架实现:
FlashAttention 是一种通过重新组织注意力计算的方式,显著提高计算效率并减少 GPU 内存占用的高效注意力机制。其核心思想包括:
- Tiling: 将输入序列和注意力矩阵分成小块(tiles),在 GPU 的快速共享内存中进行计算,减少对慢速 HBM 的访问。
- Kernel Fusion: 将多个注意力计算步骤(例如计算相似度、softmax、加权求和)合并到一个 GPU kernel 中,减少 kernel launch 的开销。
优势: FlashAttention 可以在不损失精度的情况下,显著提高长文本推理的速度,并降低显存占用,使得在有限的硬件资源上处理更长的序列成为可能。
框架实现: FlashAttention 已经在多个主流框架中得到支持:
- PyTorch: 可以通过安装
flash-attn库来使用 FlashAttention。Hugging Face Transformers 库也集成了对 FlashAttention 的支持,只需简单配置即可启用。 - Hugging Face Transformers: 从特定版本开始,Transformers 提供了
torch_dtype="float16"和attn_implementation="flash_attention_2"等参数,可以方便地在支持的 Transformer 模型上启用 FlashAttention。
稀疏注意力机制及其在长文本推理中的应用:
稀疏注意力机制的核心思想是让每个 token 只关注序列中一部分相关的 token,而不是所有 token,从而将注意力计算的复杂度从 O ( L 2 ) O(L^2) O(L2) 降低到接近 O ( L ) O(L) O(L) 或 O ( L log L ) O(L \log L) O(LlogL)。常见的稀疏注意力模式包括:
- 固定模式 (Fixed Patterns):例如,每个 token 只关注其周围固定窗口大小的 token,或者只关注某些固定的位置(例如全局 token)。
- 局部注意力 (Local Attention):每个 token 主要关注其附近的 token。
- 全局注意力 (Global Attention):少数全局 token 可以关注所有 token,而局部 token 只关注附近的 token和全局 token。
- 学习到的稀疏性 (Learned Sparsity):通过模型学习哪些 token 之间应该建立注意力。
应用: 稀疏注意力机制在处理非常长的文本(例如文档、书籍)时非常有用,可以显著降低计算成本,使得模型能够处理超出传统自注意力机制能力范围的序列长度。一些模型架构,如 Longformer 和 BigBird,都采用了稀疏注意力机制。
高效注意力机制的对比:
| 特性 | FlashAttention | 稀疏注意力 |
|---|---|---|
| 核心思想 | 优化注意力计算的内存访问和 kernel 执行 | 减少需要计算注意力的 token 对数量 |
| 复杂度 | 接近 O ( L 2 d ) O(L^2 d) O(L2d),但在实际硬件上效率更高 | 可以降低到 O ( L log L d ) O(L \log L d) O(LlogLd) 或更低 |
| 精度 | 通常与标准注意力接近或相同 | 可能有轻微精度损失,取决于稀疏模式 |
| 硬件依赖 | 对 GPU 架构有较强依赖,需要特定硬件优化 | 对硬件要求相对较低,但需要软件支持稀疏计算 |
| 适用场景 | 适用于需要加速标准注意力计算的场景,尤其在长文本下 | 适用于极长文本,可以牺牲一定的全局信息来换取效率 |
| 框架支持 | PyTorch (通过 flash-attn 库), Transformers | Transformers 中有多种稀疏注意力变体的实现 |
6.3 实操:尝试使用支持长文本推理的模型和框架,并进行性能测试。
在本章的最后,我们鼓励您进行实际操作:
- 选择支持长文本的模型: 尝试使用一些专门为长上下文设计的 LLM 模型。您可以在 Hugging Face Model Hub 上搜索包含 “long context” 或特定注意力机制名称(如 “RoPE”)的仓库。一些例子可能包括 Qwen 系列、InternLM 系列、Mistral 系列的一些变体等。
- 使用 vLLM 框架: 尝试安装并使用 vLLM 框架进行推理。vLLM 旨在提供高吞吐量的 LLM 推理服务,并内置了 PagedAttention 等优化技术,非常适合长文本场景。您可以查阅 vLLM 的官方文档了解如何加载模型和进行推理。
- 探索 FlashAttention: 如果您使用 PyTorch 和 Hugging Face Transformers,尝试在支持的模型上启用 FlashAttention,并比较其在处理较长文本时的推理速度和内存占用。
- 性能测试: 针对不同长度的输入文本,测试模型的推理延迟、吞吐量以及 GPU 内存消耗。观察当输入长度增加时,这些指标的变化情况。您可以编写简单的脚本来测量这些指标。
在性能测试时,建议关注以下指标:
- 吞吐量 (Throughput): 例如,每秒可以处理的 token 数量或请求数量。在长文本场景下,吞吐量往往是更重要的指标。
- 延迟 (Latency): 例如,生成第一个 token 的时间或生成完整序列的时间。
- 内存消耗 (Memory Usage): 例如,GPU 显存的占用情况。对于长文本推理,内存往往是瓶颈。
通过实际操作和性能测试,您将能够更深入地理解长文本推理所面临的挑战,以及各种优化技术所带来的实际效果。
总结: 长文本推理是大型语言模型应用中的一个重要且具有挑战性的领域。本章介绍了内存瓶颈(主要是 KV 缓存)和计算瓶颈(主要是自注意力机制)以及针对这些瓶颈的高级解决方案,包括 PagedAttention、FlashAttention 和稀疏注意力机制。这些技术在不断发展,并且在主流的深度学习框架中得到了越来越多的支持。通过理解和应用这些技术,我们可以更好地利用 LLM 处理更长的文本序列,从而解锁更广泛的应用场景。
内容同步在我的公众号:智语Bot




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











