




 Apache Flume 是一个分布式、高可用的海量日志采集系统,支持从多种数据源聚合数据到目标存储。其核心组件包括 Source、Channel 和 Sink,通过事件(Event)进行数据传输。Flume 提供了多种数据源和输出方式,如 console、RPC、text、syslog 和 exec 等,常见的数据接收方是 Kafka 和 HDFS。Flume 的优势在于其可扩展性、可靠性及灵活性,适用于大部分数据采集场景。
Apache Flume 是一个分布式、高可用的海量日志采集系统,支持从多种数据源聚合数据到目标存储。其核心组件包括 Source、Channel 和 Sink,通过事件(Event)进行数据传输。Flume 提供了多种数据源和输出方式,如 console、RPC、text、syslog 和 exec 等,常见的数据接收方是 Kafka 和 HDFS。Flume 的优势在于其可扩展性、可靠性及灵活性,适用于大部分数据采集场景。
1、数据收集工具/系统产生背景
Hadoop 业务的整体开发流程:
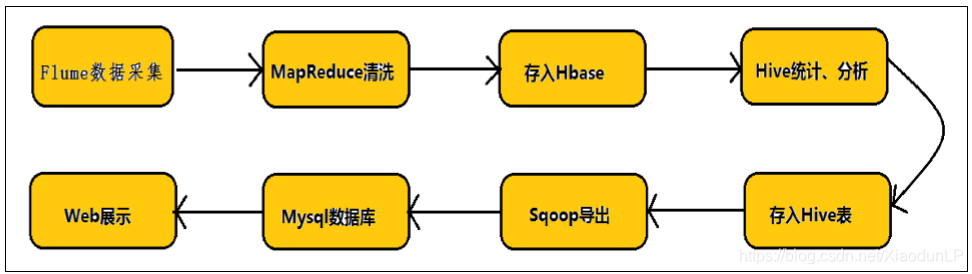
任何完整的大数据平台,一般都会包括以下的基本处理过程:
数据采集 -- 数据 ETL -- 数据存储 -- 数据计算/分析 -- 数据展现
其中,数据采集是所有数据系统必不可少的,随着大数据越来越被重视,数据采集的挑战也 变的尤为突出。这其中包括:
数据源多种多样
数据量大,变化快
如何保证数据采集的可靠性的性能
如何避免重复数据
如何保证数据的质量
我们今天就来看看当前可用的一些数据采集的产品,重点关注一些它们是如何做到高可靠, 高性能和高扩展。
总结: 数据的来源大体上包括: 1、业务数据 2、爬虫爬取的网络公开数据 3、购买数据 4、自行采集手机的日志数据
2、专业的数据收集工具
2.1、Chukwa
Apache Chukwa 是 Apache 旗下另一个开源的数据收集平台,它远没有其他几个有名。Chukwa 基于 Hadoop 的 HDFS 和 MapReduce 来构建(显而易见,它用 Java 来实现),提供扩展性和 可靠性。Chukwa 同时提供对数据的展示,分析和监视。很奇怪的是它的上一次 Github 的更 新事 7 年前。可见该项目应该已经不活跃了。 官网:http://chukwa.apache.org/
2.2、Scribe
Scribe 是 Facebook 开源的日志收集系统,在 Facebook 内部已经得到的应用。它能够从各种 日志源上收集日志,存储到一个中央存储系统(可以是 NFS,HDFS,或者其他分布式文件系 统等)上,以便于进行集中统计分析处理。 官网:https://www.scribesoft.com/
2.3、Fluentd
Fluentd 是另一个开源的数据收集框架。Fluentd 使用 C/Ruby 开发,使用 JSON 文件来统一日 志数据。它的可插拔架构,支持各种不同种类和格式的数据源和数据输出。最后它也同时提 供了高可靠和很好的扩展性。 官网:https://www.fluentd.org/
2.4、Logstash
Logstash 是著名的开源数据栈 ELK(ElasticSearch,Logstash,Kibana)中的那个 L。几乎在大 部分的情况下 ELK 作为一个栈是被同时使用的。所有当你的数据系统使用 ElasticSearch 的情 况下,Logstash 是首选。Logstash 用 JRuby 开发,所以运行时依赖 JVM。 官网:https://www.elastic.co/cn/products/logstash
2.5、
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2429
2429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









