



 本文介绍了Selenium作为爬虫和自动化测试工具的使用。首先讲解了Selenium的安装步骤,包括安装库和配置Chrome WebDriver。接着阐述了网页元素定位的多种方法,如通过属性值或HTML路径。最后,通过实例展示了Selenium如何进行网页操作,如点击和输入,并提到了在爬虫中设置请求头以应对反爬策略。文章还提及作者建立的交流群和相关主题的直播活动。
本文介绍了Selenium作为爬虫和自动化测试工具的使用。首先讲解了Selenium的安装步骤,包括安装库和配置Chrome WebDriver。接着阐述了网页元素定位的多种方法,如通过属性值或HTML路径。最后,通过实例展示了Selenium如何进行网页操作,如点击和输入,并提到了在爬虫中设置请求头以应对反爬策略。文章还提及作者建立的交流群和相关主题的直播活动。

Tango,目前就职在一家对日开发的的IT服务公司。 不是科班出身的我,出于对编程的热爱,自学了软件开发。 从此深深陷入在代码的世界而无法自拔。编辑:王老湿
我们的专栏发布后,目前已经更新了 10 篇:
它发展至今,不仅在自动化测试领域占据重要位置,并且在爬虫上也应用广泛。接下来我们一起看看它是如何应用在爬虫上的。
安装Selenium
我们这里以谷歌浏览器为例。
在搭建Selenium开发环境时,我们需要安装Selenium库并且配置谷歌浏览器的WebDriver。
通过如下命令安装:
pip install selenium
安装成功后我们在CMD环境下验证是否安装成功。
import selenium
selenium.__version__
在浏览器中输入:chrome://settings/help
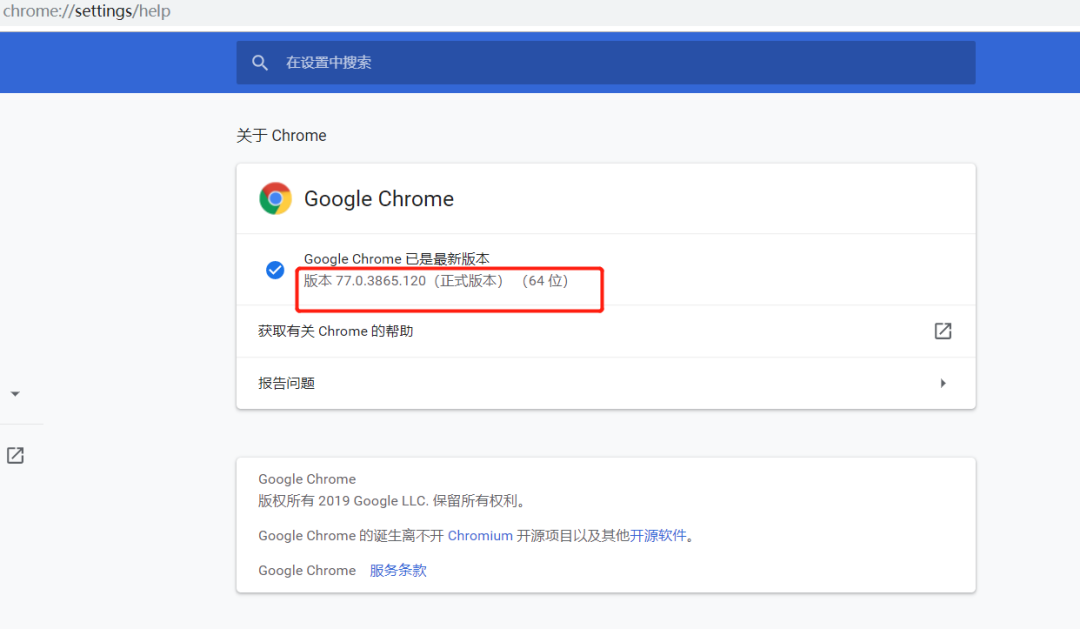
就可以看到当前浏览器的版本。然后到 http://chromedriver.storage.googleapis.com/index.html 这个网站下载与其对应的程序。

最后的小版本不一致影响不大。
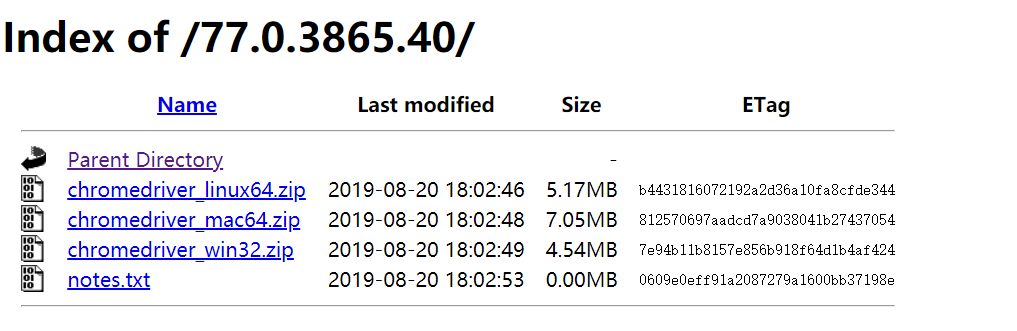
下载与自己操作系统一致的zip文件解压。放到一个自己不会删除的地方。
到现在为止,我们的环境就算是配置完成了,接下来我们写段代码验证一下:
# 导入Selenium的webdriver类
from selenium import webdriver
# 设置url变量保存要访问的网站
url = "https://www.baidu.com"
# 将webdriver类实例化,将浏览器设置为谷歌
# 参数executable_path是我们chromedriver.exe的路径
path = r"F:\chromedriver.exe"
browser = webdriver.Chrome(executable_path=path)
# 打开浏览器并访问目标网站
browser.get(url)
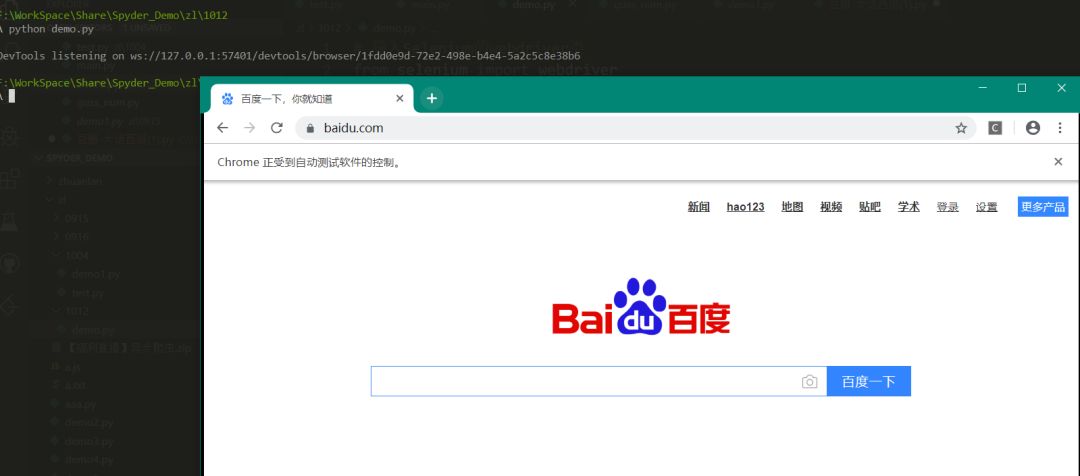
运行脚本,如果看到一个自动打开的网站就说明我们的环境搭建成功了。
网页元素定位
Selenium定位网页元素主要通过元素属性值或者元素在HTML里的路径位置,定位方式一共有如下8种:
# 通过属性id和name来定位
find_element_by_id()
find_element_by_name()
# 通过HTML标签类型和属性class定位
find_element_by_class_name()
find_element_by_tag_name()
# 通过标签值实现定位,partial_link用于模糊匹配
find_element_by_link_text()
find_element_by_partial_link_text()
# 通过元素的路径定位
find_element_by_xpath()
find_element_by_css_selector()
我们除了获取网页的内容之外,有时还需要页面上进行点击或者输入等操作。最常用的有:
click:鼠标点击
send_keys:输入文本
除了这两个之外还有很多,大家可以自行在网上搜索一下,没必要都记住,在实际开发中遇到了上网搜索一下就好。
在爬虫中我们通常通过chrome_options参数为请求添加请求头,以防被反爬:
# 导入Selenium的webdriver类
from selenium import webdriver
# 导入Options类
from selenium.webdriver.chrome.options import Options
# Options实例化
chrome_options = Options()
# 设置浏览器参数
chrome_options.add_argument('--headless')
chrome_options.add_argument('lang=zh_CN.UTF-8') # 根据目标网站要修改
chrome_options.add_argument('User-Agent=xxxxxx') # xxxxxx是你的请求头
# 启动浏览器,并添加请求头
driver = webdriver.chrome(chrome_options = chrome_options)
实例
from selenium import webdriver
import codecs
pageMax = 2 #爬取的页数
saveFileName = 'proxy.txt'
class Item(object):
ip = None #代理IP地址
port = None #代理IP端口
anonymous = None #是否匿名
protocol = None #支持的协议http or https
local = None #物理位置
speed = None #测试速度
uptime = None #最后测试时间
class GetProxy(object):
def __init__(self):
self.startUrl = 'https://www.kuaidaili.com/free'
self.urls = self.getUrls()
self.getProxyList(self.urls)
self.fileName = saveFileName
def getUrls(self):
urls = []
for word in ['inha', 'intr']:
for page in range(1, pageMax + 1):
urlTemp = []
urlTemp.append(self.startUrl)
urlTemp.append(word)
urlTemp.append(str(page))
urlTemp.append('')
url = '/'.join(urlTemp)
urls.append(url)
return urls
def getProxyList(self, urls):
proxyList = []
item = Item()
for url in urls:
print(url)
path = r"F:\chromedriver.exe"
browser = webdriver.Chrome(executable_path=path)
browser.get(url)
browser.implicitly_wait(5)
elements = browser.find_elements_by_xpath('//tbody/tr')
for element in elements:
item.ip = element.find_element_by_xpath('./td[1]').text
print(item.ip)
item.port = element.find_element_by_xpath('./td[2]').text
item.anonymous = element.find_element_by_xpath('./td[3]').text
item.protocol = element.find_element_by_xpath('./td[4]').text
item.local = element.find_element_by_xpath('./td[5]').text
item.speed = element.find_element_by_xpath('./td[6]').text
item.uptime = element.find_element_by_xpath('./td[7]').text
proxyList.append(item)
browser.quit()
self.saveFile( proxyList)
def saveFile(self, proxyList):
with codecs.open('proxy.txt', 'w', 'utf-8') as fp:
for item in proxyList:
fp.write('%s \t' %item.ip)
fp.write('%s \t' %item.port)
fp.write('%s \t' %item.anonymous)
fp.write('%s \t' %item.protocol)
fp.write('%s \t' %item.local)
fp.write('%s \t' %item.speed)
fp.write('%s \r\n' %item.uptime)
if __name__ == '__main__':
GP = GetProxy()
运行结果:
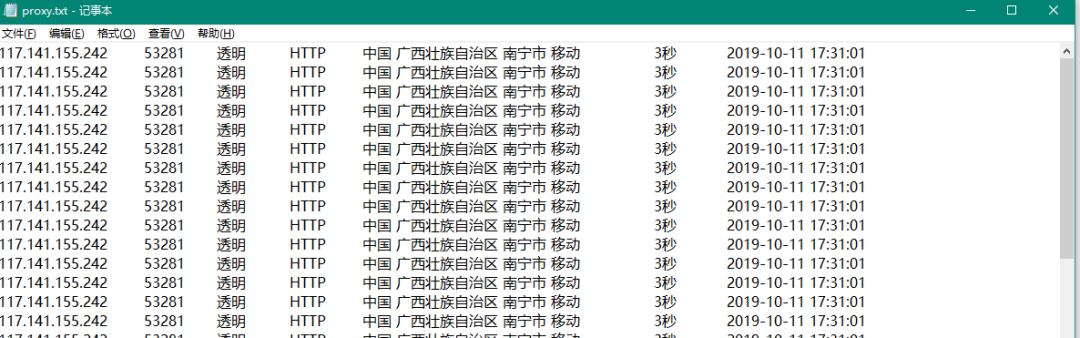
介于大家已经学了这么长时间的爬虫了,我这里就不做讲解了,大家看看。如果有疑问请加群。加入方式:扫描下方的微信二维码,添加微信好友,之后统一邀请你加入学习群。添加好友时一定要备注:爬虫。 今天晚上8点半,群里会有关于爬虫的直播,大家也可以一起过来听一听~

?长按识别,添加王老湿微信
(完)

?关注“Python与人工智能社区”
王老湿目前建立了Python、爬虫、数据分析、机器学习、AI实战、自然语言处理、计算机视觉、推荐系统等方向的读者交流群,大家可以添加王老湿的微信进行加群
近期专栏推荐 (点击下方标题即可跳转)
1.
2.
3.
4.
点下「在看」,给文章盖个戳吧!?

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









