



作者丨蛤蟆仙人、小米君、留德华叫兽
来源丨知乎问答
编辑丨极市平台
本文均经过原作者授权,未经允许不得任意转载。
导读
宅实验室专心科研的生活自由但无硬核的工作像是在空中跳舞,学术界人才济济而职称的坑位少,大家相见即交锋。面对这样的环境感觉到现实非常的残酷,那么工业界又是怎样的一种状态呢?来听听大家对于该问题的看法吧~ >
原问题:鄙人能源类工科博士在读,正在面临工业界和学术界的抉择,想知道两者的区别,以便提前做好准备。科研状态自我感觉挺舒适,习惯了自由自在,没有太大约束的生活,但是感觉自己做的东西浮在空中,落地会摔粉碎。学术圈目前应该是越来越难了吧,人才多,评职称艰难。隔壁实验室的讲师每天走得比我还晚(一般12点走),所以很想知道工业界又是怎么样一种状态?
问题链接:https://www.zhihu.com/question/332602866
# 回答一
作者:蛤蟆仙人
来源链接:
https://www.zhihu.com/question/332602866/answer/2145469028
我的背景更偏学术界,我对两边都有了解,我谈一点自己粗浅的看法。我的讨论范围限定在(1)机器学习领域,(2)能力在前10%~50%的正常人,不讨论改变世界的大神。
简单粗暴的结论:
(1)高校的研究能力在工业界很有用,但是高校的成果几乎(99.9%)在工业界都没有用。或许高校的education的作用更大,期望高校做出改变工业界的学术成果不太现实。
(2)工业界的研究院其实属于学术界,本质跟高校区别不大。他们比高校做的东西更有用,但是研究院做的不是核心技术,只是外围、边缘的技术而已。
先说说高校的科研。 高校绝大多数的研究都是各种问题的corner case,在公开的数据集上跑几个实验,claim自己是SOTA,发篇论文。但这些东西在工业界用途非常非常小。我举几个例子。
近年来学术界搜索、推荐的论文不少,但在工业界能用的几乎没几个。学术界的做法是“改进模型,在MovieLens等数据集上做个实验,提升几个点,发表论文”。但学术界的成果在工业界几乎都不work。在工业界真正能改进模型效果的方法大多是标注数据、处理数据、调特征、修bug。少数能用的学术成果都是Google等公司发表的。
最近几年联邦学习很热门,每个会议都有上百篇联邦学习的投稿。这些文章中90%以上都是在解决corner case,比如XXX设定下的收敛、XXX设定下的XXX差分隐私方法、用XXX方法防御XXX假设下的拜占庭错误。有脚指头想想也知道,这些corner case在工业界是没有用的。工业界用的是简单、好调、scalability能上得去的方法,而且要考虑自身系统平台的支持。
最近一两年,有N篇基于vision transformer的论文,都是对vision transformer做一点改进,在公开数据集上top-1 accuracy提升一点点。在绝大多数工业应用里面,没人在乎一点点准确率的提升。好好处理数据、标注数据、再加点小trick,带来的提升比模型大得多。说实话,ResNet之后所有的模型带来的提升全加起来,还没JFT一个数据集带来的提升多。
工业界里重要的问题非常多,但是没有足够的人力去解决,只能挑收益最大的做。而高校乌央乌央的人扎堆挤到一些很小的问题上,研究各种各样的corner case,比如上面讨论的几个问题。这就是为什么我打算离开高校。
再说说工业界的研究院。
工业界研究院有一部分人做纯科研,做出了非常牛逼的工作。Google、Deepmind、MSR、NVIDIA等公司的研究院都有非常厉害的成果。Transformer、AlphaGo这些成果确实改变了世界。其余影响力小一些的论文也起到了PR的作用。
工业界研究院有相当多的人在为业务、技术部门服务。可惜的是研究院做的通常不是核心技术,而是可有可无的边缘技术。研究院的人看不到完整的核心技术。举几个例子:
推荐算法团队跟研究院合作,希望“试一试”强化学习、图神经网络这些技术。重点在“试一试”,也就是说可有可无,不是核心技术。能带来零点几个点的增长最好,没有也无所谓。
技术部门发现强化学习在网约车派单上好用,收益挺大。上线之后,让研究院做进一步的探索,目标是用更fancy的技术取得marginal improvement。
为什么工业界研究院接触不到完整的、核心的技术?核心技术肯定在业务部门手里,重要性次一级的工具在技术中台手里。由于利益原因,没人愿意把自己重要的东西交给别人做,除非是自己不愿做、没精力做、没能力做。
说一下工业界的技术团队。 工业界的工作并不美好,有很多脏活累活要干,没有学术界看起来高大上,而且KPI压力很大。有一部分人在推着技术走,这种工作的成就感会比较高。另一部分人被业务推着走,比如这个地方掉点了,那个地方有个bad case,要修一下。。。很明显,前者的技术含量高,成长更快,在就业市场上很抢手;后者的技术含量低,是高档人肉电池,容易被换掉。
最后说说人。 学术界的人才密度远远大于工业界。拿到985学校的讲师(所谓助理教授)职位,比公司SP offer还难。工业界研究院里各个都是有不错成果的博士。而工业界的技术部门里,人才密度低得多。哪里更容易出头是显而易见的。在跳槽的时候,研究院出身的不那么受欢迎,跟核心技术团队的人差距巨大。
# 回答二
作者:小米君
来源链接:
https://www.zhihu.com/question/332602866/answer/2139752924个人观点:学术界就像谈恋爱,有不错的motivation和idea你只用锻造技术去给一个solution就完了,最后呈现的方式是publication。你可以更自由,可以天马行空,可以各种魔改,甚至不需要考虑落地成为一个paperer守着ppt过一辈子。
工业界就是结婚过日子,柴米油盐,衣食住行,你就不得不考虑商业化和市场,平衡各方利益,调动各种资源上下游的关系。有这个idea的可能很多,但是你可以做出实打实得产品,并将其推给用户,为该领域起到推动作用,这就不是简单的publication可以呈现的。同样,没有爱情的婚姻质量不高,没有重大innovation支撑的产品也不长久。
总之,paper 不代表一切~却是一切美好的开始……
多加几句:从社会责任的角度来看,不以结婚为目的的谈恋爱都是耍流氓,婚姻里连流氓都不愿意耍的是搭伙过日子,只是完成国家规定的结婚kpi,给娃(产品)上户口。
# 回答三
作者:留德华叫兽
来源链接:https://www.zhihu.com/question/332602866/answer/2146972009
学术界水了5年,工业界摸鱼了3年,谈谈我的浅见(IT、人工智能)。
一、工程能力、数据之于业界的重要性
当你进入到工业界会发现,原来世界500强公司的机器学习团队也大都只是Git clone市面上开源的代码,调整一些参数/用自己的数据集训练,有那么几个复现能力强的算法工程师,足矣。。
不同深度学习模型在大数据燃料的驱动下,差别几乎可以忽略。
相反,学术界take for granted的数据集才是工业界的命脉,得数据者得天下,对于互联网公司更是如此。

标注一张语义分割图片需要1个小时
标注一张语义分割图片需要1个小时,相比花里胡哨的深度学习模型,业界更需要海量大数据收集/管理/读取/active learning的能力、把算法工程(产品)化的能力、算法写进板子的能力、软件开发和迭代的能力以及ppt和有效沟通的能力。
二、 产品才是业界的核心
如果说学术界KPI是顶刊和引用数,那么业界的KPI便是尽量提升用户数和满意度
企业最终卖的是产品和解决方案,而算法只是其中很小的一部分。并且对于大多数中小企业来讲是很微不足道的部分,而大头都是软件开发相关,什么前端、后端、美工、产品经理--这也是作为数学建模、算法出身的我最近几年才认识到的“残酷”现实。
开发才是业界的刚需!
设想一个做导航软件的小公司,导航软件里最核心的算法便是@运筹OR帷幄 最经典的最短路径算法。但作为用户,你最关心的导航软件一定是它的UI(用户操作界面)以及支持的功能(例如是否有限速提醒、探头提醒等),还有数据库(是否导航中的信息足够详尽和精确),算法部分只要够用就行。
作为用户,你会不会打开俩个导航软件对比哪个软件的线路更短、用时更快?比如搜索一段路径:百度地图给出的路径长53.5公里、用时52分钟,而腾讯地图给出的路径长53.7公里、用时56分钟。
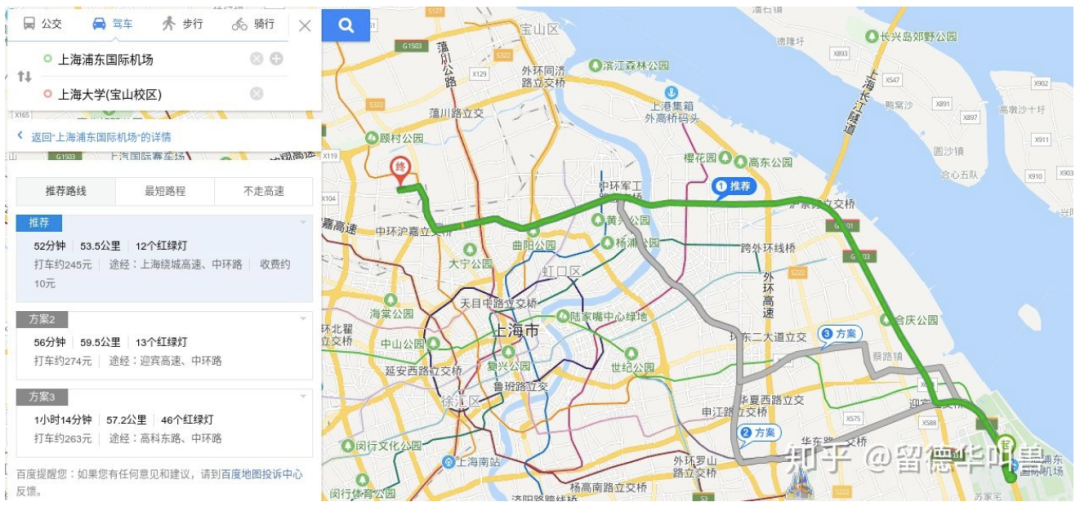
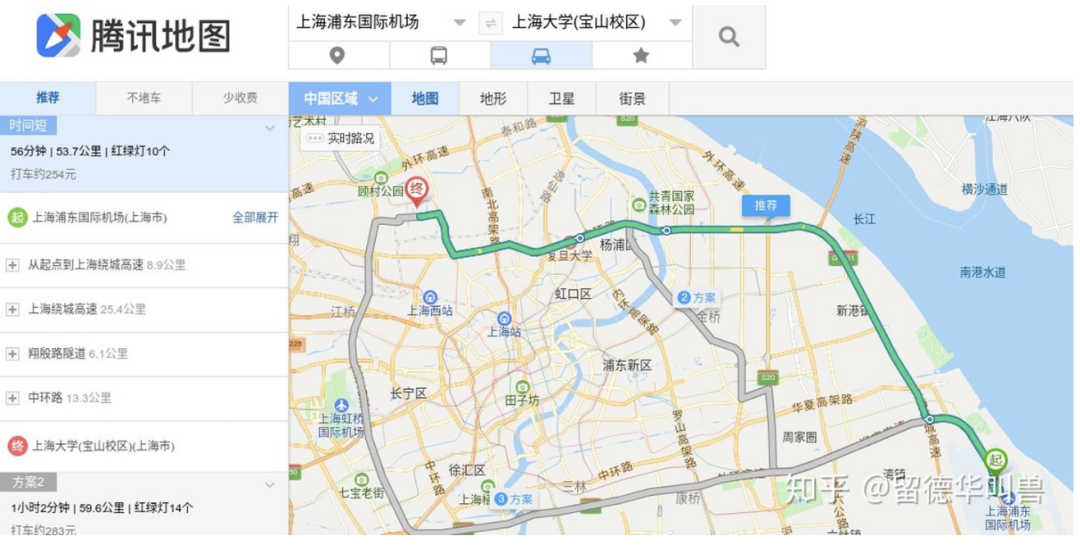
而作为用户的你,是因为这多出来的0.2公里和4分钟才选择的百度而不是腾讯么?因此(中小)公司宁愿选择砸钱雇很多前端(UI、美工设计师)也不愿花钱雇第二个运筹学算法工程师。只有那些头部大厂才舍得花钱砸算法工程师去改进算法提升那么一点点的软件运行效率
而当公司面临财务危机的时候,第一批卷铺盖走人的也肯定是算法工程师(或研发科学家),毕竟他们工资高得吓人。
三、为别人打工 VS 为自己打工
学术界即使博士后、青椒,毕竟发的文章署名是自己的,多半还是在为自己打工,因此即使007也心甘情愿。
然而残酷的事实是学术界卷得厉害,007也不一定能换来终身教职并且还得饱受清贫之苦。为了所谓的学术理想是否值得,是需要深思的。
工业界就不一样的,国内996大厂好歹有加班补贴。作为码农按时计费,超一小时就要算上一小时的钱或者绩效那边补上(奖金)。欧洲这边则是965每周工作40小时,到点下班、加班一小时都不可能。
感激博士毕业求职季把我拒掉的两个博后岗位,让我提前脱离“苦海”,提前“上岸”,成为了快乐的德国“摸鱼”人。
觉得还不错就给我一个小小的鼓励吧!
















 2125
2125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









