






老师今天给我们讲了爬虫,现在来记录一下是怎么操作的
先说说爬虫概念吧!
爬虫:
网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟浏览器发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。
原则上,只要是浏览器(客户端)能做的事情,爬虫都能够做。
爬虫准备工作:
1.首先你电脑上必须要有python,我下载的是官方的python3.8.8
2.其次我们需要一个运行Python的环境,我用的是pychram
3.我们还需要一些库来支持爬虫的运行(有些库Python可能自带了)
例如:jieba库、beautifulsoup库、requests库(这些都需要在电脑上安装),教程如下:
打开你的cmd,然后输入pip install jieba、pip install bs4/beautifulsoup4、pip install requests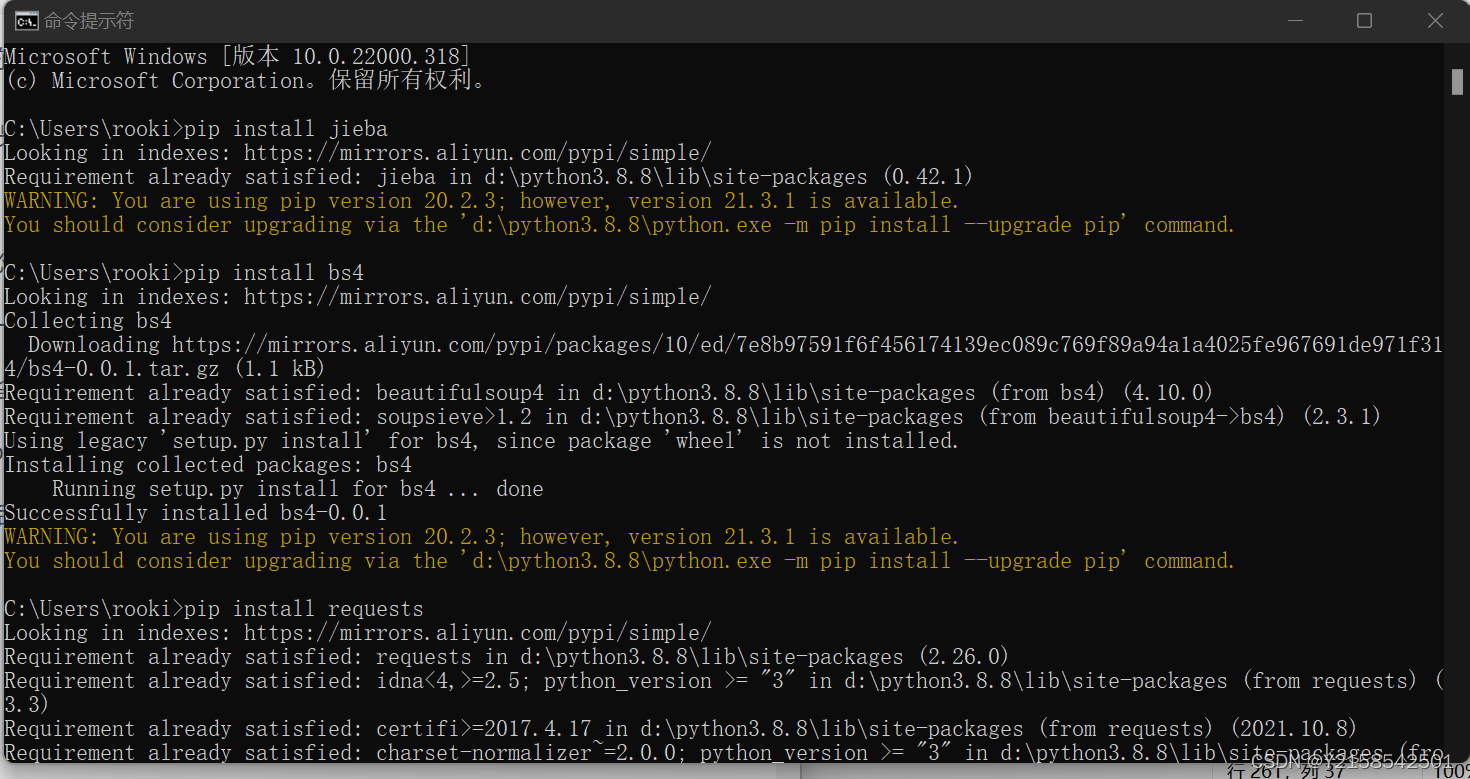
我的这个是安装好的,你们首次安装就不会直接出现这种,但等它安装好就会和我的一样。
4.最后打开你的 IDLE,开始敲代码:

代码如下:

运行如下:资源对象我用了百度。
中间r.text[-500:]是指在整个网页内容中从后往前看,反过来r.text[:1000]指指在整个网页内容中从前往后看
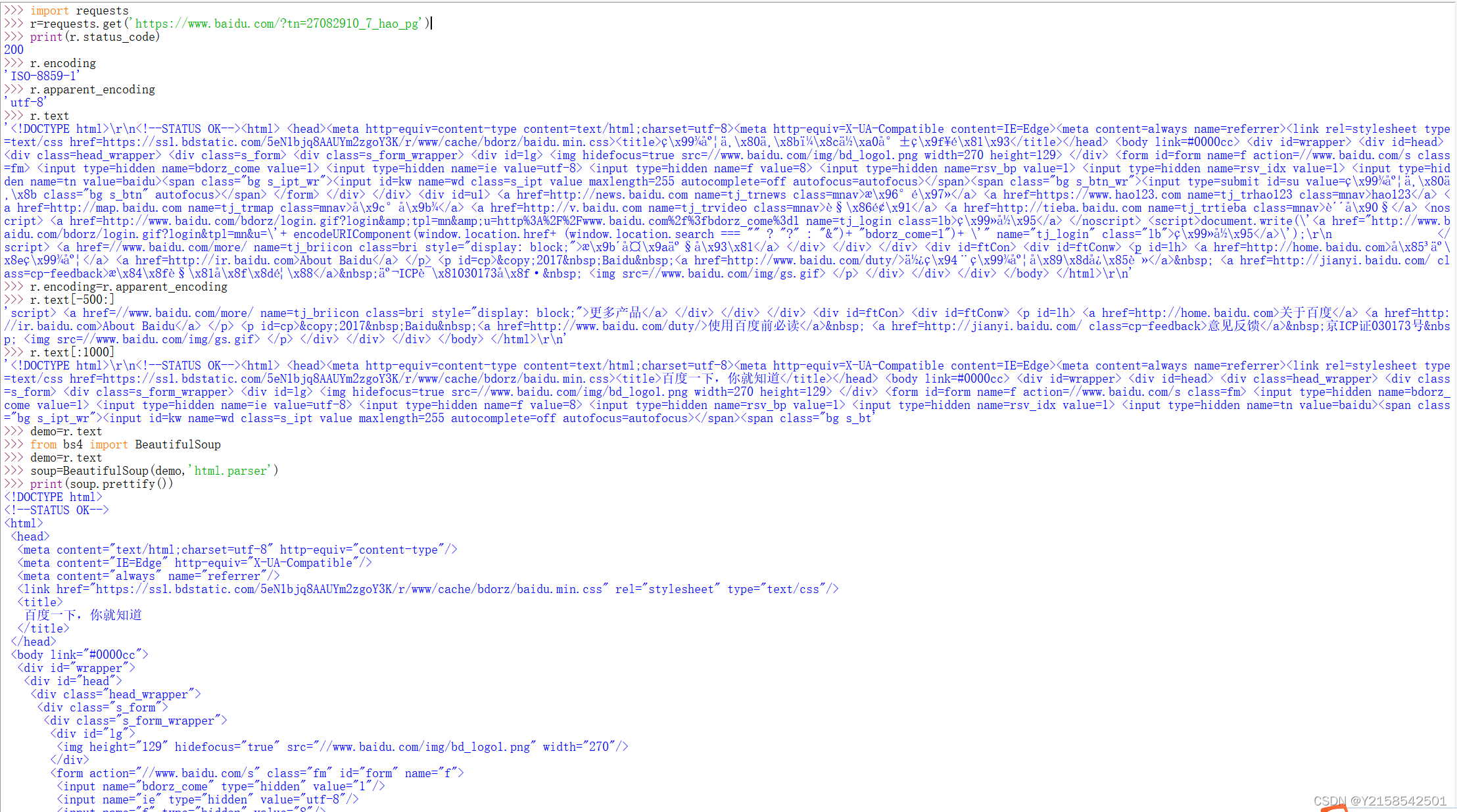
okok, 这样就意味着我们爬虫成功了!!!
感兴趣的可以试一试哦,还是挺有趣的!

















 1695
1695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









