




 这篇博客详细介绍了C++中的快速排序算法,包括其分治思想、例子、代码实现以及复杂度分析。在时间复杂度方面,讨论了最好、最坏和平均情况,并指出在平均情况下快速排序的时间复杂度为O(nlogn)。此外,文章还探讨了如何通过优化基准元素选取、递归操作以及针对小数组的排序策略来提升快速排序的性能。
这篇博客详细介绍了C++中的快速排序算法,包括其分治思想、例子、代码实现以及复杂度分析。在时间复杂度方面,讨论了最好、最坏和平均情况,并指出在平均情况下快速排序的时间复杂度为O(nlogn)。此外,文章还探讨了如何通过优化基准元素选取、递归操作以及针对小数组的排序策略来提升快速排序的性能。
快速排序算法
快速排序是实际中最常用的一种排序算法,速度快,效率高。
思想:快速排序采用的是分治的思想
(1)在待排序的元素中任取一个元素作为基准(通常选第一个元素,但是最好的选择方法是从待排元素中随机选取一个作为基准),成为基准元素;
(2)将待排的元素进行分区,比基准元素大的元素放在它的右边,比它小的元素放在左边;
(3)对左右两个分区重复以上步骤直到所有的元素都是有序的。
举例说明
原始待排序列:3 6 4 2 1 8 5 7
选择第一个元素3作为基准元素,然后设置两个指针 i(绿色) 和 j(红色) 分别指向第一个元素和最后一个元素,然后开始从两边扫描,把比3大的元素和比3小的元素分开。
(1)首先比较3和7,3<7,j 向左移动: 3 6 4 2 1 8 5 7
(2)比较3和5,3<5,j 继续向左移动: 3 6 4 2 1 8 5 7
(3)比较3和8,3<8,j 继续向左移动: 3 6 4 2 1 8 5 7
(4)比较3和1,3>1,把1放在i的位置,此时从i+1处开始向右进行扫描: 1 6 4 2 1 8 5 7
(5)比较3和6,3<6,把6放在j的位置,此时从j-1处开始向左进行扫描: 1 6 4 2 6 8 5 7
(6)比较3和2,3>2,把2放在i的位置,此时从i+1处开始向右进行扫描: 1 2 4 2 6 8 5 7
(7)比较3和4,3<4,把4放在j的位置,此时从j-1处开始向左进行扫描: 1 2 4 4 6 8 5 7
由于此时不满足j>i的循环条件,循环结束,
(8)将基准元素放在i的位置上: 1 2 3 4 6 8 5 7
经过第一轮的快速排序之后,元素变为 [1 2] 3 [4 6 8 5 7]
(9)之后,递归的对3左半部分的元素和右半部分的元素进行快速排序,生成最终的排序结果。
代码实现
#include <iostream>
#include <vector>
using namespace std;
//快速排序法时间复杂度,最好情况下O(nlog2(n)),最坏为O(n*n),平均为O(nlog2(n));空间复杂度为O(log2(n)),递归排序,需要栈辅助。
//序列越无序,算法效率越高,越有序,算法效率越低
void QuickSort(vector<int> &R, int l, int r) //对从R[l]-R[r]的元素进行排序
{
int temp;
if (l < r)
{
int i = l;
int j = r;
temp = R[l];
//下面的循环完成一次排序,即以第一个元素为轴,将大于temp的元素放在右边,小于temp的元素放在左边
while (i < j)
{
while (j > i&&R[j] > temp) //从右往左扫描到第一个小于temp的元素
j--;
if (j > i)
{
R[i] = R[j]; //放在temp左边
++i;
}
while (i < j&&R[i] < temp) //从左往右扫描到第一个大于temp的元素
++i;
if (i < j)
{
R[j] = R[i]; //放在temp的右边
--j;
}
}
R[i] = temp; //将temp放在最终的位置上
QuickSort(R, l, i - 1); //递归地对temp左边的元素排序
QuickSort(R, i + 1, r); //递归地对temp右边的元素排序
}
}
void main()
{
vector<int> R = { 3, 6, 4, 2, 1, 8, 5, 7 };
QuickSort(R, 0, R.size() - 1);
for (auto x: R)
cout << x << " ";
cout << endl;
}
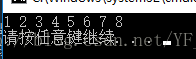
运行结果如下:
复杂度分析
(1)时间复杂度
- 最好情况下的时间复杂度为O(nlogn),待排序列越接近无序,本算法的效率越高。
- 最坏情况下的时间复杂度为O(n^2),待排序列越接近有序,本算法效率越低。
- 平均时间复杂度为O(nlogn)。就平均时间而言,快速排序是所有排序算法中最好的。
(2)空间复杂度
空间复杂度为O(logn)。因为快速排序是递归排序,递归需要栈的辅助。
扩展:快速排序算法当序列中元素的排列比较随机时效率最高,但是当序列中元素接近有序时,会达到最坏的时间复杂度O(n^2),产生这种情况的主要原因在于基准元素的选择没有把当前区间划分为两个长度接近的子区间。有什么办法能解决这个问题呢???其中一个办法就是随机选择一个元素最为基准元素,这样虽然算法的最坏时间复杂度仍然是O(n^2),但是对任意输入数据的期望时间复杂度都能达到O(nlogn),也就是说,不存在一组特定的数据能使这个算法出现最坏情况。
优化
1. 优化基准元素的选取
上面的代码中我们默认以第一个元素作为基准元素,如果基准元素处于整个有序序列的中间位置,那么它可以将序列分割均衡,但是如果不是中间位置,比如第一个位置,则时间复杂度将会是最坏的情况。因此我们可以对基准元素的选择进行改进
- 三数取中法:左端、右端和中间三个元素的中间数据,也可以随机选三个数(但考虑随机生成器也有时间开销,随机法可以不考虑)
- 九数取中法:数组中分三次取样,每次取三个元素,每次取样中选取中间数,然后从三个中间数中再选取中间数作为基准元素
2. 优化递归操作
我们知道,递归对性能有一定的影响,快速排序法在尾部进行了两次递归操作,如果序列划分极不均衡,递归深度将趋近于n,而不是平衡时的logn,这时就不仅仅是快慢的问题了,因为递归要用到栈,栈的大小是有限制的。因此如果能减少递归,性能将会有很大的提升。
- 尾递归法:
#include<iostream>
#include <vector>
using namespace std;
//快速排序法时间复杂度,最好情况下O(nlog2(n)),最坏为O(n*n),平均为O(nlog2(n));空间复杂度为O(log2(n)),递归排序,需要栈辅助。
//序列越无序,算法效率越高,越有序,算法效率越低
void QickSort(vector<int> &R, int l, int r) //对从R[l]-R[r]的元素进行排序
{
int temp;
// 此处if换成了while循环
while (l < r)
{
int i = l;
int j = r;
temp = R[l];
//下面的循环完成一次排序,即以第一个元素为轴,将大于temp的元素放在右边,小于temp的元素放在左边
while (i != j)
{
while (j > i&&R[j] > temp) //从右往左扫描到第一个小于temp的元素
j--;
if (j > i)
{
R[i] = R[j]; //放在temp左边
++i;
}
while (i < j&&R[i] < temp) //从左往右扫描到第一个大于temp的元素
++i;
if (i < j)
{
R[j] = R[i]; //放在temp的右边
--j;
}
}
R[i] = temp; //将temp放在最终的位置上
QickSort(R, 1, i - 1); //递归地对temp左边的元素排序
l = i +1; //循环对temp右边的元素排序
}
}
当我们将if改成while后,因为第一次递归以后,遍历l就没有用处了,所以将i+1赋值给l,再循环后,快速排序(R, l, r),其效果等同于QSort(R, i+1, r);。结果相同,但因采用迭代而不是递归的方法可以缩减堆栈深度,从而提高整体的性能。说白了就是前半部分依然采用递归方式,而后边部分采用循环方式依次拆分并对前半部分进行递归排序。
3. 优化小数组时的排序方案
当数组非常小时,其实快速排序反而不如直接插入排序效率更高(直接插入是简单排序中性能最好的),其原因就在于快速排序采用了递归操作,在大量数据排序时,这点性能影响相对于它整体算法优势而言可以忽略。但如果数组只有几个记录需要排序时,这就有点大材小用了。因此可以改进下QSort函数,当r-l不大于某个常数时,就直接用插入排序,这样就能保证最大化的利用两种排序的优势来完成工作


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









