




在电商数据抓取领域,淘宝作为国内最大的电商平台之一,其数据的获取一直是众多开发者关注的焦点。item_search_shop 接口作为获取淘宝店铺所有商品信息的重要工具,为我们在数据分析、竞品研究等方面提供了有力支持。今天,就和大家详细分享一下这个接口的使用方法及相关技术要点。
接口基本介绍
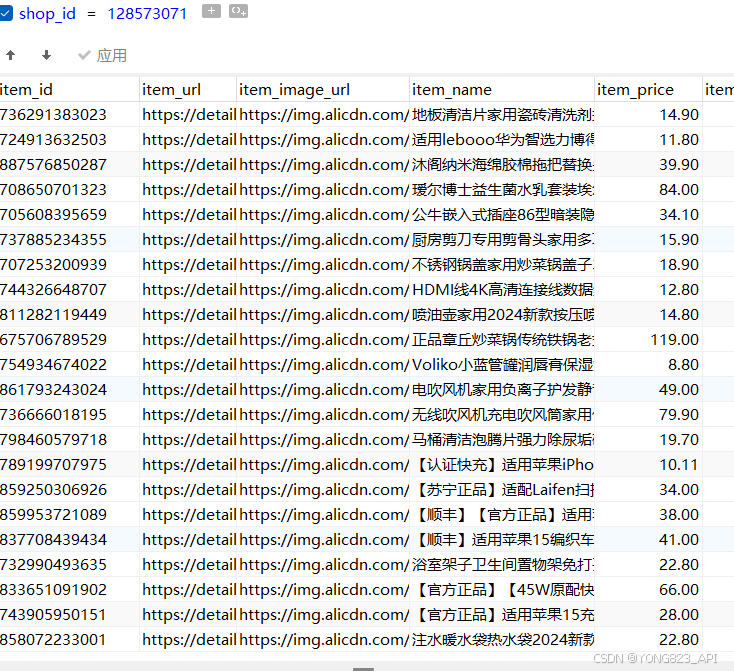
item_search_shop 接口的主要功能是根据输入的淘宝店铺 ID,返回该店铺内所有商品的基本信息。这些信息涵盖了商品名称、价格、销量、商品链接、图片链接等关键数据,为我们全面了解店铺商品情况提供了基础。
接口调用参数详解
- 店铺 ID 参数(shopid):这是调用该接口的核心参数,准确无误地输入目标店铺的 ID 是成功获取数据的前提。店铺 ID 可以通过淘宝店铺链接获取,例如某店铺链接为 “店铺浏览-淘宝网”,其中 “xxxx” 即为店铺 ID。
- 分页参数(page):由于一个店铺的商品数量可能较多,接口采用分页返回数据。通过设置 page 参数,可以指定获取第几页的数据。每页返回的数据量通常有默认值,开发者可根据实际需求进行调整,但需注意不要超过接口限制,以免影响数据获取。
- 其他可选参数:接口还可能提供一些其他可选参数,如按商品类目筛选、按价格区间筛选等。合理运用这些参数,可以更精准地获取我们所需的数据,提高数据处理效率。
接口调用示例代码(以 Python 为例)
# coding:utf-8
# 注册key:https://o0b.cn/ijenni
"""
Compatible for python2.x and python3.x
requirement: pip install requests
"""
from __future__ import print_function
import requests
# 请求示例 url 默认请求参数已经做URL编码
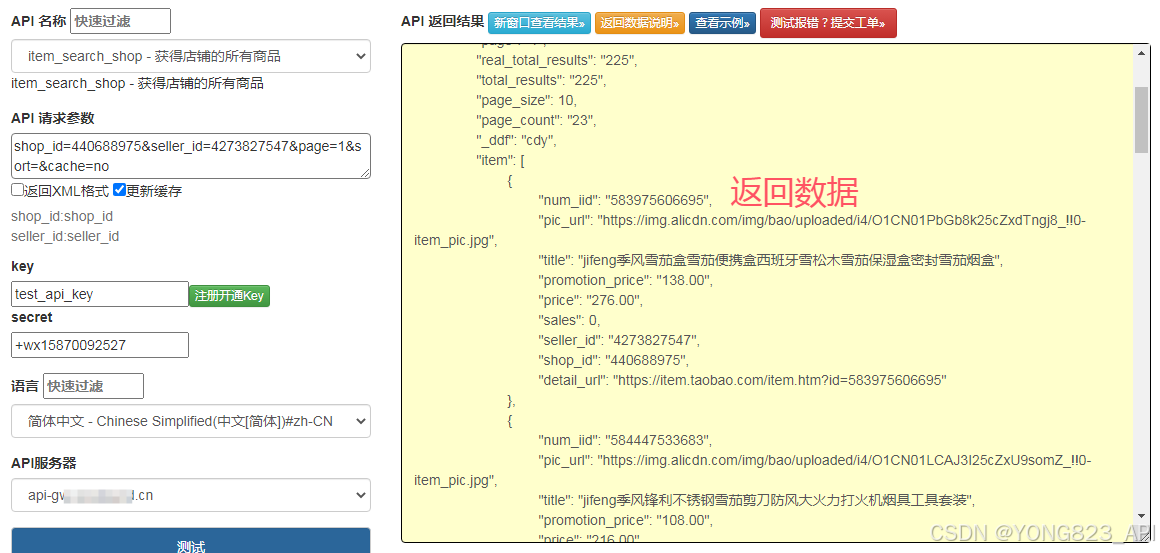
url = "https://api-gw.onebound.cn/taobao/item_search_shop/?key=<您自己的apiKey>&secret=<您自己的apiSecret>&shop_id=440688975&seller_id=4273827547&page=1&sort="
headers = {
"Accept-Encoding": "gzip",
"Connection": "close"
}
if __name__ == "__main__":
r = requests.get(url, headers=headers)
json_obj = r.json()
print(json_obj)
在上述代码中,首先定义了接口地址和请求参数,其中 “your_api_key” 需要替换为实际申请到的 API 密钥。通过发送 GET 请求获取数据,并使用 json 模块将返回的文本数据解析为 Python 字典格式,方便后续处理。
数据解析与处理
接口返回的数据通常是 JSON 格式,我们需要对其进行解析,提取出有用的信息。以商品名称、价格和销量为例:
for item in data["items"]:
item_name = item["title"]
item_price = item["price"]
item_sales = item["sales"]
print(f"商品名称: {item_name}, 价格: {item_price}, 销量: {item_sales}")
这段代码遍历返回数据中的 “items” 列表,逐一提取每个商品的名称、价格和销量信息,并进行打印输出。在实际应用中,我们可以将这些数据存储到数据库或进行进一步的数据分析。
注意事项
- API 使用频率限制:为了保证接口的稳定性和公平性,平台通常会对 API 的使用频率进行限制。开发者在使用 item_search_shop 接口时,要注意控制调用频率,避免因频繁调用而导致账号被封禁或接口请求失败。
- 数据准确性与时效性:淘宝平台上的商品信息可能随时发生变化,因此获取到的数据具有一定的时效性。在使用数据进行分析或其他应用时,要考虑到数据的更新频率,必要时定期重新获取数据,以确保数据的准确性。
- 合法性与合规性:在使用爬虫 API 获取淘宝数据时,务必遵守相关法律法规和平台规定。未经授权的恶意抓取行为可能会侵犯平台和商家的权益,给自己带来法律风险。建议在使用前仔细阅读平台的开发者文档和相关条款,确保合法合规使用接口。
item_search_shop 接口为我们获取淘宝店铺商品信息提供了便捷途径,但在使用过程中需要注意参数设置、数据解析、频率控制等多方面的问题。希望通过本次分享,能帮助大家更好地运用这个接口,在电商数据抓取与分析工作中取得更好的成果。


















 2281
2281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









