







引言
在前几章中,我们已经深入探讨了大型语言模型推理的基本流程(预填充与解码)、关键的性能瓶颈(如 KV 缓存),以及如何通过选择合适的解码策略来影响生成结果。第三章我们详细介绍了 KV 缓存及其优化方法,显著提升了推理效率。然而,除了 KV 缓存,还有一系列模型优化技术可以直接作用于模型本身,从而在模型大小、推理速度和精度之间取得更好的平衡。本章将聚焦于这些超越 KV 缓存的推理加速技巧,并通过代码实践来展示它们的应用。
1. 模型量化(Model Quantization):原理、方法与代码实现
模型量化是一种通过降低模型中权重和激活的数值精度来减小模型大小、提高推理速度的技术。例如,将通常使用的 32 位浮点数(FP32)表示转换为 8 位整数(INT8)甚至更低的精度。
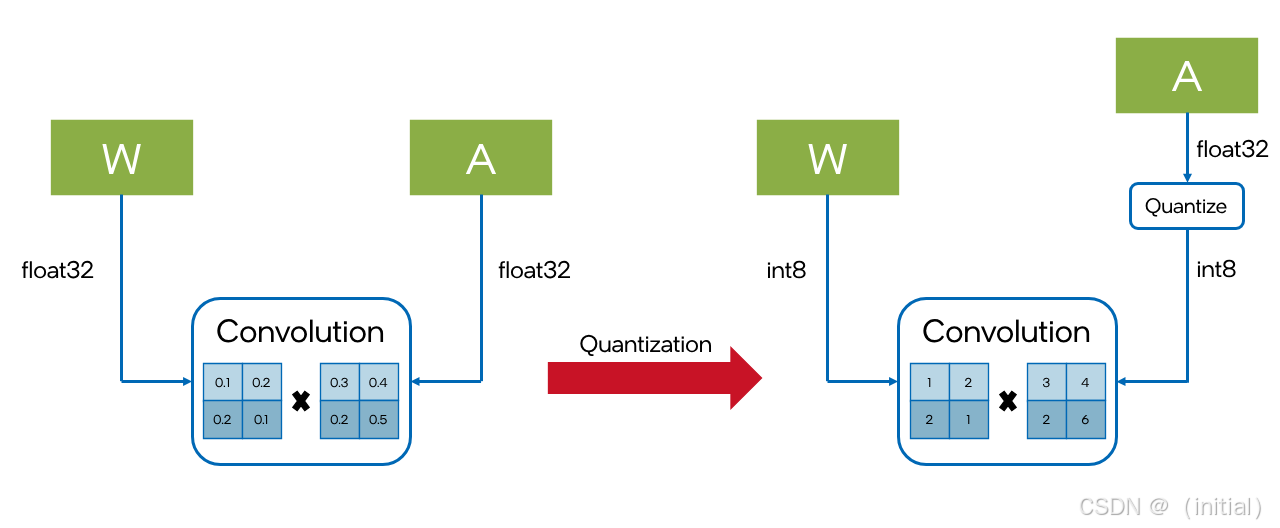
1.1基本概念:
- 精度降低: 量化的核心是将高精度的数据表示映射到低精度的数据表示。
- 内存占用减少: 低精度表示需要的存储空间更小,从而减小了模型在内存中的占用。
- 计算加速: 许多硬件(尤其是 CPU 和一些加速器)对低精度运算进行了优化,可以显著提高计算速度。
- 精度损失: 量化通常会带来一定的精度损失,需要在速度和精度之间进行权衡。
1.2 主要方法:
-
训练后量化(Post-training Quantization, PTQ): 这是一种在模型训练完成后进行的量化方法。通常只需要少量校准数据(几百到几千条)来估计量化参数。PTQ 的优点是简单易行,不需要重新训练模型,但精度损失可能相对较大。
实现示例 (PyTorch):```python import torch from transformers import AutoModelForCausalLM, AutoTokenizer model_name = "Qwen/Qwen2-7B-Chat" # 替换为 Qwen2.5 模型 model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True).eval() # 注意部分模型可能需要 trust_remote_code=True tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True) # 准备校准数据 (这里仅为示例) calibration_texts = ["This is a sample text.", "Another example sentence."] calibration_inputs = [tokenizer(text, return_tensors="pt")["input_ids"] for text in calibration_texts] # 执行训练后量化 quantized_model = torch.quantization.quantize_dynamic( model, {torch.nn.Linear}, dtype=torch.qint8 ) print("Original model size:", model.get_memory_footprint() / 1024**2, "MB") print("Quantized model size:", quantized_model.get_memory_footprint() / 1024**2, "MB") # 可以对量化后的模型进行推理 prompt = "The capital of France is" input_ids = tokenizer.encode(prompt, return_tensors="pt") output = quantized_model.generate(input_ids, max_length=20) print(tokenizer.decode(output[0], skip_special_tokens=True)) ``` -
量化感知训练(Quantization-aware Training, QAT): 这是一种在模型训练过程中就考虑量化的方法。它通过在训练中模拟量化操作,使模型能够更好地适应低精度表示,从而通常可以获得比 PTQ 更高的精度。QAT 的缺点是需要重新训练模型,训练成本较高。
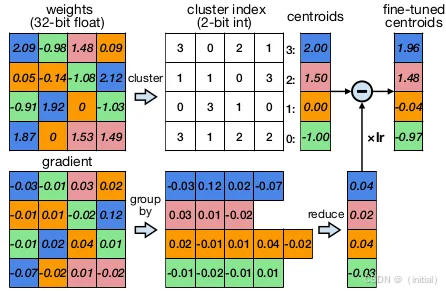
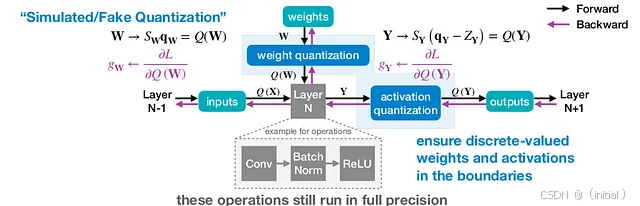
PyTorch 提供了 QAT 的 API,需要在训练循环中插入量化和反量化操作。
1.3 常见的量化级别与权衡:
- FP32 (32 位浮点数): 原始精度,模型大,速度慢,精度高。
- FP16 (16 位浮点数): 半精度,模型大小减半,速度可能提升,精度损失较小。
- INT8 (8 位整数): 模型大小进一步减小,速度显著提升,但可能带来一定的精度损失。
- INT4 (4 位整数) 及更低精度: 模型尺寸更小,速度更快,但精度损失风险更高,通常需要更精细的量化策略。
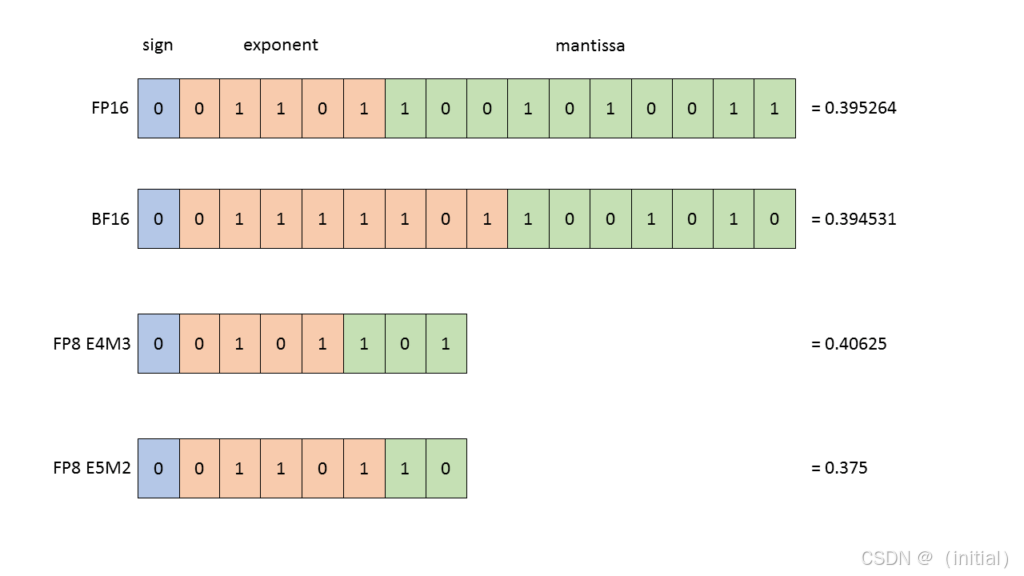
影响分析: 量化通常可以显著减小模型大小(例如,INT8 量化可以将模型大小减少到原来的四分之一),并提高推理速度(尤其是在支持低精度运算的硬件上)。然而,不合理的量化策略可能会导致模型精度显著下降,因此需要在实际应用中仔细评估和选择合适的量化方案。
不同框架的量化工具对比: 各个深度学习框架都提供了相应的量化工具和 API,用户可以根据自己的框架选择合适的工具进行模型量化。例如,PyTorch 提供了 torch.quantization 模块,TensorFlow 提供了 TensorFlow Lite 工具包,ONNX Runtime 提供了 onnxruntime.quantization 模块。
2. 模型剪枝(Model Pruning):原理与代码实现
模型剪枝是一种通过移除模型中不重要的权重或神经元来减小模型大小和计算复杂度的技术。剪枝后的模型通常具有稀疏的权重矩阵。
基本概念:
- 稀疏性: 剪枝会导致模型中许多权重的值变为零,从而形成稀疏的权重矩阵。
- 计算量减少: 稀疏的权重矩阵可以减少模型推理时的计算量,尤其是在支持稀疏计算的硬件上。
- 模型大小减小: 移除不重要的权重可以减小模型的存储空间。
常见剪枝方法:
-
权重剪枝 (Weight Pruning): 移除模型中单个的、不重要的权重。
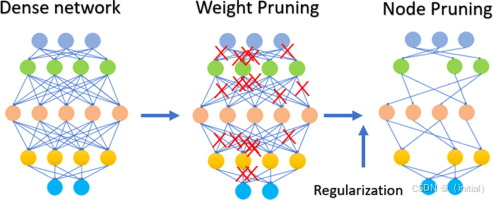
-
神经元剪枝 (Neuron Pruning) / 结构化剪枝 (Structured Pruning): 移除整个神经元或卷积核等结构,更容易在现有硬件上实现加速。
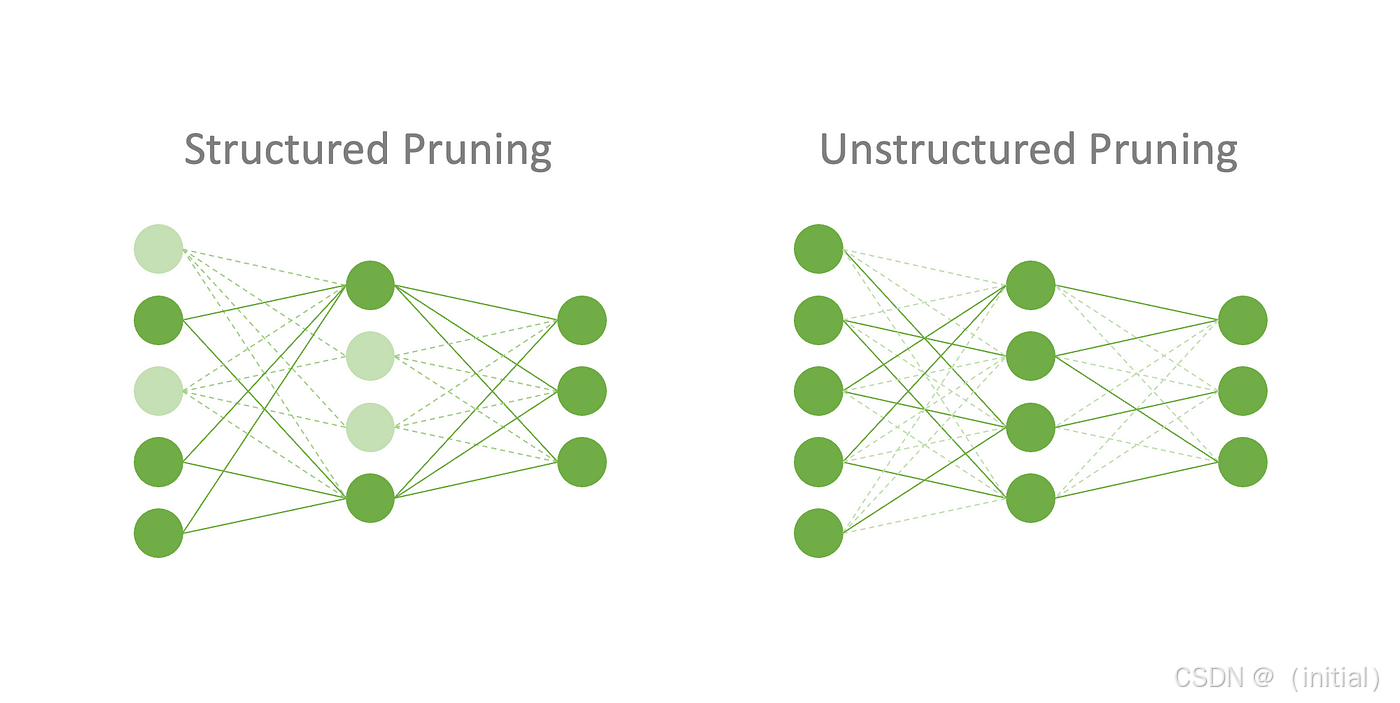
实现示例 (PyTorch):
import torch
import torch.nn.utils.prune as prune
from transformers import AutoModelForCausalLM
model_name = "Qwen/Qwen2.5-7B-Chat"
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True) # 注意部分模型可能需要 trust_remote_code=True
# 选择要剪枝的层
module = model.transformer.h[0].attn.c_attn
# 进行权重剪枝 (移除 20% 的权重)
prune.random_unstructured(module, name="weight", amount=0.2)
prune.remove(module, "weight") # 使剪枝永久生效
print(f"Sparsity of weight in layer: {torch.sum(module.weight == 0) / module.weight.numel()}")
# 可以对剪枝后的模型进行推理 (可能需要一些额外的处理来利用稀疏性加速)
稀疏性对推理性能的影响: 剪枝引入的稀疏性只有在底层硬件和软件能够有效利用这种稀疏性时才能转化为实际的推理加速。例如,一些 GPU 和 CPU 具有专门的指令集来加速稀疏矩阵的运算。同时,一些推理引擎(如 TensorRT、ONNX Runtime)也针对稀疏模型进行了优化。
5.3 知识蒸馏(Knowledge Distillation)在推理加速中的应用
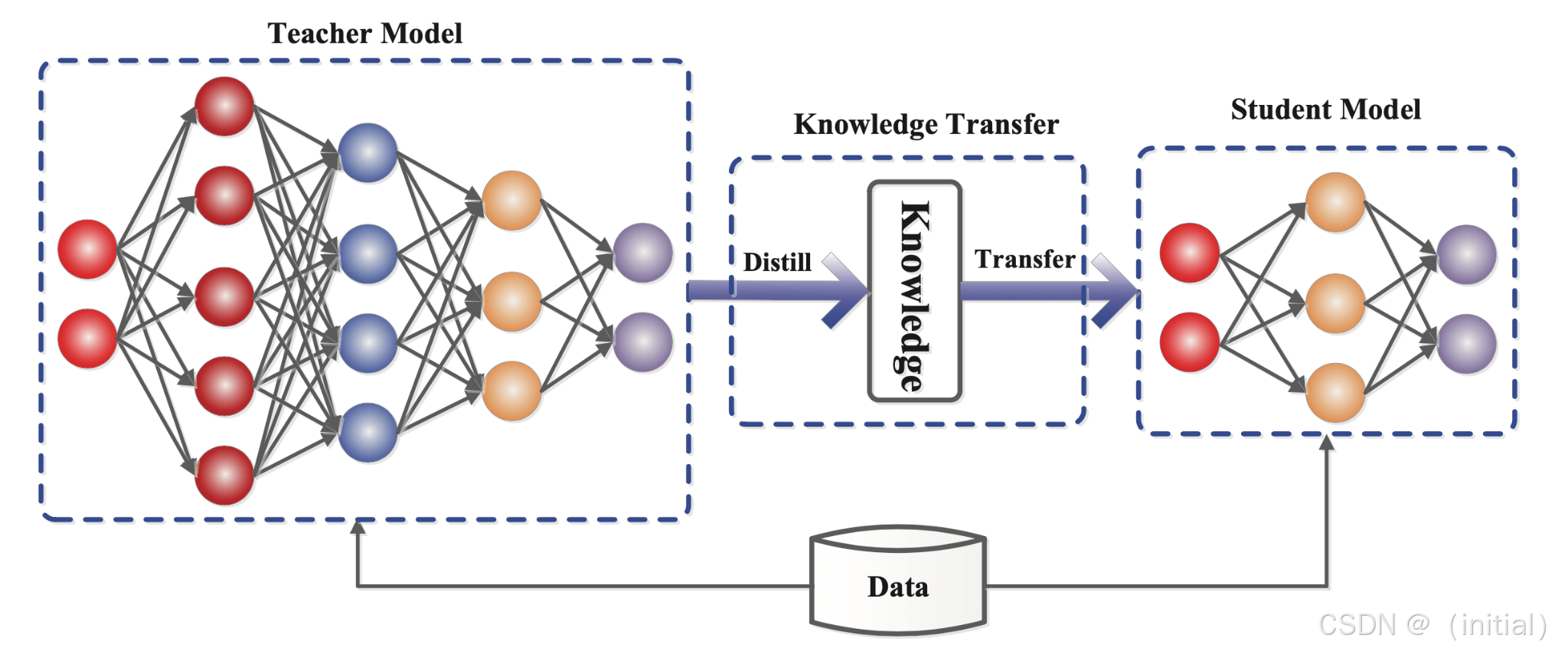
基本原理:
- 教师模型: 通常是一个预训练好的、性能优越的大型模型。
- 学生模型: 通常是一个结构更简单、参数量更小的模型,目标是模仿教师模型的行为。
- 知识迁移: 学生模型不仅学习训练数据的标签,还学习教师模型的“软标签”(即模型输出的概率分布)以及中间层的特征表示等更丰富的知识。
实践案例:
- DistilBERT: 是一个通过蒸馏 BERT 模型得到的更小、更快的 Transformer 模型,它在保持 BERT 较高性能的同时,参数量减少了约 40%,速度提升了约 60%。
- TinyBERT: 通过更精细的蒸馏策略,进一步减小了 BERT 的模型尺寸,并提升了推理速度。
知识蒸馏训练流程 (简化说明):
- 准备教师模型和学生模型: 教师模型是一个已经训练好的大型模型,学生模型是一个结构更小、参数更少的模型。
- 准备训练数据: 使用与训练教师模型相同或类似的数据。
- 教师模型生成软标签: 使用教师模型对训练数据进行预测,得到包含更丰富信息的概率分布(软标签),通常通过调整教师模型的输出温度参数来实现。
- 学生模型学习软标签和硬标签: 学生模型在训练过程中,不仅学习真实标签(硬标签),还学习教师模型生成的软标签。通常会使用一个结合了学生模型预测与硬标签损失以及学生模型预测与教师模型软标签损失的联合损失函数。
- 训练学生模型: 使用优化器(如 Adam)迭代更新学生模型的参数,使其能够更好地模仿教师模型的行为。
5.4 算子融合与编译优化:原理与框架应用
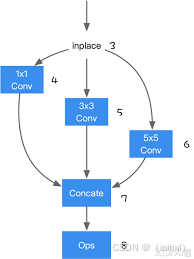
基本概念与优势:
- 算子融合 (Operator Fusion): 将计算图中相邻的多个小算子合并成一个或几个较大的算子。
- 优势: 减少了 kernel launch 的开销,因为启动一个 kernel 需要一定的系统开销。提高了数据局部性,减少了中间结果在内存中的存储和传输。
- 编译优化 (Compiler Optimization): 推理引擎(如 ONNX Runtime、TensorRT、TVM)会对计算图进行分析和优化,例如进行常量折叠、死代码消除、算子重排序、选择最优的 kernel 实现等。
性能提升原因: 算子融合通过将多个相邻的小算子合并为一个或几个大的算子,可以显著减少计算过程中的开销。具体来说:
- 减少 Kernel Launch 开销: 在 GPU 等加速器上,每次执行一个算子都需要启动一个 Kernel。频繁地启动小 Kernel 会带来显著的延迟。算子融合减少了 Kernel 的启动次数,从而降低了延迟。
- 提高数据局部性: 融合后的算子可以在内部完成多个计算步骤,而无需将中间结果写回全局内存。这提高了数据的局部性,减少了对内存的访问,从而提升了性能。
- 减少中间结果的存储和传输: 多个小算子产生的中间结果可能需要存储在内存中,并在后续的算子中使用。算子融合可以直接在融合后的算子内部传递这些中间结果,减少了内存的占用和数据传输的开销。
使用 ONNX Runtime 进行优化 (代码示例):
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
import onnxruntime
# 1. 加载 PyTorch 模型和 tokenizer
model_name = "Qwen/Qwen2-7B-Chat" # 替换为 Qwen2.5 模型
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True).eval() # 注意部分模型可能需要 trust_remote_code=True
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
# 2. 导出为 ONNX 格式
dummy_input = tokenizer("This is a test.", return_tensors="pt")["input_ids"]
torch.onnx.export(model,
dummy_input,
"gpt2.onnx",
opset_version=13)
# 3. 使用 ONNX Runtime 加载和优化模型
ort_session = onnxruntime.InferenceSession("gpt2.onnx", providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
# 4. 运行推理
prompt = "The future of AI is"
input_ids = tokenizer.encode(prompt, return_tensors="pt").numpy()
ort_inputs = {'input_ids': input_ids}
ort_outputs = ort_session.run(None, ort_inputs)
print(tokenizer.decode(ort_outputs[0][0], skip_special_tokens=True))
5.5 实操:选择并应用一种或多种模型优化技术,评估性能提升并分析精度损失
在本章的最后,我们鼓励读者选择一个或多个我们讨论过的模型优化技术,并将其应用到之前章节中使用过的 LLM 模型上。
您可以尝试以下组合:
- 在第三章 KV 缓存优化的基础上,对模型进行 INT8 量化,观察推理速度是否进一步提升。
- 对一个较小的 Transformer 模型(例如 DistilBERT)进行剪枝,并评估剪枝率和精度损失之间的关系。
- 尝试将一个 PyTorch 训练的 LLM 模型导出为 ONNX 格式,并使用 ONNX Runtime 进行推理,比较优化前后的性能差异。
评估性能提升时,可以关注以下指标:
- 推理延迟 (Latency): 生成一个 token 或完成整个序列所需的时间。
- 吞吐量 (Throughput): 单位时间内可以处理的请求数量或生成的 token 数量。
- 模型大小 (Model Size): 模型在磁盘或内存中占用的空间。
分析精度损失时,需要根据具体的任务类型选择合适的评估指标:
- 文本分类: 准确率 (Accuracy)、F1 值等。
- 问答: 精确匹配率 (Exact Match)、F1 值等。
- 文本生成: BLEU、ROUGE、Perplexity 等。
通过实际操作,您可以更直观地理解各种模型优化技术带来的性能提升和可能的精度损失,从而在实际应用中做出更明智的选择。
总结:
本章介绍了超越 KV 缓存的多种模型优化技术,包括模型量化、剪枝、知识蒸馏以及算子融合与编译优化。这些技术各有特点和适用场景,可以单独或组合使用,以在模型大小、推理速度和精度之间达到最佳的平衡。掌握这些技术对于在资源受限的环境中部署和高效运行大型语言模型至关重要。
内容同步在我的微信公众号 智语Bot



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











